Python爬虫入门:使用lxml库和XPath解析网页
版权申诉
7 浏览量
更新于2024-07-08
收藏 800KB PDF 举报
XPath爬虫技术详解
XPath是爬虫开发中一种常用的技术,用于定位和提取网页中的特定元素和节点信息。本文将通过lxml库与XPath的搭配使用,详细介绍如何利用XPath爬取网页内容。
LXML库的介绍
------------
lxml库是一个高性能的Python HTML/XML 解析器,主要功能是解析和提取HTML/XML数据。lxml库由C语言实现,是一种高效的解析器。
LXML库的安装
-------------
要使用lxml库,需要先安装lxml库,可以使用pip进行安装:
```
pip install lxml
```
LXML库的使用
-------------
lxml库可以解析传入的任何一段XML或者HTML片段,当然前提是你的XML或者HTML片段没有语法错误。下面是一个简单的示例:
```
# lxml_test.py
from lxml import etree
text = """
<div id="content_views" class="htmledit_views">
<p style="text-align:center;"><strong>全网ID名:<b>码农飞哥</b></strong></p>
<p style="text-align:right;"><strong>扫码加入技术交流群!</strong></span></p>
<p style="text-align:right;"><img src="https://img-blog.csdnimg.cn/5df64755954146a69087352b41640653.png"/></p>
<div style="text-align:left;">个人微信号<img src="https://img-blog.csdnimg.cn/09bddad423ad4bbb89200078c1892b1e.png"/></div>
</div>
"""
# 利用etree.HTML将字符串解析成HTML文档
html = etree.HTML(text)
print(html)
```
XPath语法
----------
XPath是一种查询语言,用于定位和提取XML文档中的特定元素和节点信息。XPath语法主要包括以下几个部分:
* 节点类型:包括元素节点、属性节点、文本节点、注释节点等。
* 路径表达式:用于定位特定元素和节点信息,例如 `/html/body/div/p`。
*谓词:用于筛选特定元素和节点信息,例如 `[position()=1]`。
* 函数:用于执行特定操作,例如 `contains()`。
XPath与LXML库的搭配使用
-------------------------
通过lxml库,我们可以将XPath语法应用于爬虫开发中,快速定位和提取网页中的特定元素和节点信息。例如:
```
# 使用lxml库解析HTML文档
html = etree.HTML(text)
# 使用XPath语法定位特定元素和节点信息
elements = html.xpath('//p[@style="text-align:right;"]')
for element in elements:
print(element.text)
```
总结
----
本文详细介绍了lxml库与XPath的搭配使用,用于快速定位和提取网页中的特定元素和节点信息。通过lxml库和XPath语法,我们可以快速开发爬虫程序,爬取网页中的有价值信息。
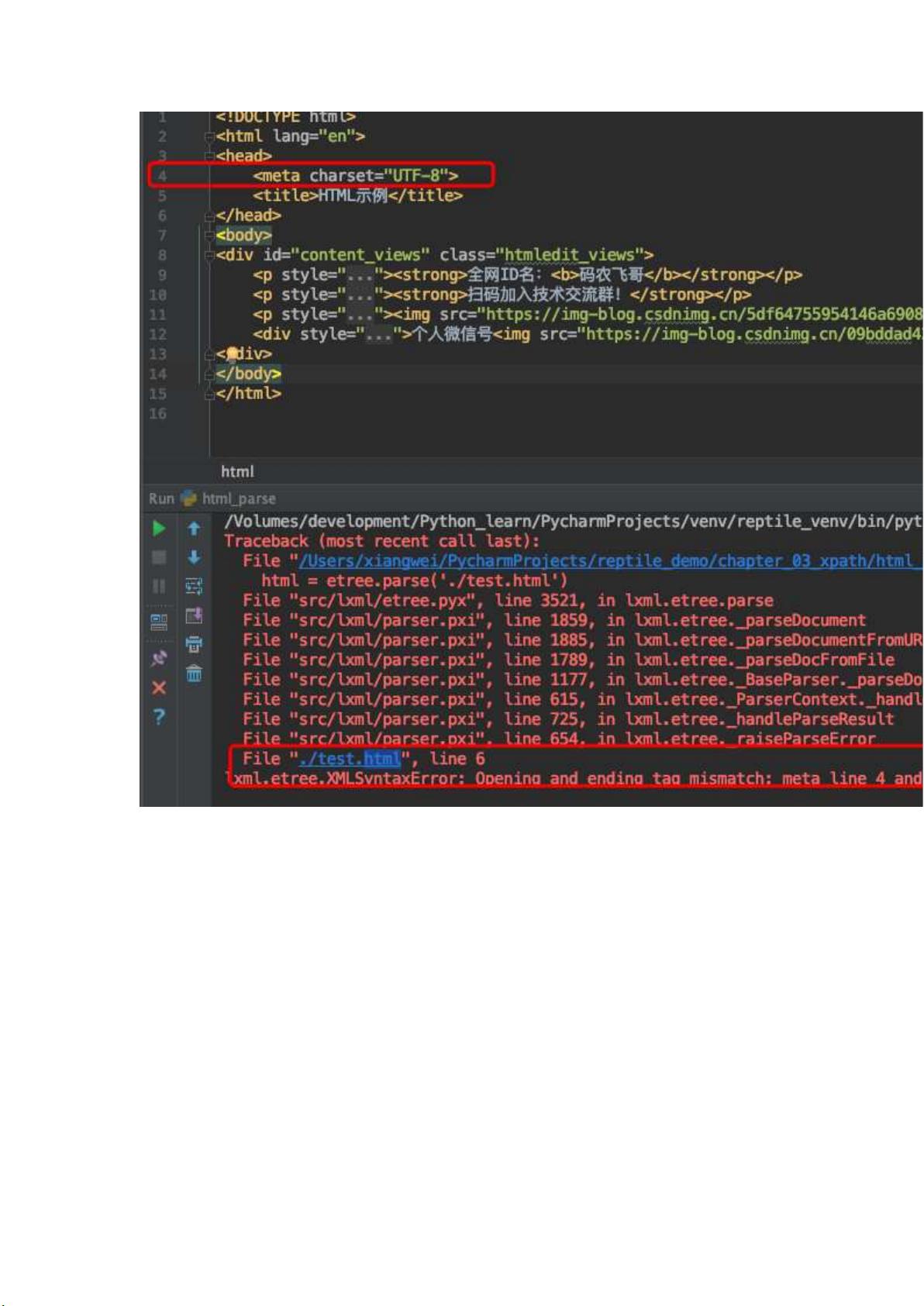
针对 HTML 文件需要通过 HTMLParser 方法设置 HTML 解析器。然后在 parse 方法
指定该解析器,就像下面代码所示的一样。
from lxml import etree
# 定义解析器
html_parser = etree.HTMLParser(encoding='utf-8')
# 读取外部文件 test.html
html = etree.parse('./test.html', parser=html_parser)
result = etree.tostring(html, encoding='utf-8').decode()
print(result)
剩余15页未读,继续阅读
3602 浏览量
650 浏览量
594 浏览量
2024-10-17 上传
323 浏览量
2024-06-18 上传
2024-02-20 上传
2024-06-14 上传
130 浏览量

一诺网络技术
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android dex2.jar:简单易用的反编译工具
- 六自由度对接平台:高效拼装雷达天线的设计装置
- Aspose.Cells组件使用指南:生成与编辑Excel文件
- 北大研一分布式环境下多表查询优化
- Cocos2d-x Lua基础开发教程
- 探索Svelte框架:非官方UIkit组件库
- 易语言开发特训小游戏教程与源码解析
- 深入解析Java实现的Zookeeper1核心机制
- 深度旋转动画实现硬币反转效果示例
- 多功能网页在线编辑器:上传图片视频轻松搞定
- 微动定位平台技术改进:行程范围调整解决方案
- Win32开发的迷你音乐播放器实现基本操作
- 机器学习实习生的深度学习技术学习之旅
- BIOS魔改工具助力B150/B250/H110平台支持8/9代CPU
- App-Kontomierz:智能账单管理工具应用
- 小米3刷机攻略:卡刷与线刷全面教程
