端到端增量学习:深度神经网络的遗忘挑战与解决方案
153 浏览量
更新于2024-06-20
收藏 808KB PDF 举报
"端到端增量学习的解决方案探讨了如何在深度学习模型中解决灾难性遗忘问题,尤其是在不断增加新类别时。文章由弗朗西斯科·M等作者提出,他们来自计算机体系结构系和相关研究机构。文章指出,传统的深度学习模型在训练新类别时需要整个数据集,导致旧类别的性能下降。为了解决这个问题,作者提出了一个端到端的增量学习方法,该方法使用新数据和少量旧类别的样本来更新模型,同时保持旧知识的保留。这种方法通过蒸馏损失和交叉熵损失结合,实现了在不损害旧类别性能的同时学习新类别。在CIFAR-100和ImageNet数据集上的评估显示了先进的性能。"
增量学习是一种机器学习策略,允许模型在接收新数据时逐步更新,而不必重新训练整个模型。在深度学习中,增量学习面临的主要挑战是“灾难性遗忘”,即模型在学习新信息时会忘记之前学到的内容。文章中提到的端到端增量学习方法旨在克服这一难题。
蒸馏损失是用于知识转移的技术,它能帮助新模型从旧模型中学习关键特征,从而防止旧类别的信息丢失。这种损失函数结合了教师网络(通常是预先训练好的模型)的输出,引导新模型保持对旧类别的理解。
文章讨论的另一个核心点是图像分类,这是一个典型的增量学习应用场景。例如,人脸识别系统需要不断学习新的面孔,同时保持对已知面孔的识别能力。传统的深度学习模型在这个场景下表现不佳,因为它们需要所有历史数据进行训练,而增量学习方法则试图仅用新数据和部分旧数据来更新模型。
作者强调,他们的方法是真正的端到端增量学习,因为它可以从数据流中接受训练,并按任意顺序处理新类。这与一些现有方法不同,那些方法可能无法保证在不牺牲旧类别性能的情况下有效地学习新类别。
这篇文章提出的端到端增量学习解决方案对于应对不断变化的分类任务,特别是在有限的存储和计算资源条件下,提供了一个有前景的途径。通过这种方式,深度学习模型能够更有效地适应新信息,同时保持对早期学习内容的记忆,这对于构建动态和自适应的机器学习系统至关重要。
4
Castro等人
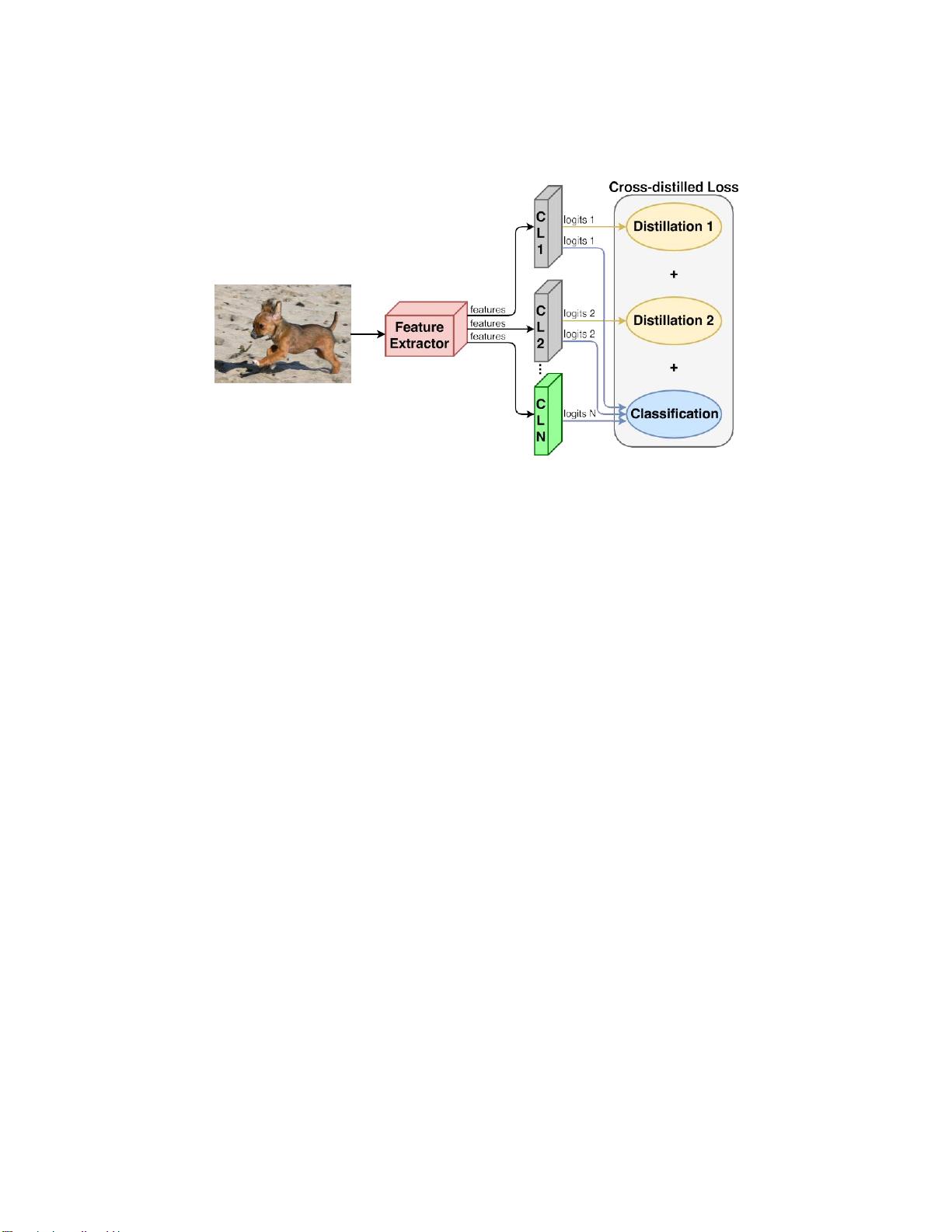
图1:我们的增量模型。给定输入图像,特征提取器产生 由
分类层
(CLi块)
使用以生成一组logit
的
一组特征。灰色
分类层
包含旧类,并且它们的logit用于
蒸馏和分类。绿色
分类层
(CLN块)包含新的类,其logits只涉及分类。(最好
是彩色的)。
通过每参数正则化选择性地降低学习速率[14]。 Xiao
等
[37]也遵循相关方案,并随着观察到新类而递增地增长其树结构模型。所有这
些方法的主要缺点是参数数量的快速增加,其随着权重、任务和新层的总数而
增长。相比之下,我们提出的模型对原始网络的大小变化最小,如第2节所述。
3.第三章。
Rebufi
等人
[23]提出iCaRL,一种增量学习方法,其中学习分类器和数据表示
的任务被解耦。iCaRL使用传统的NMC对测试样品进行分类,即,它维护包含
旧和新数据样本的辅助集数据表示模型是一个标准的神经网络,当新的样本可
用时,使用蒸馏和分类损失的组合进行更新[12,16]。虽然我们的方法也使用
了一些旧类的样本作为代表性记忆组件中的范例(参见秒3.1),它通过以端到
端的方式联合学习分类器和特征来克服先前工作的局限性。此外,如图所示,
在SEC。6、第7,我们的新模型优于[23]。
3
我们的模型
我们的端到端方法使用了一个深度网络,该网络使用交叉提取的损失函数进行
训练,即,交叉熵和蒸馏损失。该网络可以基于为分类设计的大多数深度模型
的架构,因为我们的方法不需要任何特定的属性。用于分类的典型架构可以是
剩余15页未读,继续阅读
2021-02-17 上传
2024-05-22 上传
2021-05-26 上传
2021-09-21 上传
2022-07-02 上传
2021-09-21 上传
2021-09-30 上传
2024-02-23 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
