Hadoop单机与伪分布式安装指南:从用户创建到配置详解
需积分: 0 138 浏览量
更新于2024-06-18
收藏 11.75MB PDF 举报
本篇文档详细介绍了如何在Linux环境下进行Hadoop的安装和配置过程,主要包括以下几个步骤:
1. **创建Hadoop用户**: 首先,用户需要创建一个专门的Hadoop用户,并为其设置初始密码。接着,赋予这个用户必要的权限以便后续操作。
2. **更新软件和安装Vim编辑器**: 切换到Hadoop用户后,更新系统的包管理器apt,这有助于确保所有依赖项都是最新的。同时,安装Vim编辑器,这是一个常用的文本编辑器,便于Hadoop的配置文件编辑。
3. **安装SSH和配置无密码登录**: 安装SSH服务,确保安全的远程访问。配置SSH无密码登录,使得在后续的集群管理中更为便捷。
4. **安装Java**: Java是Hadoop运行的基础,文档指导用户下载并移动JDK安装包到特定文件夹,解压后配置环境变量,确保Java路径被系统识别。
5. **单机Hadoop安装**:
- 检查文件结构和权限
- 解压安装包至指定位置,并修改目录名和权限
- 验证安装,包括检查版本信息和执行测试,确保Hadoop在本地环境中能正常运行。
6. **Hadoop伪分布式安装**:
- 修改配置文件,如核心配置文件hadoop-site.xml,以适应伪分布式环境
- 进行相应的配置和初始化
- 启动Hadoop分布式文件系统(HDFS)和MapReduce框架
- 使用浏览器或命令行工具查看Hadoop的状态
- 创建用户目录和input目录,并将本地配置文件上传至分布式文件系统
- 运行示例程序以验证安装和配置是否正确
- 在完成测试后,停止Hadoop服务
通过这些步骤,用户能够全面了解和掌握如何在一个单节点上搭建和配置Hadoop环境,以及如何向分布式环境过渡,为后续的Hadoop开发和大数据处理打下坚实基础。
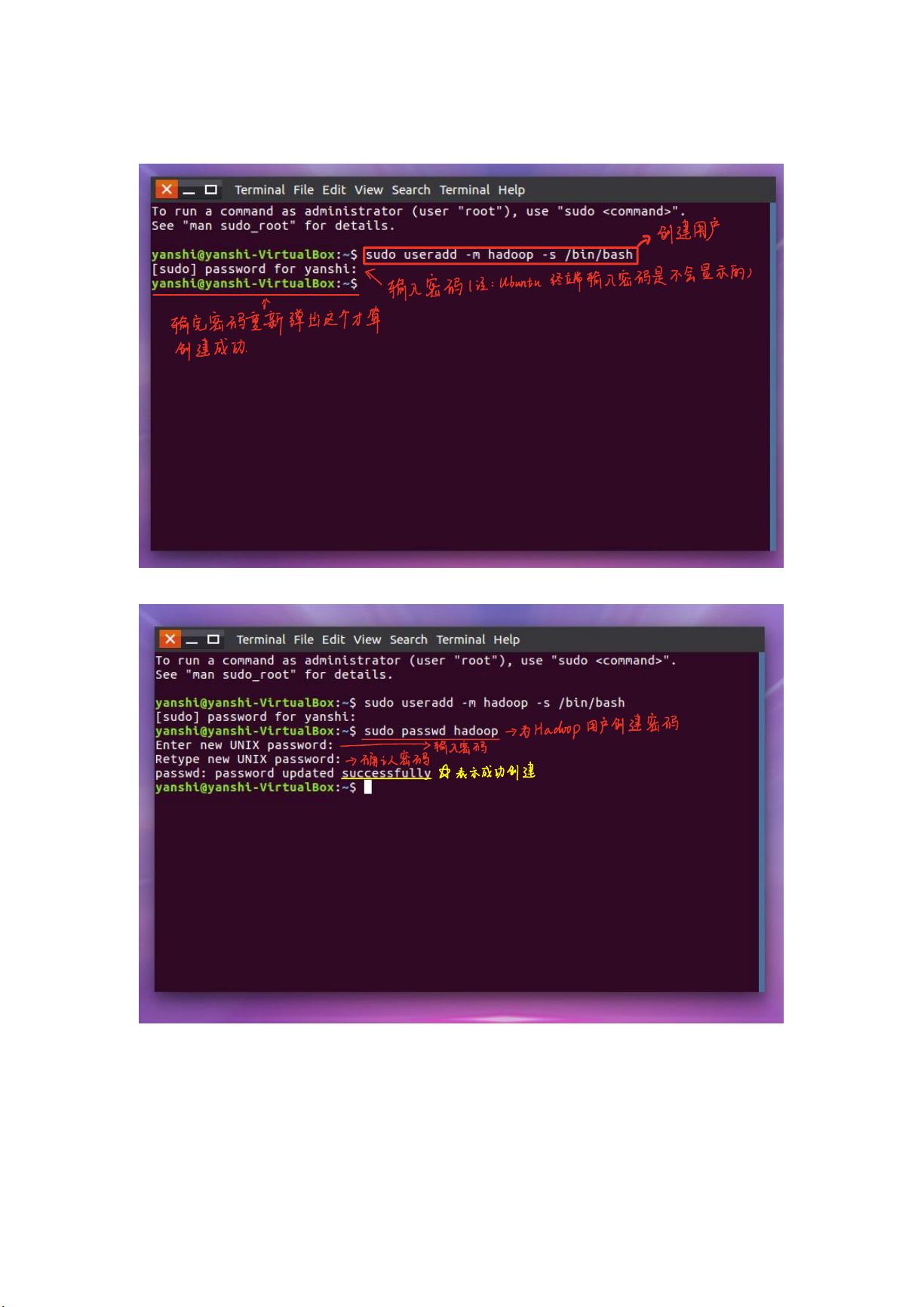
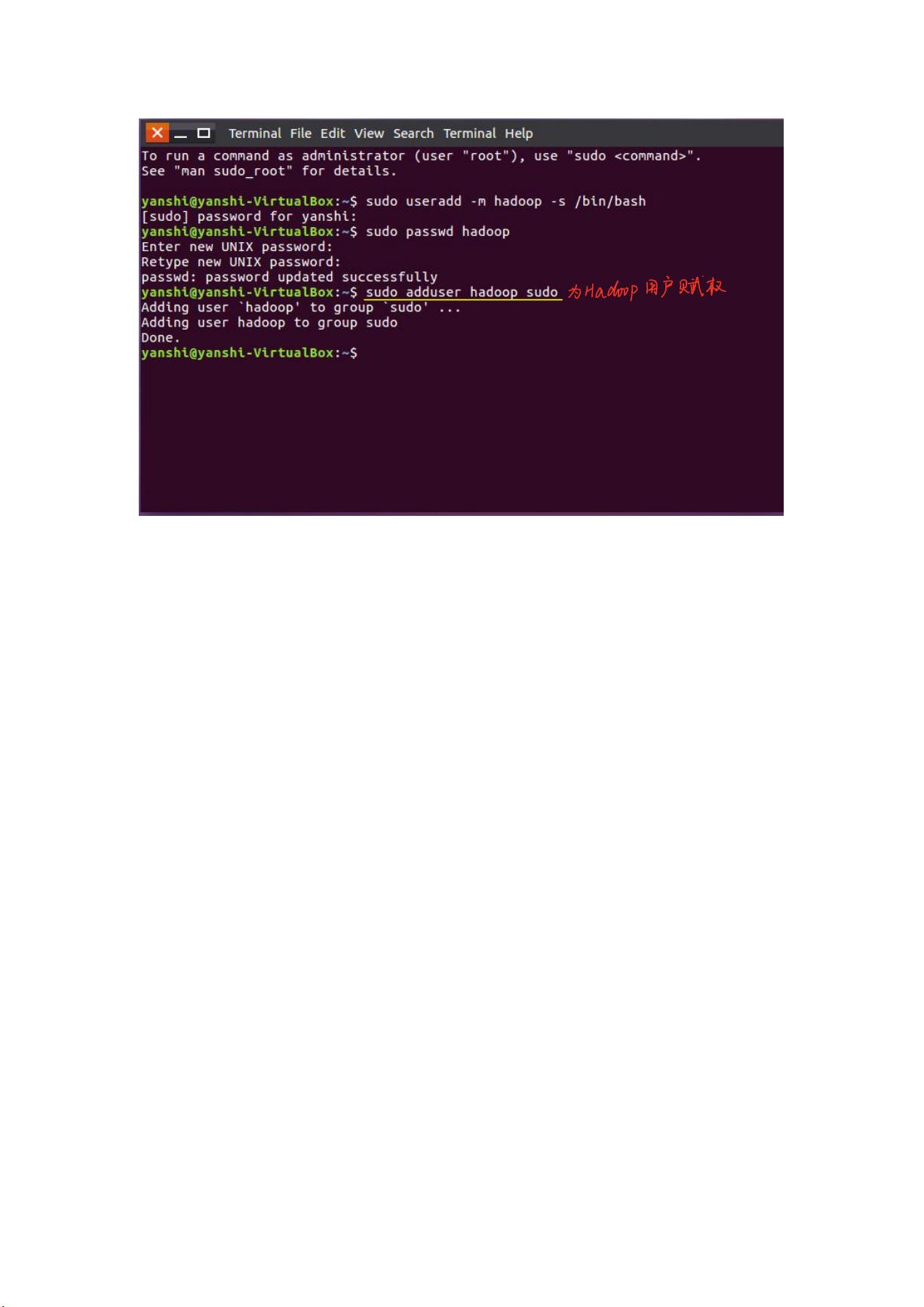
一、创建 Hadoop 用户
1、创建 Hadoop 用户,输入最开始的密码
2、设置 Hadoop 账户密码
3、赋权
剩余30页未读,继续阅读
2021-04-20 上传
2021-11-23 上传
2021-02-03 上传
2013-07-07 上传
2021-11-27 上传
2021-11-23 上传

ZShiJ
- 粉丝: 1w+
- 资源: 55
 我的内容管理
展开
我的内容管理
展开







