30分钟学会正则表达式入门
需积分: 9 26 浏览量
更新于2024-07-23
收藏 356KB PDF 举报
"这篇教程是为初学者设计的正则表达式入门教程,旨在30分钟内让读者理解正则表达式的基本概念并能初步应用。教程内容包括元字符、字符转义、重复、字符类、分枝条件、反义、分组、后向引用、零宽断言、负向零宽断言、注释、贪婪与懒惰、处理选项、平衡组/递归匹配等关键知识点。此外,教程也适用于日常作为正则表达式语法参考手册。作者强调,尽管教程内容详尽,但初次接触者可能无法立即记住所有内容,需要通过实践来逐渐掌握。正则表达式是一种强大的文本处理工具,用于在字符串中寻找符合特定模式的子串,常用于数据验证、搜索替换等场景。"
正则表达式是编程和文本处理领域中的一种强大工具,它允许我们用简洁的模式来匹配、查找、替换或者提取字符串中的特定部分。这篇教程以简洁易懂的方式介绍了正则表达式的基础知识,适合没有任何经验的初学者。
1. **元字符**: 元字符是具有特殊含义的字符,如`.`代表任意单个字符,`^`表示行首,`$`表示行尾,`*`表示前面的元素可以重复0次或多次。
2. **字符转义**: 当需要匹配元字符本身时,需要在前面加上反斜杠`\`进行转义,例如`\.`会匹配实际的句点字符。
3. **重复**: `+`表示前面的元素至少出现一次,`*`表示前面的元素可以出现0次或多次,`?`表示前面的元素出现0次或1次。
4. **字符类**: `[abc]`匹配任何一个在括号内的字符,`[^abc]`则匹配任何不在括号内的字符。
5. **分枝条件**: `(a|b)`匹配`a`或`b`,提供了逻辑选择的功能。
6. **反义**: `\d`代表数字,`\D`则是非数字;`\s`代表空白字符,`\S`代表非空白字符。
7. **分组**: `(pattern)`将`pattern`作为一个分组,可以进行后向引用或嵌套其他规则。
8. **后向引用**: `\1`到`\9`引用前面的分组,用于匹配与之前分组相同的内容。
9. **零宽断言**: `(?=pattern)`是正向前瞻,确保匹配的位置后面紧跟`pattern`;`(?<!pattern)`是负向前瞻,确保匹配位置后面不跟`pattern`。
10. **贪婪与懒惰**: 默认情况下,`*`, `+`, `?`是贪婪的,会尽可能多地匹配字符;加上`?`使其变为懒惰,尽可能少地匹配字符。
11. **处理选项**: 不同的正则引擎可能有特定的选项来改变行为,如`i`忽略大小写,`m`使`^`和`$`匹配每一行的开头和结尾。
12. **平衡组/递归匹配**: 这是一个高级特性,用于处理嵌套结构,如括号的嵌套匹配。
教程鼓励读者通过实践来加深理解和记忆,因为正则表达式的学习往往需要不断的练习。随着熟练度的提高,可以更有效地利用正则表达式解决各种文本处理问题。
这里的 \d 是个新的元字符,匹配 一位数字 (0 ,或 1 ,或 2 ,或 …… )
。
- 不是元字符
,
只匹配它本身 —— 连字符 ( 或者减号,或者中横线,或者随你怎么称呼它 ) 。
为了避免那么多烦人的重复,我们也可以这样写这个表达式: 0\d{2}-\d{8}
。
这
里 \d 后面的 {2} ( {8} ) 的意思是前面 \d 必须连续重复匹配 2 次 (8 次 ) 。
测试正则表达式
其它可用的测试工具 :
•
RegexBuddy
•
Javascript 正则表达式在线测试工具
如果你不觉得正则表达式很难读写的话,要么你是一个天才,要么,你不是地 球
人。正则表达式的语法很令人头疼,即使对经常使用它的人来说也是如此。由于难 于
读写,容易出错,所以找一种工具对正则表达式进行测试是很有必要的。
不同的环境下正则表达式的一些细节是不相同的,本教程介绍的是微软 .Net
Framework 2.0 下正则表达式的行为,所以,我向你介绍一个 .Net 下的工具 Regex
Tester 。首先你确保已经安装了 .Net Framework 2.0 ,然后 下载 Regex Tester 。这是个 绿
色软件,下载完后打开压缩包 , 直接运行 RegexTester.exe 就可以了。
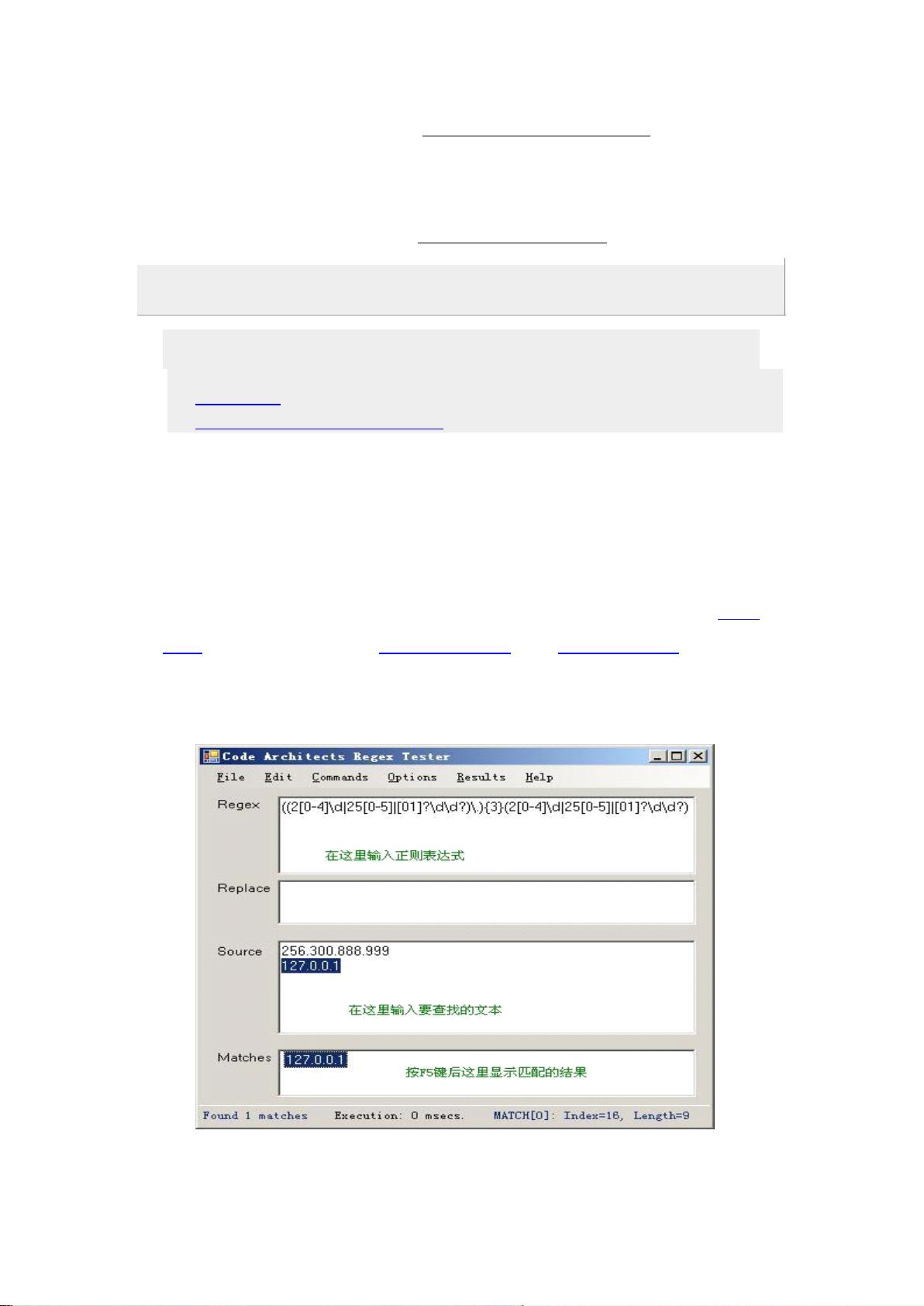
下面是 Regex Tester 运行时的截图:
剩余16页未读,继续阅读
2009-09-17 上传
605 浏览量
点击了解资源详情
181 浏览量
点击了解资源详情
107 浏览量

zhulinniao
- 粉丝: 5082
 我的内容管理
展开
我的内容管理
展开







最新资源
- 利用dlib库实现99.38%精确度的人脸识别技术
- 深入解析AT91 NAND控制器的技术要点
- React Cube Navigation:实现Instagram故事风格的3D立方体导航
- STM32控制ESP8266实现OneNet云MQTT开关控制源代码示例
- 深入探索多边形有效边表填充算法原理与实现
- Gitblit Windows版搭建开源项目服务器指南
- C++教学管理系统:详解与调试
- React Native集成JPush插件教程与Android平台支持
- TravelFeed帖子的tf内容呈现器技术解析
- Android四页面Activity跳转实战教程
- Ruby编程语言第二天习题解答详解
- 简化伺服调试:探索ServoPlus Arduino库的新特性
- 惠普hp39gs计算器使用指南解析
- STM32F103与VL53L0X红外测距模块的集成方案
- 北大青鸟y2CRM系统结业项目源码及需求分析
- 深入解析贴吧扫号机的操作与功能
