NLP数据增强策略:EDA、BT、MixMatch与UDA深度解析
版权申诉
38 浏览量
更新于2024-08-04
收藏 856KB PDF 举报
NLP数据增强方法综述:EDA、BT、MixMatch、UDA
在现代自然语言处理(NLP)中,数据增强是一种重要的策略,用于在有限的标注数据集上提升模型的泛化能力,尤其是在分类任务中,当不同类别的数据量不平衡时。数据增强最初在计算机视觉领域广泛应用,通过图像变换创造出新的训练样本,但NLP数据的特点决定了直接应用这些技术并不直接适用。文本数据增强主要关注的是离散文本的处理,其核心方法分为两大类:加噪和回译。
1. 加噪方法:
- **同义词替换** (SynonymsReplace): EDA中提到的一种技术,通过替换文本中的词语为其同义词,保持句子基本意义不变,但增加多样性,有助于模型理解词汇的多义性。
- **随机插⼊** (RandomlyInsert): 在句子中随机插入新的词语,如专业术语、短语或成语,以模拟实际语境中的变体。
- **随机交换** (RandomlySwap): 随机交换句子中的单词位置,保持语法结构的同时,改变文本的表达方式。
- **随机删除** (RandomDeletion): 删除词语,观察模型对缺失信息的理解和填充能力。
2. 回译方法:
- **双语翻译** (Back-Translation, BT): 将文本翻译成另一种语言,然后再翻译回源语言。由于翻译过程可能会引入语义变化,这种方法可以生成全新的句子,提高模型的适应性和泛化能力。
3. 其他方法:
- **MixMatch** 是一种结合了数据增强和半监督学习的方法,通过混合原始数据和生成的伪标签数据进行训练,以减少过拟合。
- **Unsupervised Data Augmentation** (UDA) 或称无监督数据增强,利用未标记数据生成模型的假设来扩展训练集,这类方法适用于标注数据稀缺的情况。
总结起来,NLP数据增强是一种通过在已有数据集上生成多样化、但保持语义一致性的新样本,以提升模型在实际应用中的性能。不同的方法侧重于解决不同问题,加噪注重词汇层面的变化,而回译则关注句子结构和语义的变换。理解并灵活运用这些技术,对于有效利用有限标注数据,降低模型过拟合风险,提高NLP模型的泛化能力至关重要。
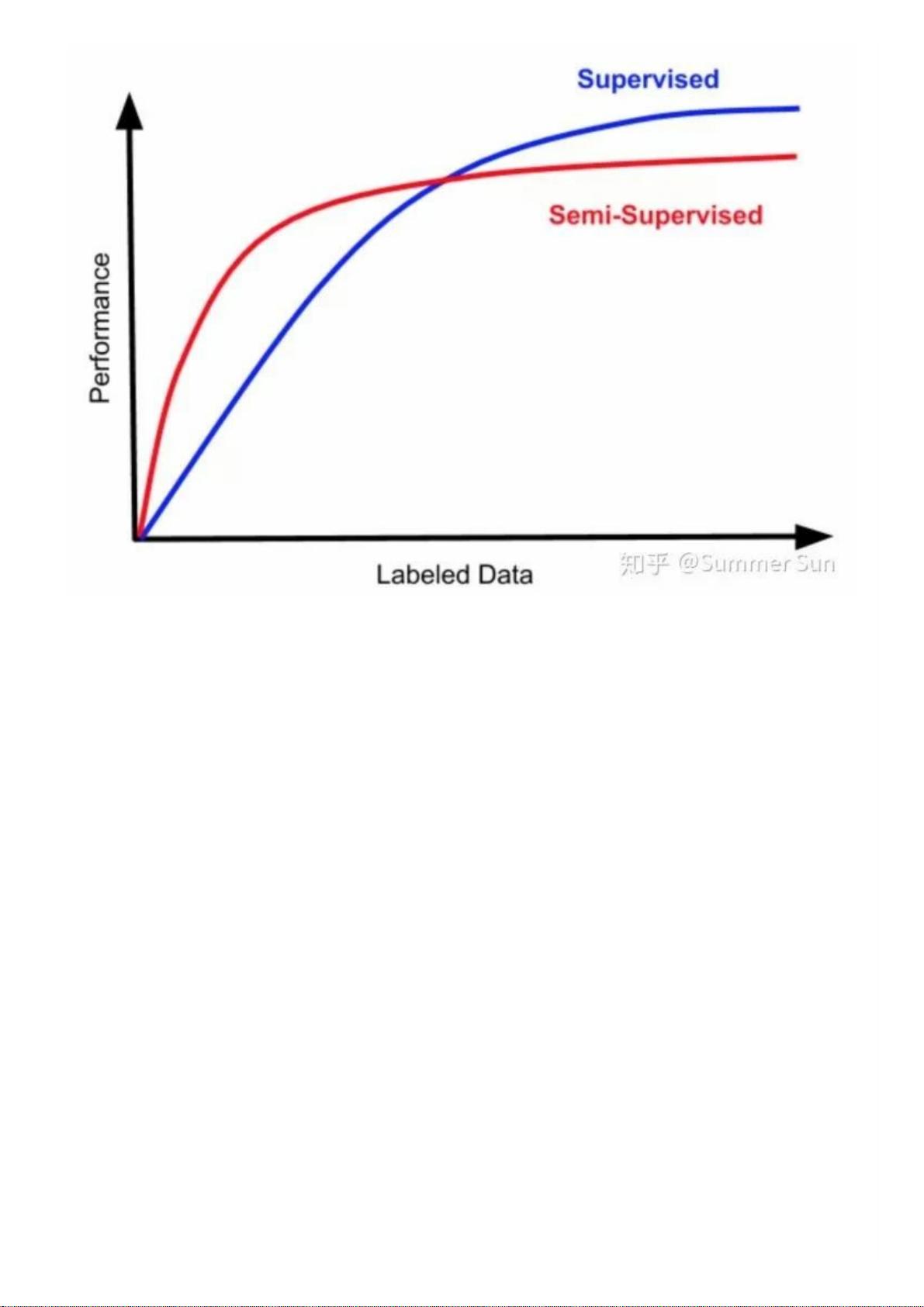
数据增强起初在计算机视觉领域应⽤较多,主要是运⽤各种技术⽣成新的训练样本,可以通过对图像的平移、旋转、压缩、调整
⾊彩等⽅式创造新的数据。虽然,‘新’的样本在⼀定程度上改变了外观,但是样本的标签保持不变。且NLP中的数据是离散的,这
导致我们⽆法对输⼊数据进⾏直接简单地转换,换掉⼀个词就有可能改变整个句⼦的含义。因此本⽂将重点介绍⽂本数据增强的
⽅法和技术,以快速补充⽂本数据。
2 传统⽂本数据增强的技术
现有NLP的Data Augmentation⼤致有两条思路,⼀个是加噪,另⼀个是回译,均为有监督⽅法。 加噪即为在原数据的基础上通过
替换词、删除词等⽅式创造和原数据相类似的新数据。回译则是将原有数据翻译为其他语⾔再翻译回原语⾔,由于语⾔逻辑顺序
等的不同,回译的⽅法也往往能够得到和原数据差别较⼤的新数据。
Easy Data Augmentation for Text Classification Tasks (EDA) 提出并验证了⼏种加噪的 text augmentation 技巧,分别是 同
义词替换(SR: Synonyms Replace)、随机插⼊(RI: Randomly Insert)、随机交换(RS: Randomly Swap)、随机删除(RD:
Randomly Delete),下⾯进⾏简单的介绍:
2.1 EDA
(1) 同义词替换(SR: Synonyms Replace): 不考虑stopwords,在句⼦中随机抽取n个词,然后从同义词词典中随机抽取同义
词,并进⾏替换。
Eg: “我⾮常喜欢这部电影” —> “我⾮常喜欢这个影⽚”,句⼦仍具有相同的含义,很有可能具有相同的标签。
(2) 随机插⼊(RI: Randomly Insert):不考虑stopwords,随机抽取⼀个词,然后在该词的同义词集合中随机选择⼀个,插⼊原句
剩余11页未读,继续阅读
2023-10-18 上传
点击了解资源详情
755 浏览量
1184 浏览量
797 浏览量
1207 浏览量
413 浏览量
104 浏览量

普通网友
- 粉丝: 1283
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握PerfView:高效配置.NET程序性能数据
- SQL2000与Delphi结合的超市管理系统设计
- 冲压模具设计的高效拉伸计算器软件介绍
- jQuery文字图片滚动插件:单行多行及按钮控制
- 最新C++参考手册:包含C++11标准新增内容
- 实现Android嵌套倒计时及活动启动教程
- TMS320F2837xD DSP技术手册详解
- 嵌入式系统实验入门:掌握VxWorks及通信程序设计
- Magento支付宝接口使用教程
- GOIT MARKUP HW-06 项目文件综述
- 全面掌握JBossESB组件与配置教程
- 古风水墨风艾灸养生响应式网站模板
- 讯飞SDK中的音频增益调整方法与实践
- 银联加密解密工具集 - Des算法与Bitmap查看器
- 全面解读OA系统源码中的权限管理与人员管理技术
- PHP HTTP扩展1.7.0版本发布,支持PHP5.3环境
