YARN操作详解:资源管理与Spark参数调优
需积分: 10 196 浏览量
更新于2024-07-15
收藏 4.17MB PDF 举报
"YARN的相关操作总结,包括查看资源、参数设置、资源占用情况以及Spark任务并行度的探讨。"
本文主要围绕Apache YARN(Yet Another Resource Negotiator)的使用和Spark作业在YARN上的资源配置进行深入探讨。YARN是Hadoop生态系统中的资源管理器,负责调度集群资源,确保应用程序高效运行。
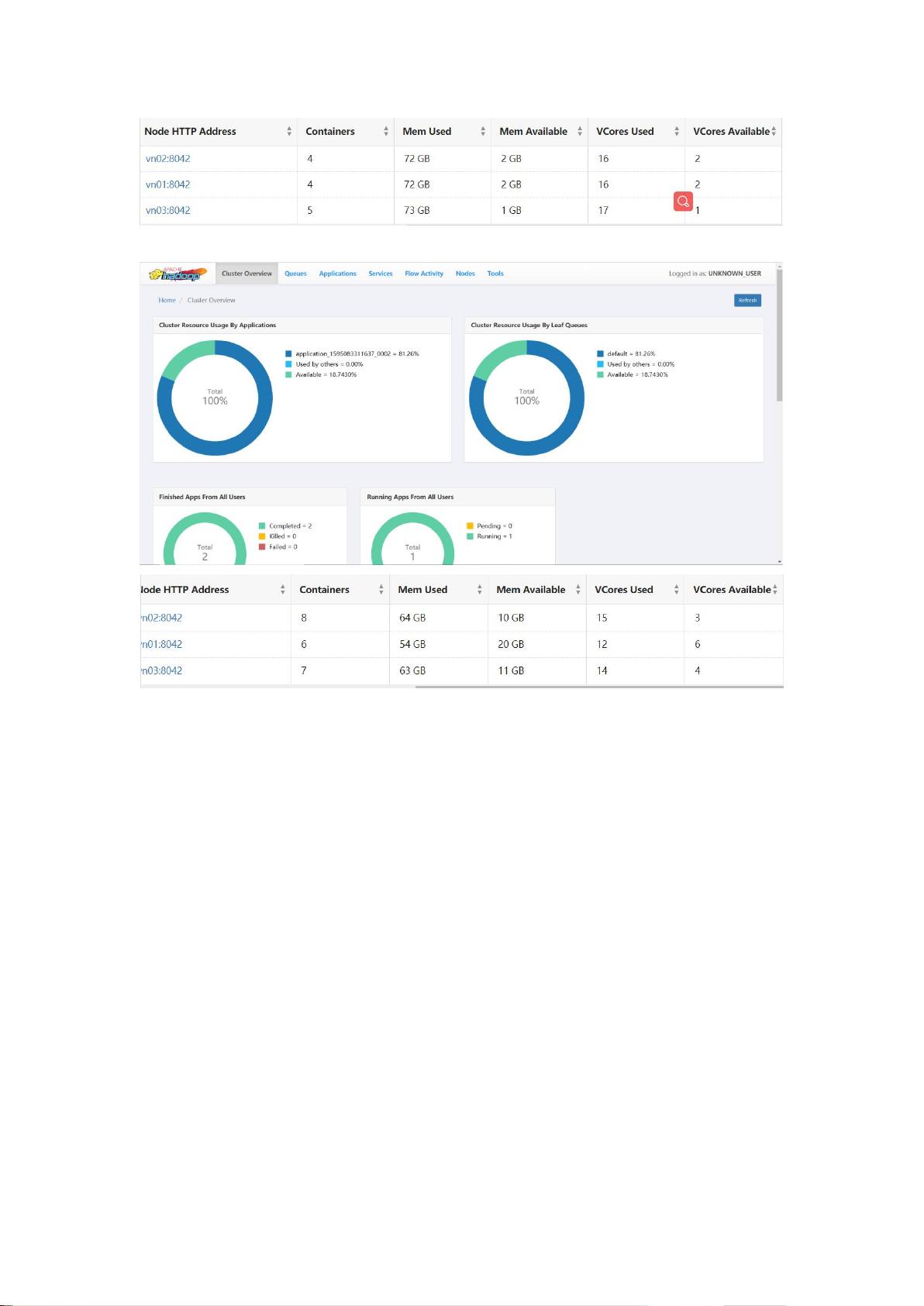
首先,要了解如何在YARN的ResourceManager界面上监控集群资源。在初始状态下,可以查看到集群的总资源量,包括内存和CPU资源。当启动一个如`spark-shell`的应用后,可以看到资源使用的变化,包括剩余资源和正在使用的资源。通过查看Applications信息,可以跟踪各个应用的资源消耗。
其次,配置Spark作业在YARN上运行时的关键参数包括`num-executors`(执行器数量)、`executor-cores`(每个执行器的核心数)和`executor-memory`(每个执行器的内存)。通过调整这些参数,可以观察到不同设置下,集群资源的占用情况。例如,增加`num-executors`但减小`executor-memory`或`executor-cores`可能会提高资源利用率,但需根据实际应用需求和集群资源状况来平衡。
接着,提到了`spark.sql.shuffle.partitions`和`spark.default.parallelism`这两个影响Spark任务并行度的参数。`spark.sql.shuffle.partitions`适用于涉及shuffle操作的Spark SQL查询,如JOIN或聚合操作,设定默认分区数,从而决定任务数。而`spark.default.parallelism`则是Spark所有非SQL操作的默认并行度。虽然两者都能设置并行度,但在不同场景下适用,一般建议优先设置`spark.sql.shuffle.partitions`,因为它更具体地针对shuffle操作。
最后,调整并行度对任务执行效率有很大影响。合理设置并行度能优化任务执行速度,减少数据传输和计算压力。例如,如果将`spark.default.parallelism`设置得过高,可能导致资源过度分配,造成不必要的开销;反之,设置过低可能限制了作业的并行处理能力,延长作业执行时间。
理解和熟练掌握YARN的资源管理和Spark作业的资源配置对于优化大数据处理性能至关重要。通过持续监控和调整参数,可以有效地利用集群资源,提高作业执行效率。同时,注意不同场景下选择合适的并行度参数,能够进一步提升Spark作业的性能。
5
spark-shell --num-executors 20 --executor-memory 8G --executor-cores 2
spark-shell --num-executors 10 --executor-memory 16G --executor-cores 2
剩余20页未读,继续阅读
2018-06-09 上传
2021-05-27 上传
2021-10-14 上传
2023-08-30 上传
2023-05-19 上传
2022-10-15 上传

LaiYoung1022
- 粉丝: 70
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- 程序靠边自动隐藏窗口-易语言
- Pipo:用于从Firebase提取数据并显示的Android项目
- school_project
- flutter_google_ml_vision:适用于Google ML Kit Vision的Flutter插件
- codeandsewn.github.io
- CheckHealth.github.io
- 林森塔
- Happy-Holi
- Prog2_Reseau:Prog2 Java LP SIL的小型项目Vianey Benjamin-Bodet Cindy
- c# 锁屏系统
- hackgt21-whispermom:HackGT'21的临时仓库
- 网址:霓虹灯线
- Webpack_PW_Anul_2
- 能否上网-易语言
- nonogram:基于遗传算法的非图求解器
- 控制
