词法分析器设计与DFA实现
 已收录资源合集
已收录资源合集
需积分: 0 118 浏览量
更新于2024-08-04
收藏 148KB DOCX 举报
"词法分析器的设计文档描述了如何使用Python和graphviz创建确定有限自动机(DFA)来识别编程语言中的各种符号,包括标识符、关键字、无符号数、单符号和超前识别的符号,如'='。"
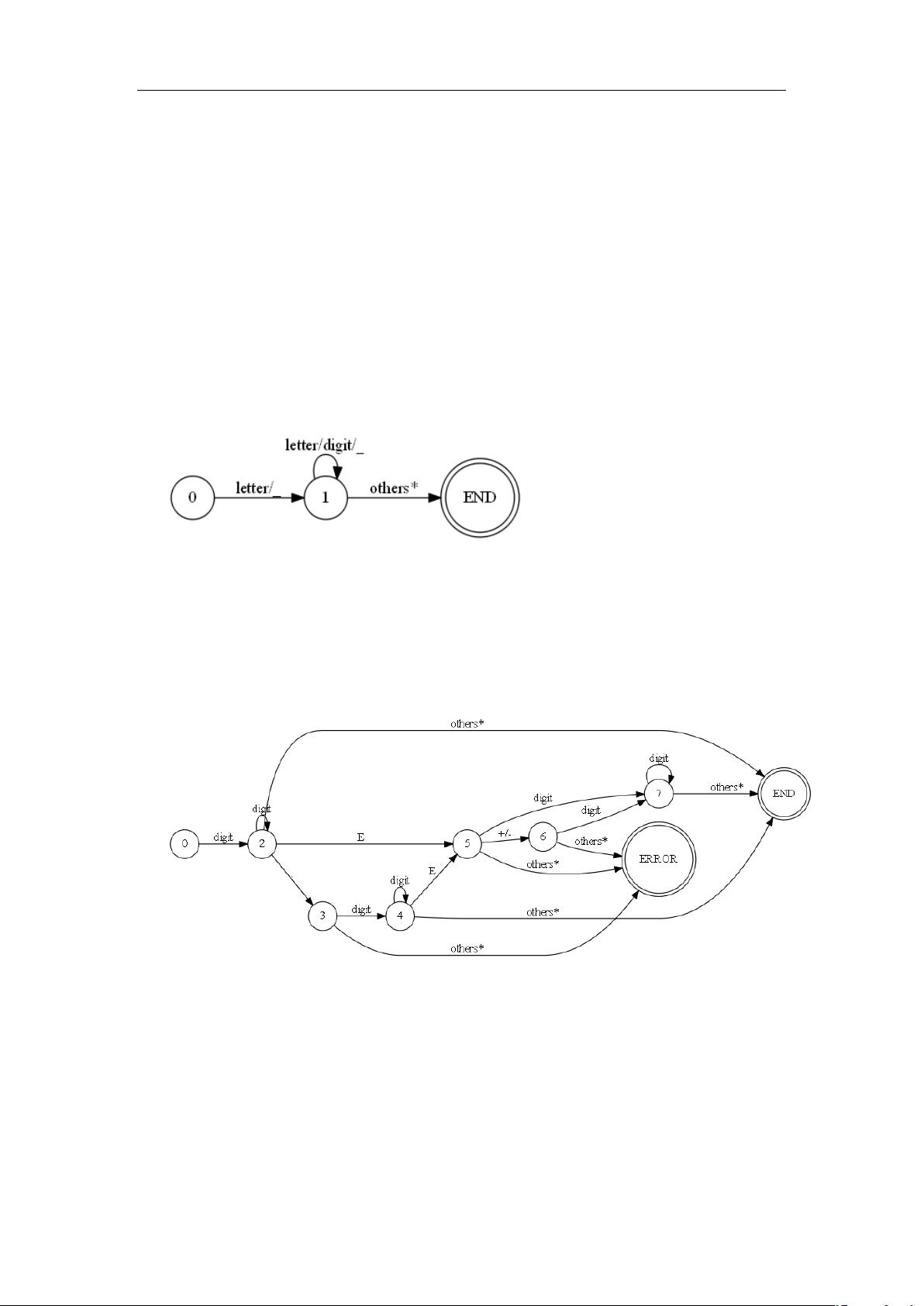
在词法分析器的设计中,首要任务是构建一个DFA来识别不同的语言元素。DFA是一种状态机,能够根据输入的字符序列进行状态转换,从而帮助识别出编程语言中的关键字、标识符、数字和其他符号。在这个设计中,state=0被设定为初始状态,自动机从这个状态开始读取字符,并根据字符类型转移到相应的子状态。
1. **标识符和关键字识别**:
- 当遇到字母(letter)或下划线(_)时,词法分析器进入标识符或关键字状态。标识符可以由字母、下划线和数字组成,直到遇到其他非字母、非下划线的字符。如果该序列匹配到预定义的关键字列表中的某个词,它将被识别为关键字,否则视为标识符。关键字列表在程序启动时从文件加载。
2. **无符号数识别**:
- 如果读取到数字(digit),词法分析器进入无符号数状态。这个状态与标准的自动机设计一致,直到遇到非数字字符。如果在某个状态下没有与之对应的字符射出,表示发生错误,会触发errorProcess,将状态重置为0,并回送字符,同时打印错误信息。
3. **错误处理**:
- errorProcess是处理不完全状态的机制,即状态的射出字符集合不完全覆盖所有可能的输入字符。在这种情况下,系统会回退到初始状态并返回错误消息。
4. **单符号识别**:
- 单个符号如逗号 (,)、左括号 ( ( ) 、中括号 [ ] 和大括号 { } 及分号 (;) 直接被识别并输出相应的token。
5. **超前识别**:
- 对于像'='这样的符号,词法分析器需要超前读取下一个字符。如果下一个字符是'=',则输出关系运算符"==";否则,调用otherProcess,输出赋值运算符"="。otherProcess处理不属于任何特定状态的字符,它回送一个字符,增加行号,状态重置为0,并输出token。
在实现过程中,利用Python调用graphviz库来绘制DFA图,这有助于可视化设计并确保每个状态都有适当的出口,要么是ERROR状态用于错误处理,要么是END状态表示识别到一个完整的符号并返回token。对于需要超前读取的符号,设计考虑了额外的逻辑以确保正确识别。
这个设计充分考虑了词法分析的基本原则,包括状态转移、错误处理和符号识别的灵活性,为编译器或解释器的前端提供了坚实的基础。通过Python和graphviz的结合,不仅能够实现词法分析,还能生成易于理解和调试的图形表示。
史文翰 No.2014211218 Cla.2014211304
词法分析程序设计文档
一、识别各类符号的 DFA
我们令 state = 0 时作为系统的初态,此时自动机处于初始状态,自动机应读入一个字
符,并根据这个字符做状态转移,进入到相应的子自动机。我们根据 DNF 在初态输入的第
一个符号来作为以下说明的分类。
1. letter / _
此时进入标识符或关键字状态,除添加下划线与 letter 等价之外,其余部分均与教材中
的自动机相同。在遇到 other*时输出标识符或关键字,具体取决于在关键字表中查找的结果。
关键字表以文件的形式存储,在程序开始时被自动载入。
2. digit
此时进入无符号数识别状态。与教材中的状态机相同。请注意,我们在这里定义一个错
误处理过程 errorProcess,某一状态是可能出错的,当且仅当这个状态射出字符的集合的并
集与本程序识别的符号集不相等,也就是说,这个状态的射出字符集是不完全的。当在此状
态下输入无射出的字符,那么将会进入到错误处理阶段。
在 errorProcess 中,我们定义这样的过程:状态回零并向输入流回送一个字符,并打印
错误报文。
如上,我们利用 python 调用 graphviz 绘制 DFA,其基本思想与我们的设计是一致的,
除了开始状态(状态 0)以外,有责任为每一个子状态设置出口,这个出口只能是 ERROR
或者是 END(这是由于射出集合的完备性,即对于任何中间状态,其射出字符集合的并应
与识别的字符集相等),其中 ERROR 代表执行过程 errorProcess,而 END 代表 renturn 一个
token,如果 label 带有‘others*’的标志则还需执行 otherProcess,并完成相关的处理工作。
3. , / ( / ) / [ / ] / { / } / ;
此时进入单符号识别状态,这些符号在本程序的符号集中不需要超前识别,因此遇到它
们直接输出相应的 token 即可。
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-11-28 上传
2024-04-17 上传
2022-08-08 上传
2021-10-11 上传
2008-11-20 上传
2011-04-21 上传

懂得越多越要学
- 粉丝: 28
- 资源: 307
 我的内容管理
展开
我的内容管理
展开







最新资源
- python数据结构和算法
- Projeto-PaginaDeCaptura:创建捕获页面项目的目的是注册活动人员。 使用在线工具Mailchimp访问参与者的注册
- css_sideproject
- billiards-server:台球厅管理系统微观代码
- react-suspenser::sloth:简化延迟加载过程的管理
- ltfat.github.io:LTFAT网页
- IntroToAlgorithms:CS3-使用Jupyter Notebooks的C ++算法简介
- devfest-Lima2015-javafx:DevFest Lima 2015-JavaFX有什么不错的选择吗? 动画和粒子工作室
- 42559298three-phase-SVPWM-Inverter.rar_matlab例程_matlab_
- Tutorium_Summer_2021_Prog2:教职员工
- product_ping:Ping产品以检查库存状态
- STM32 Debug+Mass storage+VCP V2.J40.M27固件+原理图
- 毕业设计&课设-AMrotor-一个用于旋转机械仿真的MATLAB工具箱.zip
- CASS地物代码快速查找
- 学习语言:学习新的和不同的语言
- 5kCMS K1 网站内容管理系统 v0.1
