深度学习图像分类:技巧与应用
需积分: 27 21 浏览量
更新于2024-07-16
收藏 14.91MB PDF 举报
本资源是一份关于"Classification with Deep Learning"的PDF文档,主要探讨了深度学习在图像分类领域的应用以及一些高级技巧。作者是亚马逊AWS的Tong He,日期为2018年12月17日,由AWS和其关联方所有,版权受到保护。
首先,文档介绍了什么是分类任务,即识别图像中的关键信息,包括数字识别、汽车模型检测和面部识别等实际应用场景。这些应用展示了深度学习在不同领域的重要作用。
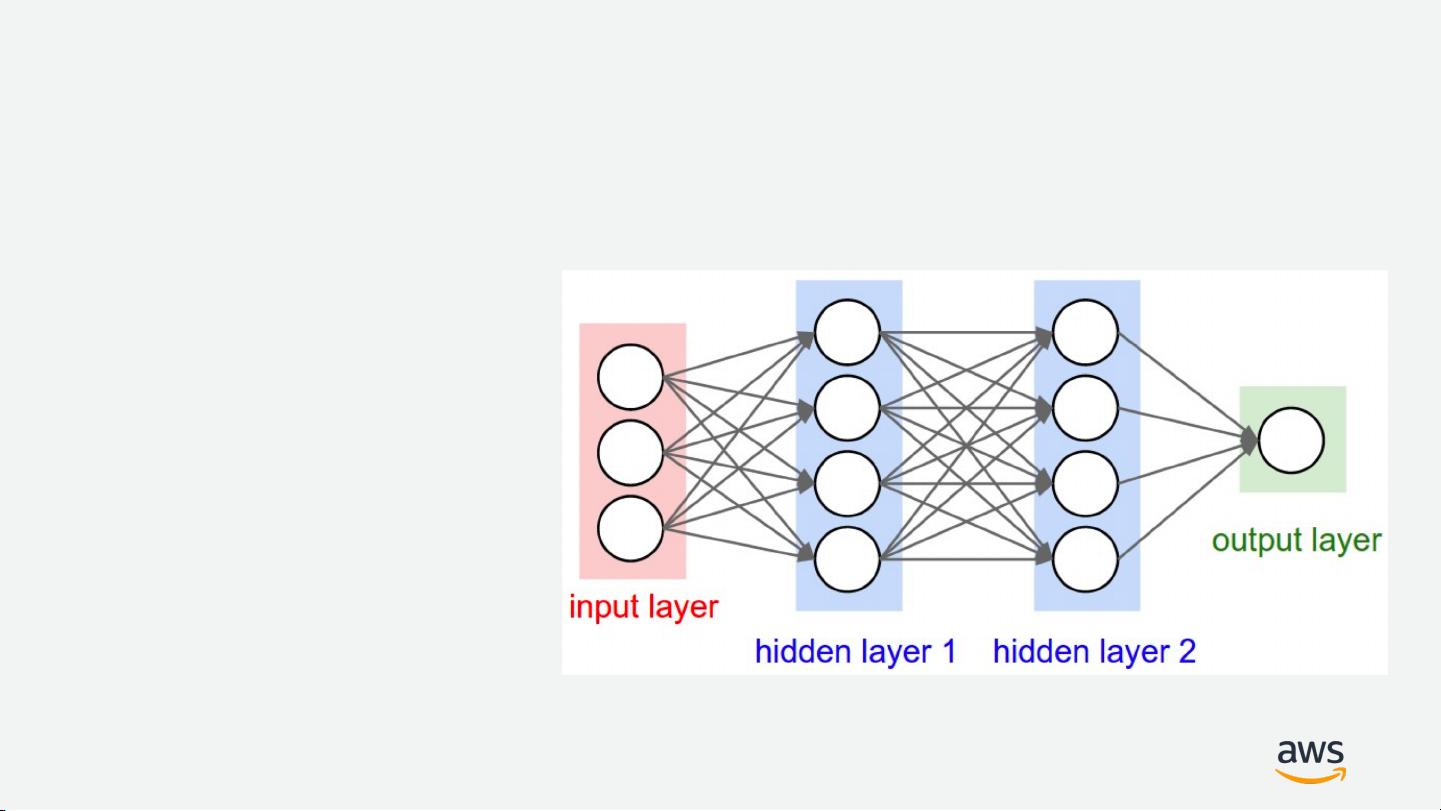
接下来,文档重点介绍了使用深度学习进行图像分类的方法,以经典的数据集MNIST为例。MNIST是一个28x28像素的灰度图像数据集,包含50,000个训练样本和10,000个测试样本,常被用于初学者入门深度学习的"Hello World"项目。在这个过程中,作者提到了两种基本的深度学习层:全连接层和卷积层。
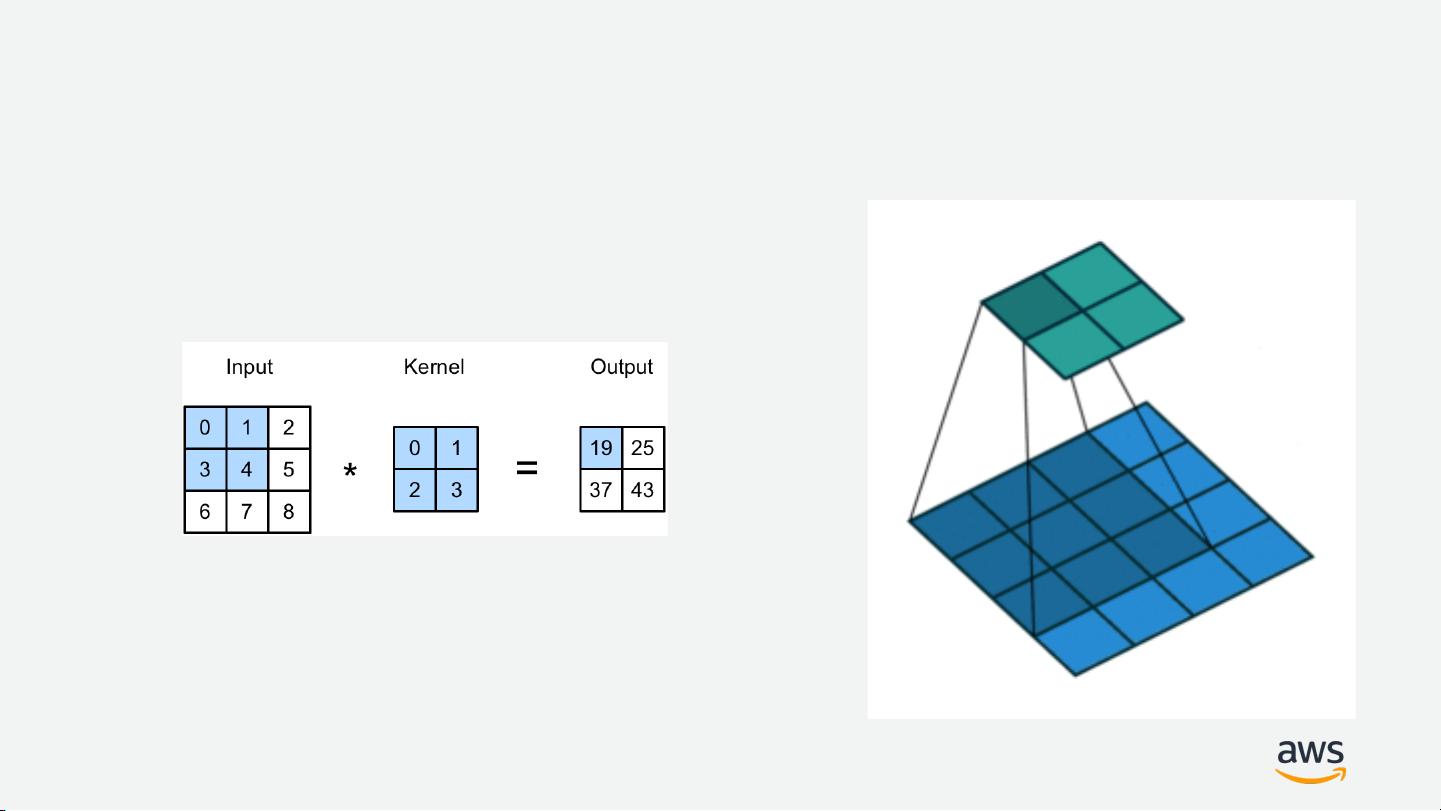
全连接层虽然功能强大,但缺点是昂贵且对输入数据的空间结构不敏感,这意味着它不适合处理图像这样的二维数据。相比之下,卷积层通过局部连接和共享权重的方式,有效地解决了这个问题,能够在保持参数数量相对较少的情况下捕捉图像特征,显著降低了计算复杂度,提高了模型的性能。
此外,文档还介绍了几个高级技巧,如Label smoothing(标签平滑),这是一种减少过拟合的方法,通过在训练过程中稍微扰动真实标签,使模型学习到更平滑的概率分布;Learning rate schedule(学习率调度),通过调整学习率随时间变化,有助于模型在训练的不同阶段优化性能;Mix-Up,一种数据增强技术,通过随机组合两个样本及其标签来创建新的合成样本,从而提高模型泛化能力;最后,Knowledge Distillation(知识蒸馏)是一种转移学习策略,将一个大型预训练模型的软标签知识传授给小型或效率更低的模型,以提升后者的性能。
这份文档深入浅出地讲解了深度学习在图像分类中的基础方法和实用技巧,对于想要进一步理解并应用深度学习进行图像分类的读者来说,具有很高的参考价值。
© 2018, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Classification with Deep Learning
Fully-connected Layer
• Expensive
• 2D insensitive
剩余36页未读,继续阅读
2024-07-20 上传
2024-07-24 上传
2024-07-23 上传
2023-04-03 上传
2023-11-26 上传
2023-03-25 上传
2023-04-20 上传
2023-06-09 上传
2023-06-08 上传

逸_
- 粉丝: 30
- 资源: 33
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
