R爬虫与文本挖掘实战:从入门到动态网页解析
需积分: 0 170 浏览量
更新于2024-08-05
收藏 1.41MB PDF 举报
R爬虫及文本挖掘是数据获取与分析领域的重要组成部分,特别是在大数据时代,数据的价值日益凸显。本文由周世祥于2020年3月22日撰写,主要探讨如何利用R语言进行爬虫编程以及在文本挖掘中的应用。
首先,爬虫被定义为一种编程工具,通过编程语言如R,它能够自动在网络上搜索和抓取所需的信息。这在寻找特定数据,如房屋信息或者科学研究中的数据时显得尤为高效,避免了人工逐页查找的低效和耗时。对比Python的Scrapy框架,虽然Scrapy以其易用、代码量少和高效著称,但它可能在灵活性和透明度方面有所欠缺。相比之下,使用R语言编写爬虫则可能更适合那些需要高度定制化和灵活性的项目。
文章强调了理解HTTP协议、区分静态网页和动态网页的重要性。静态网页是加载后已存在的HTML内容,而动态网页则需要服务器根据请求实时生成,依赖于后台数据库支持。例如,登录教务系统查看成绩或使用百度地图导航时的个性化显示都是动态网页的体现。H5前端开发尽管薪酬可观,但如果仅局限于前端,知识面狭窄可能会面临被淘汰的风险,因此全栈工程师的概念应运而生,即融合前端和后端技能。
H5(HyperText Markup Language)的兴起是因为云计算的发展,个人不再需要拥有强大的本地服务器,而是可以通过云服务(如阿里云、腾讯云、华为云)获取计算能力。这些云服务使得开发人员可以在轻终端(如笔记本或手机)上运行应用,只需要安装Web容器(如浏览器)即可访问。这反映了互联网时代的趋势,浏览器的角色愈发重要,微软将浏览器集成到操作系统中就是一个例证。
在R爬虫中,开发者需要掌握诸如JSON格式处理、Selenium自动化测试等关键技术。JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,常用于前后端数据交互;Selenium则是一个自动化测试工具,可用于模拟用户行为,包括在动态网页上的操作。
R爬虫结合文本挖掘能力,为企业和个人提供了获取和分析大量网络数据的强大工具,同时要求开发者具备跨领域的技术理解和实践经验,以适应快速变化的技术环境。
R爬虫及进行文本挖掘
周世祥
2020/3/22
数据获取方式
大数据时代,最不缺的是数据,数据就是黄金,就是石油,可是作为个人来说,获取数据并不容易,特别是有价值的数据。这个时候,爬虫就开始行
动了,所谓的爬虫就是我们用编程语言写的程序,能够不知疲倦地替我们去广阔的互联网上替我们搜寻信息。你到一个陌生的地方,想找一个便宜的
房子,从网上一个一个页面去搜索,太慢了,效率低。你想研究新冠病毒的发病模型,数据哪儿来,写个爬虫就替你做了。
如果你学过Python,一定听说过大名鼎鼎的爬虫框架–scrapy [https://baike.baidu.com/item/scrapy/7914913?fr=aladdin
(https://baike.baidu.com/item/scrapy/7914913?fr=aladdin)].
框架的好处是方便,安装好了就可以用,代码量少,效率高,不好的地方就是灵活性不够,有些地方对用户来说不透明。对一些项目来说,我们用R
的几行代码就可以自动化地采集数据。
当然学习爬虫需要先明确一些概念,比如,Http协议,静态网页和动态网页,json格式,selenium自动化测试。
静态页面和动态页面
静态页面并不是指没有动态效果的网页,现在的H5中JavaScript已经能做出漂亮的动画效果,静态网页指的是HTML网页在我们客户端请求时候已经
客观存在于网页服务器上了。
动态网页是指在收到请求的时候,根据请求用服务器程序(PHP,JSP ,ASPX)“动态”地生成HTML网页。比如,你上教务系统上查看自己的成绩,你只
能看到自己的信息,你看到的网页和别人不一样。你用百度地图导航时,随着位置不同,地图需要不断更新。动态页面说到底,需要后台数据库服务
器支持,数据必须不断更新。
尽管H5前端编程工资待遇不错的,然而只会前端,知识面太窄,很容易被淘汰的,所以现在有些机构美其名曰,全栈工程师,就是加上一些后端的
编程技术进行补充。
H5的流行是有道理的,在这个云时代,我们要转变思想了,不需要买强劲的服务器,阿里云,腾讯云,华为云都提供云服务,我们个人只需有一个
终端就可以,这个终端可以是笔记本,手机等轻终端,我们可以把软件或应用部署在云上,终端上只需安装一个web容器就可以,这个容器就是浏览
器,想想微软为什么要把ie集成到操作系统,就知道浏览器是互联网的入口。web发展到现在,你可以感觉到,单机版的软件没有出路,PC端的软件
越来越少,连一个驱动精灵,替我们安装电脑驱动的软件都有web版了。现在我们上网课,数不清的在线直播平台,功能越来越强大。这里说马化腾
引以为傲的微信,腾讯的核心产品,是一种不需要下载安装即可使用的应用,它实现了应用“触手可及”的梦想,用户扫一扫或搜一下即可打开应用。
web的流行可见是有历史原因的。
web页面的构成
web其实就是HTML文件,HTML文件由三部分组成:内容是什么,HTML脚本,描述怎么样,即CSS样式,动作行为,即JavaScript。 JavaScript对
HTML,CSS进行操纵(增、删、改、查)。
如果程序能解析HTML结构就能控制页面,从而爬取相关的信息。
DOM的结构
DOM文档对象模型[https://baike.baidu.com/item/DOM%E5%AF%B9%E8%B1%A1/6621083?fr=aladdin
(https://baike.baidu.com/item/DOM%E5%AF%B9%E8%B1%A1/6621083?fr=aladdin)],是W3C组织推荐的处理可扩展标记语言的标准编程接口。
前面讲到web页面由各种层次的标签元素构成的,随便找来一个页面源代码,你会看到最上层有一个html,里面会有head,title等等标签,从数据结构
上看,总体上看是一个树形结构,实际上,见过markdown,latex,你了解到他们都是标记语言,结构都是类似的。这些结构不想我们的矩阵或
excel表格那么工整,它们都是非结构化的数据,所以想提取信息,需要费点功夫的。
推荐一本好书《细说DOM编程》,兄弟连出品的,兄弟连在线机构,可惜在这次病毒流行中没能坚持住,倒闭了。
JSON
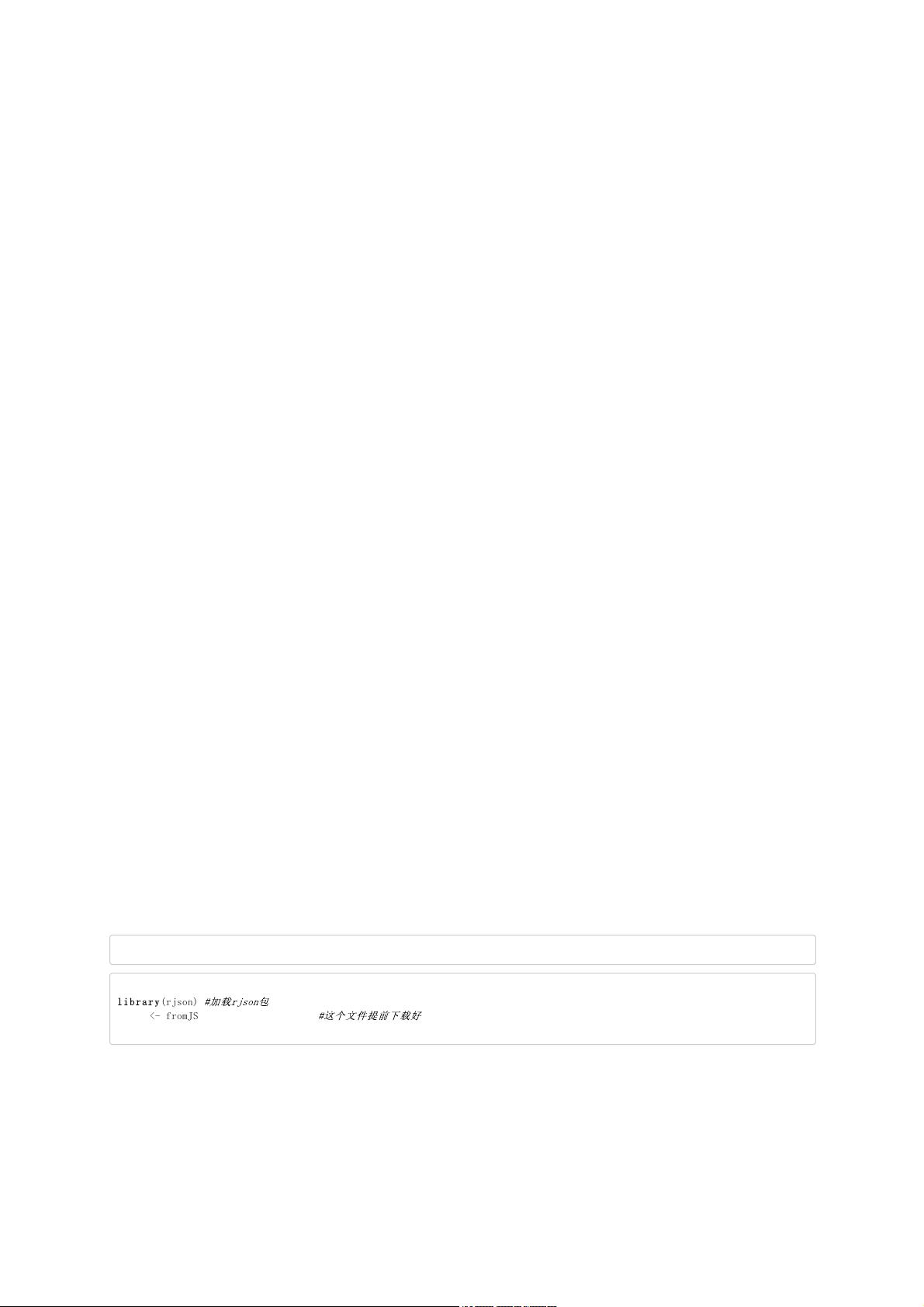
JSON是什么,我们从网上收集的数据大多是JSON格式,特别是通过API方式,你可以把JSON理解为一个格式化好的数据。 R语言中先安装JSON
包。
install.packages("J:/R课件/rjson_0.2.20.zip", repos = NULL, type = "win.binary")
setwd('J:/R课件')
library
(rjson)
#
加
载
rjson
包
result<- fromJSON(file="input.json")
#
这
个
文
件
提
前
下
载
好
print(result)
下载后可阅读完整内容,剩余8页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

daidaiyijiu
- 粉丝: 20
- 资源: 322
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
