Faster R-CNN: 深度学习实时目标检测技术
下载需积分: 0 | PDF格式 | 6.49MB |
更新于2024-09-07
| 165 浏览量 | 举报
"这篇资源是关于深度学习领域的一篇重要论文——Faster R-CNN,主要探讨了如何实现更快的实时目标检测技术,通过引入区域提议网络(Region Proposal Networks, RPN)。该论文由Shaoqing Ren、Kaiming He、Ross Girshick和Jian Sun合作完成,对深度学习和计算机视觉领域的研究者具有很高的参考价值,特别适合对边界测定和深度学习感兴趣的读者。"
Faster R-CNN是深度学习中用于目标检测的一种高效算法,其核心创新在于提出了区域提议网络(RPN)。传统的目标检测网络依赖于独立的区域提议算法来预测可能包含对象的位置,这在处理速度上是一个明显的瓶颈。RPN的设计解决了这一问题,它与检测网络共享全图像卷积特征,使得生成区域提议几乎不增加额外计算成本。
RPN本身是一个全卷积网络,它在图像的每个位置同时预测物体边界框(bounding boxes)和物体存在概率(objectness scores)。这个网络经过端到端的训练,能生成高质量的区域提议,这些提议随后被Fast R-CNN用于目标检测。RPN的引入可以看作是神经网络中的“注意力”机制,它告诉统一网络应该关注哪里。
通过将RPN与Fast R-CNN合并成一个单一的网络结构,并共享它们的卷积特征,Faster R-CNN显著提升了检测系统的运行效率。特别是在深度的VGG-16模型上,该系统能够达到每秒5帧的检测速率,这对于实时应用来说是一个巨大的进步。
此外,Faster R-CNN的工作还推动了后续的许多目标检测方法的发展,如YOLO(You Only Look Once)、SSD(Single Shot MultiBox Detector)等,它们都在尝试进一步提高检测速度和精度。因此,对于想要深入理解深度学习目标检测技术或撰写相关论文、专利的读者,这篇论文无疑是一份宝贵的参考资料。
3
image
conv layers
feature maps
Region Proposal Network
proposals
classifier
RoI pooling
Figure 2: Faster R-CNN is a single, unified network
for object detection. The RPN module serves as the
‘attention’ of this unified network.
into a convolutional layer for detecting multiple class-
specific objects. The MultiBox methods [26], [27] gen-
erate region proposals from a network whose last
fully-connected layer simultaneously predicts mul-
tiple class-agnostic boxes, generalizing the “single-
box” fashion of OverFeat. These class-agnostic boxes
are used as proposals for R-CNN [5]. The MultiBox
proposal network is applied on a single image crop or
multiple large image crops (e.g., 224×224), in contrast
to our fully convolutional scheme. MultiBox does not
share features between the proposal and detection
networks. We discuss OverFeat and MultiBox in more
depth later in context with our method. Concurrent
with our work, the DeepMask method [28] is devel-
oped for learning segmentation proposals.
Shared computation of convolutions [9], [1], [29],
[7], [2] has been attracting increasing attention for ef-
ficient, yet accurate, visual recognition. The OverFeat
paper [9] computes convolutional features from an
image pyramid for classification, localization, and de-
tection. Adaptively-sized pooling (SPP) [1] on shared
convolutional feature maps is developed for efficient
region-based object detection [1], [30] and semantic
segmentation [29]. Fast R-CNN [2] enables end-to-end
detector training on shared convolutional features and
shows compelling accuracy and speed.
3 FASTER R-CNN
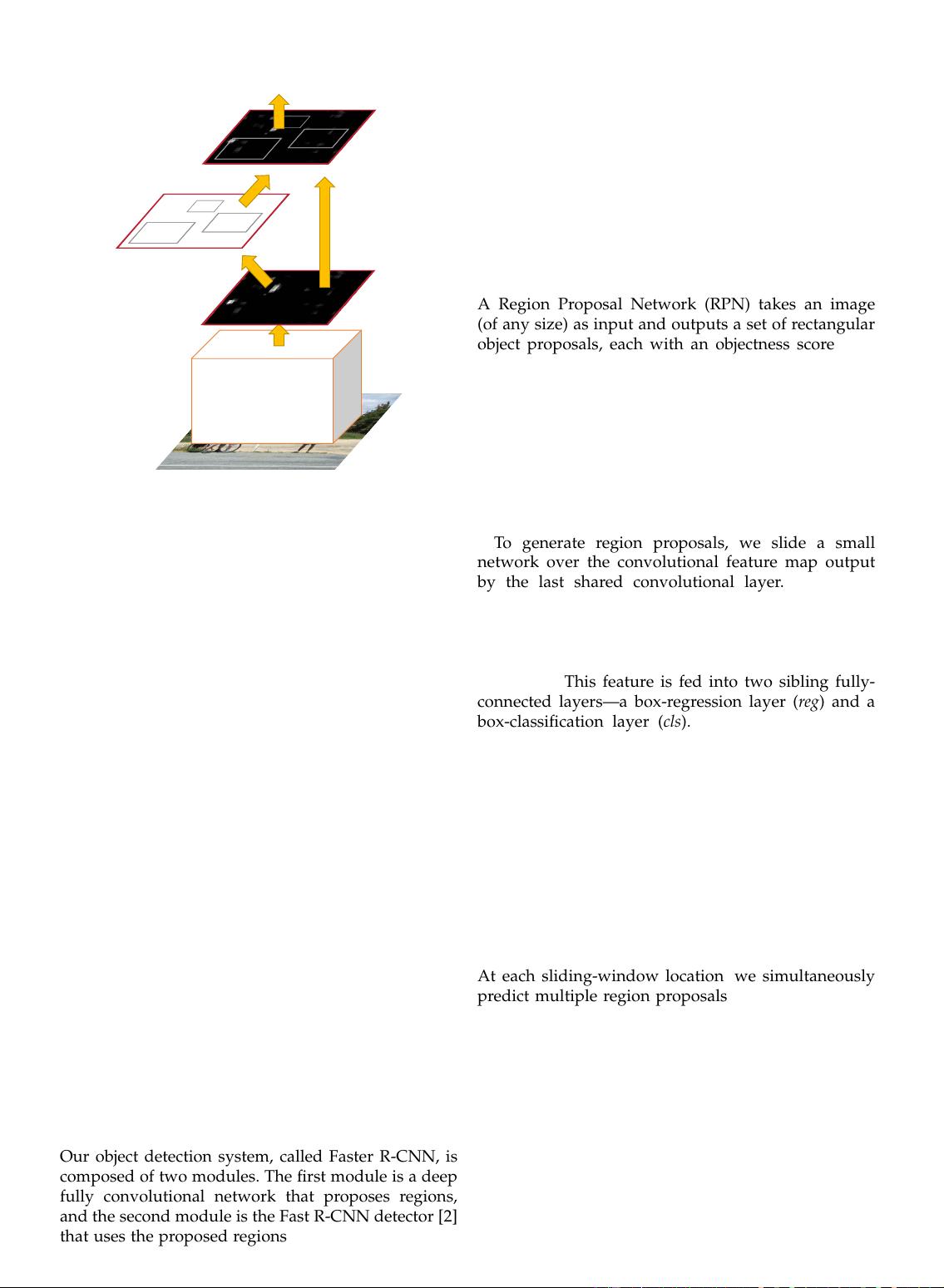
Our object detection system, called Faster R-CNN, is
composed of two modules. The first module is a deep
fully convolutional network that proposes regions,
and the second module is the Fast R-CNN detector [2]
that uses the proposed regions. The entire system is a
single, unified network for object detection (Figure 2).
Using the recently popular terminology of neural
networks with ‘attention’ [31] mechanisms, the RPN
module tells the Fast R-CNN module where to look.
In Section 3.1 we introduce the designs and properties
of the network for region proposal. In Section 3.2 we
develop algorithms for training both modules with
features shared.
3.1 Region Proposal Networks
A Region Proposal Network (RPN) takes an image
(of any size) as input and outputs a set of rectangular
object proposals, each with an objectness score.
3
We
model this process with a fully convolutional network
[7], which we describe in this section. Because our ulti-
mate goal is to share computation with a Fast R-CNN
object detection network [2], we assume that both nets
share a common set of convolutional layers. In our ex-
periments, we investigate the Zeiler and Fergus model
[32] (ZF), which has 5 shareable convolutional layers
and the Simonyan and Zisserman model [3] (VGG-16),
which has 13 shareable convolutional layers.
To generate region proposals, we slide a small
network over the convolutional feature map output
by the last shared convolutional layer. This small
network takes as input an n × n spatial window of
the input convolutional feature map. Each sliding
window is mapped to a lower-dimensional feature
(256-d for ZF and 512-d for VGG, with ReLU [33]
following). This feature is fed into two sibling fully-
connected layers—a box-regression layer (reg) and a
box-classification layer (cls). We use n = 3 in this
paper, noting that the effective receptive field on the
input image is large (171 and 228 pixels for ZF and
VGG, respectively). This mini-network is illustrated
at a single position in Figure 3 (left). Note that be-
cause the mini-network operates in a sliding-window
fashion, the fully-connected layers are shared across
all spatial locations. This architecture is naturally im-
plemented with an n×n convolutional layer followed
by two sibling 1 × 1 convolutional layers (for reg and
cls, respectively).
3.1.1 Anchors
At each sliding-window location, we simultaneously
predict multiple region proposals, where the number
of maximum possible proposals for each location is
denoted as k. So the reg layer has 4k outputs encoding
the coordinates of k boxes, and the cls layer outputs
2k scores that estimate probability of object or not
object for each proposal
4
. The k proposals are param-
eterized relative to k reference boxes, which we call
3. “Region” is a generic term and in this paper we only consider
rectangular regions, as is common for many methods (e.g., [27], [4],
[6]). “Objectness” measures membership to a set of object classes
vs. background.
4. For simplicity we implement the cls layer as a two-class
softmax layer. Alternatively, one may use logistic regression to
produce k scores.
剩余13页未读,继续阅读
相关推荐





驰骋畋猎心发狂
- 粉丝: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- 小学水墨风学校网站模板设计
- 深入理解线程池的实现原理与应用
- MSP430编程代码集锦:实用例程源码分享
- 绿色大图幻灯商务响应式企业网站开发源码包
- 深入理解CSS与Web标准的专业解决方案
- Qt/C++集成Google拼音输入法演示Demo
- Apache Hive 0.13.1 版本安装包详解
- 百度地图范围标注技术及应用
- 打造个性化的Windows 8锁屏体验
- Atlantis移动应用开发深度解析
- ASP.NET实验教程:源代码详细解析与实践
- 2012年工业观察杂志完整版
- 全国综合缴费营业厅系统11.5:一站式缴费与运营管理解决方案
- JAVA原生实现HTTP请求的简易指南
- 便携PDF浏览器:随时随地快速查看文档
- VTF格式图片编辑工具:深入起源引擎贴图修改
