声纹识别技术与开源工具探索:2021年厦门大学智能语音实验室进展
需积分: 5 61 浏览量
更新于2024-07-09
收藏 6.34MB PDF 举报
"这篇资源是关于声纹识别的最新研究现状和开源工具的分享,由厦门大学智能语音实验室的洪青阳及其团队在2021年7月发布。"
声纹识别是一种生物识别技术,它基于每个人的嗓音特征来辨识个体身份。随着智能设备的普及,如智能音箱、电视和手机,声纹识别被广泛应用于安全验证和个性化服务,如账号登录和智能客服。这项技术主要包括说话人鉴别(Speaker Identification)、说话人确认(Speaker Verification)以及说话人分割聚类(Speaker Diarization)。根据应用场景的不同,有多种任务类型,如1:N的说话人鉴别和1:1的说话人确认,以及对抗欺骗攻击。
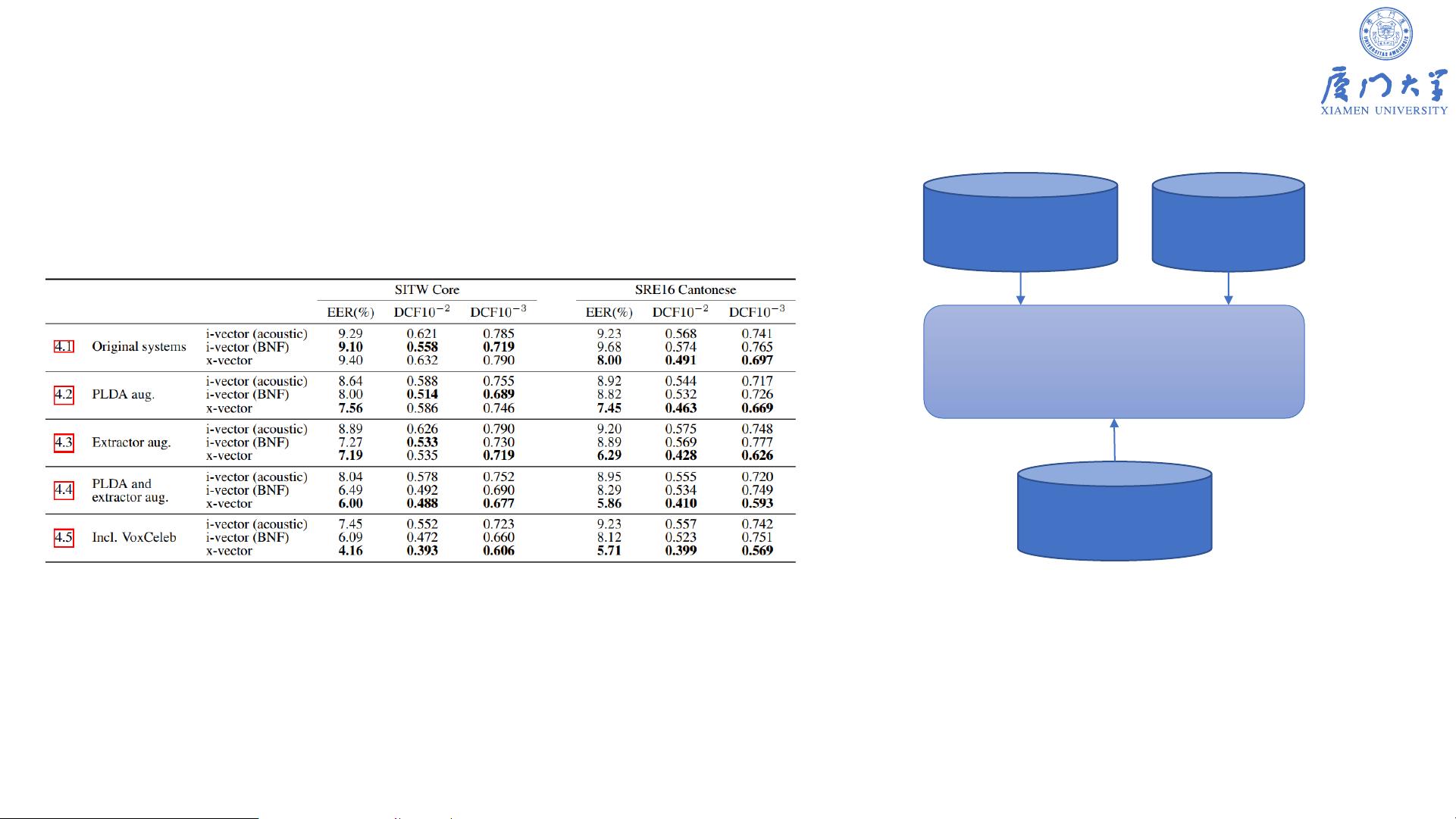
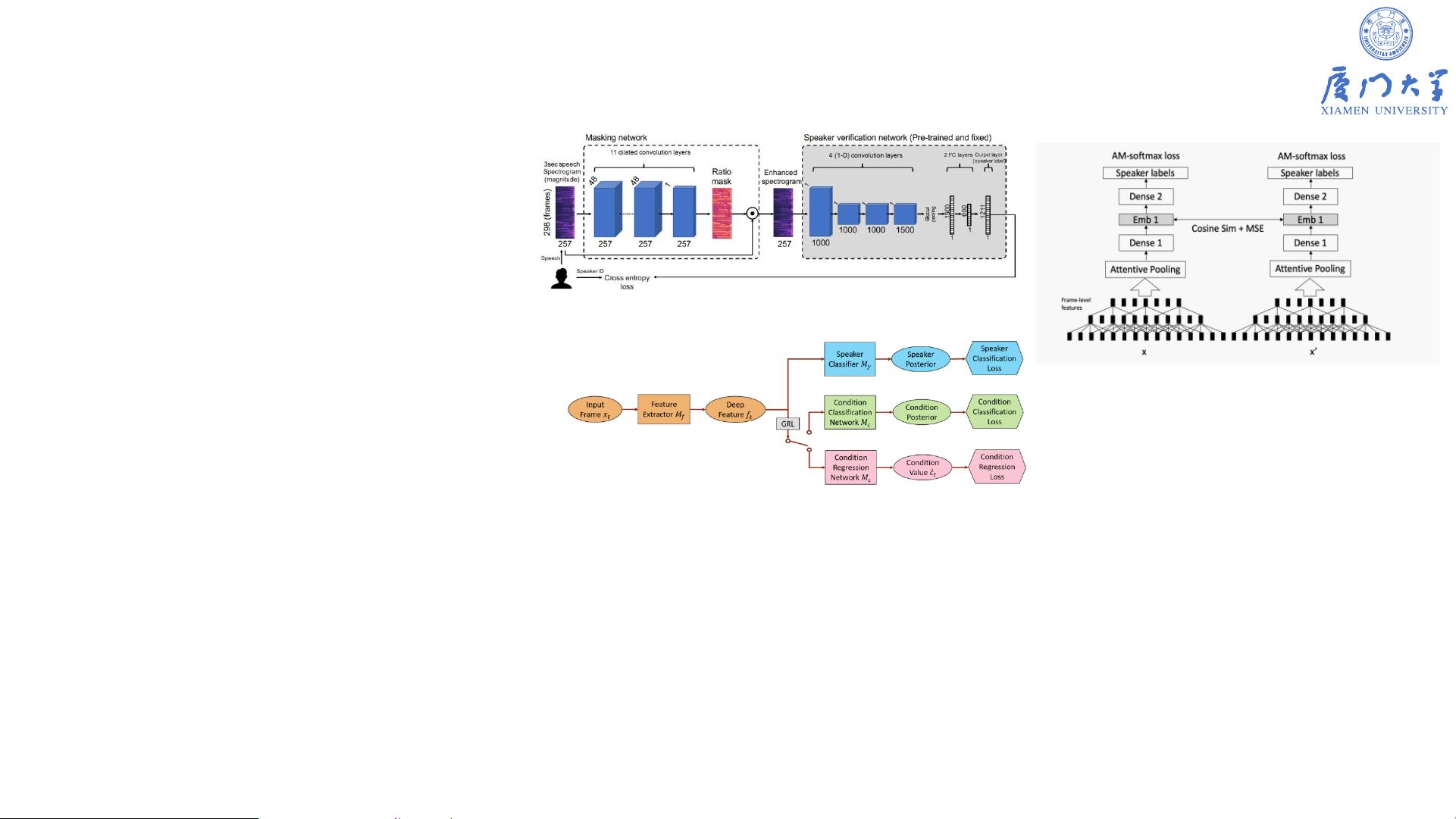
声纹识别的发展历程经历了模板匹配、GMM-UBM、GMM-SVM、HMM、DTW、VQ、JFA、DNN i-vector、d-vector到x-vector等模型的演进。特征提取从早期的语音、波形、语谱图、倒谱、LPC、LPCC到MFCC、DeepEmbedding和PLP等,直至近年来深度学习的广泛应用,使得声纹识别的性能得到了显著提升。
x-vector模型是当前的一个关键模型,它通过帧级别的处理和StatisticsPooling层来学习语音的全局统计信息,再通过段级别进一步提取信息。这种模型结构能有效地处理时序语音数据,提高识别准确率。
声纹识别的关键技术还包括合适的损失函数选择和后端分类器设计。通常,Cosine相似度或PLDA等方法用于计算声纹的相似度,而模型训练则依赖大量实际应用数据。随着技术的进步,声纹识别已经在刑事侦查、智能客服和智能家居等领域展现出广阔的应用前景,并且评价指标如Top-N命中率、等错误率(EER)和分离错误率(DER)被用来衡量系统的性能。
此外,文中提到的开源工具可能为研究人员和开发者提供了实验和应用这些技术的平台,有助于推动声纹识别领域的进一步发展。然而,具体内容并未详述这些开源工具的名称和特性,这部分信息需要进一步探索。

2023-02-22 上传
2024-08-30 上传
2024-11-03 上传
2024-01-07 上传
2021-09-29 上传

weixin_44220177
- 粉丝: 3
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
