Apache Kafka:分布式消息系统的详细介绍
需积分: 10 82 浏览量
更新于2024-08-11
收藏 1.65MB DOCX 举报
"本文档介绍了Kafka的基本概念,包括消息系统的两种主要模式——点对点和发布-订阅,以及Kafka作为一个分布式、高可靠性的消息系统的特点和应用场景。"
Kafka是一个高性能、分布式的消息中间件,它最初由LinkedIn开发,后来成为Apache软件基金会的顶级项目。Kafka的主要设计目标是提供高吞吐量、低延迟的数据传输能力,以满足大规模实时数据处理的需求。
在了解Kafka之前,我们需要理解消息系统的基本概念。消息系统是连接不同应用程序的桥梁,它允许数据在这些应用程序之间异步传输,从而解耦了发送和接收数据的过程。消息系统有两种主要的工作模式:点对点和发布-订阅。
1. 点对点消息系统:在这种模式中,消息被存储在一个队列中,每个消息只能被一个消费者消费一次,消费后即从队列中移除。这种模式适用于单个任务处理,例如订单处理,每个订单由一个处理器独立处理。
2. 发布-订阅消息系统:与点对点模式不同,发布-订阅模式下,消息存储在主题(Topic)中,一个主题可以有多个订阅者,每个订阅者都可以接收到该主题的所有消息。这种模式适合广播式的信息传播,例如新闻推送或者用户定制的服务。
Kafka就是一种基于发布-订阅模式的消息系统,它的特性使其在大数据领域表现出色:
- 分布式:Kafka集群可以跨多台服务器分布,提供高可用性和容错性。
- 可靠性:Kafka通过分区和复制策略确保数据的持久性和一致性,即使部分节点故障,数据也不会丢失。
- 可扩展性:Kafka支持动态扩展,可以在不影响服务的情况下增加或减少节点。
- 耐用性:消息被存储在磁盘上,并且在集群内部进行复制,确保数据的持久性。
- 高性能:Kafka具有高吞吐量,无论数据量多大,都能保持稳定的性能。
- 稳定性:Kafka保证了零停机和零数据丢失,提供可靠的实时数据流处理。
Kafka在实际应用中有多种用途:
- 指标监控:收集和聚合来自分布式系统的监控数据,形成中心化的运营指标流。
- 日志聚合:整合不同服务的日志,统一格式并分发给日志分析系统。
- 流处理:与Apache Storm和Spark Streaming等实时处理框架集成,实现数据的实时分析和处理。
- 数据管道:作为数据集成的工具,将数据从源头传输到目的地,如数据库、数据仓库或分析系统。
Kafka的使用不仅限于以上场景,随着大数据和实时分析的需求增长,Kafka在现代企业架构中扮演着越来越重要的角色。其强大的功能和灵活的设计使得它成为构建复杂、大规模数据处理系统的基础组件之一。
递,并在出现机器故障时提供对容错的保证。.它具有处理大量不同消费者的能力。.
非常快,执行 百万写$秒。. 将所有数据保存到磁盘,这实质上意味着所有写入都
会进入操作系统%&的页面缓存。.这使得将数据从页面缓存传输到网络套接字非常有效。
对于大数据,我们要考虑的问题有很多,首先海量数据如何收集(如."'),然
后对于收集到的数据如何存储(典型的分布式文件系统.("、分布式数据库.
(、)*+数据库.%#),其次存储的数据不是存起来就没事了,要通过计算从中获
取有用的信息,这就涉及到计算模型(典型的离线计算.&%#、流式实时计算
、),或者要从数据中挖掘信息,还需要相应的机器学习算法。在这些之上,
还有一些各种各样的查询分析数据的工具(如.(,、-!等)。除此之外,要构建分布式
应用还需要一些工具,比如分布式协调服务.等等。
.
3、相关术语
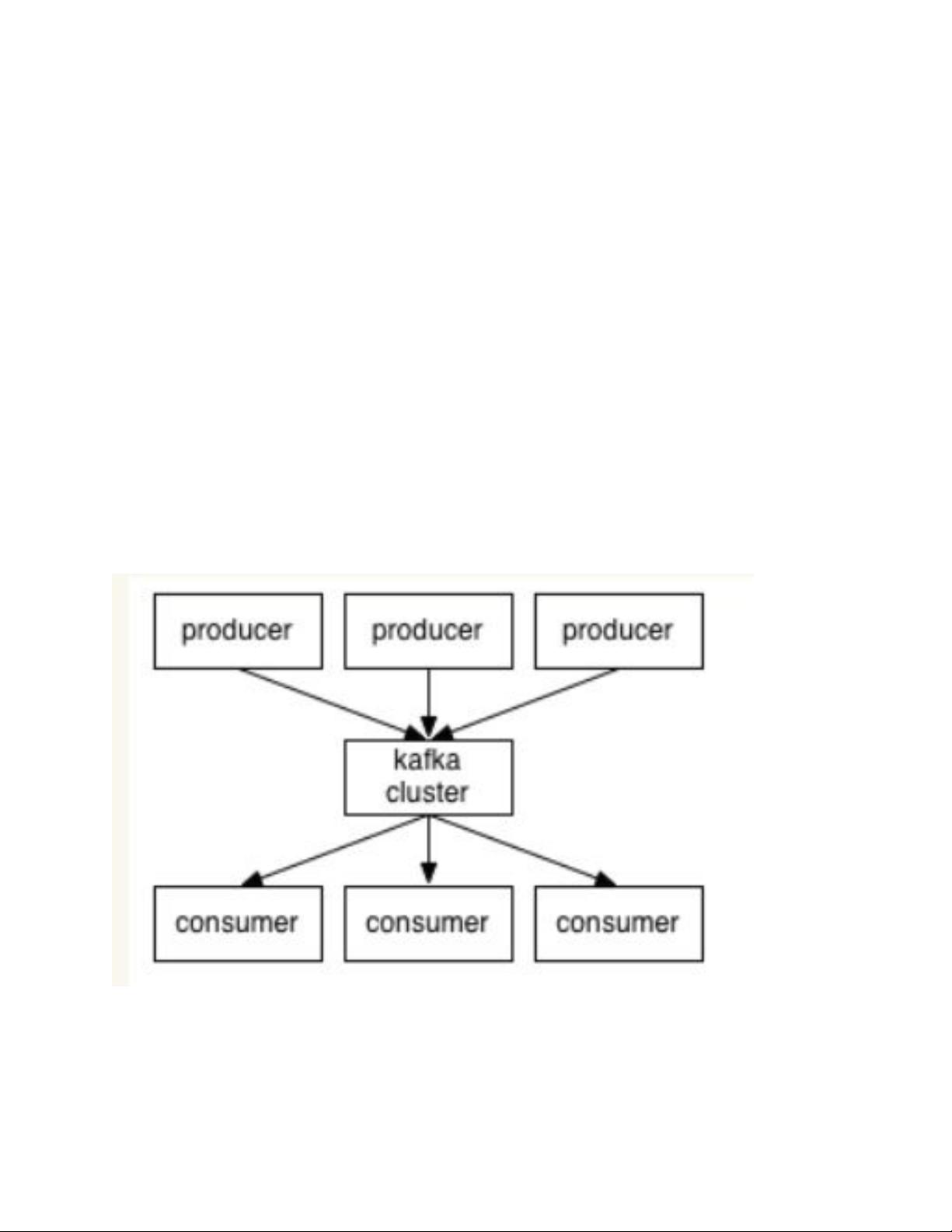
3.1 生产者和消费者(producer 和 consumer)
消息的发送者叫.-#,消息的使用者和接受者是./ ,生产者将数据保存到.集
群中,消费者从中获取消息进行业务的处理。
3.2 broker(代理人):
集群中有很多台.,,其中每一台.,都可以存储消息,将每一台.,称为一个.
实例,也叫做.。
剩余13页未读,继续阅读
2019-05-28 上传
2021-09-20 上传
2020-09-13 上传
2019-09-06 上传
2020-02-24 上传
2019-11-19 上传
2021-04-22 上传

猿小许
- 粉丝: 1052
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







