MyBatis查询缓存机制详解:一级缓存与二级缓存
53 浏览量
更新于2024-09-07
收藏 345KB PDF 举报
"MyBatis查询缓存主要用于提升查询速度,通过存储重复查询的结果来减少对数据库的访问。它包括一级缓存和二级缓存。一级缓存基于PerpetualCache的HashMap,作用于SqlSession,生命周期随SqlSession结束而结束,且默认开启。一级缓存的关键在于相同的SQL映射ID,不同参数的查询结果也会被缓存。二级缓存则跨多个SqlSession,作用于整个Mapper配置,可配置开启或关闭。"
在MyBatis中,查询缓存是一个重要的性能优化手段。一级缓存是MyBatis默认提供的本地缓存,它位于SqlSession级别。这意味着在一个SqlSession的生命周期内,如果执行了相同的SQL查询(根据SQL映射ID判断),第二次查询会直接从缓存中获取结果,而不是再次执行数据库查询。这显著提升了查询效率,尤其是在连续多次查询相同数据时。
一级缓存的运作原理基于HashMap,其中键是SQL映射ID,值是查询结果。这意味着即使SQL语句完全相同,但只要SQL映射ID不同,一级缓存就不会混淆。例如,两个不同的Mapper方法可能有相同的SQL语句,但由于它们的ID不同,MyBatis会将它们的查询结果分开存储。值得注意的是,一级缓存并不区分查询参数,即相同SQL映射ID但参数不同的查询,结果也会被缓存。
一级缓存的生命周期非常短暂,当SqlSession关闭时,一级缓存中的所有数据都会丢失。因此,如果在同一个SqlSession中进行了修改操作,如增删改,然后再次进行查询,此时一级缓存中的数据将被视为无效,MyBatis会强制清空一级缓存,以防止返回过时的数据。
尽管一级缓存能提供一定的性能提升,但它受限于SqlSession的范围,无法跨会话共享数据。为了应对这种情况,MyBatis提供了二级缓存。二级缓存是一个全局的缓存,它跨越多个SqlSession,甚至多个Mapper配置。二级缓存的配置更为灵活,可以通过在Mapper配置文件中启用或禁用,也可以自定义缓存实现。
二级缓存同样基于HashMap实现,但与一级缓存不同的是,它的键是完整的Mapper ID(包括Mapper的namespace和SQL的id),这样可以区分不同Mapper的相同查询。二级缓存的数据更新策略更为复杂,需要考虑并发和一致性问题,比如当某个SqlSession修改了数据,需要通知其他SqlSession刷新对应的二级缓存。
总结来说,MyBatis的查询缓存机制通过一级和二级缓存,有效减少了对数据库的访问次数,提高了应用的响应速度。一级缓存适用于单个SqlSession内的高效重复查询,而二级缓存则用于跨会话的缓存需求。理解并合理利用这两个层次的缓存,对于优化MyBatis应用的性能至关重要。
MyBatis查询缓存实例详解查询缓存实例详解
查询缓存的使用,主要是为了提高查询访问速度。这篇文章主要介绍了MyBatis查询缓存,需要的朋友可以参考下
查询缓存的使用,主要是为了提高查询访问速度。将用户对同一数据的重复查询过程简化,不再每次均从数据库查询获取结果
数据,从而提高访问速度。
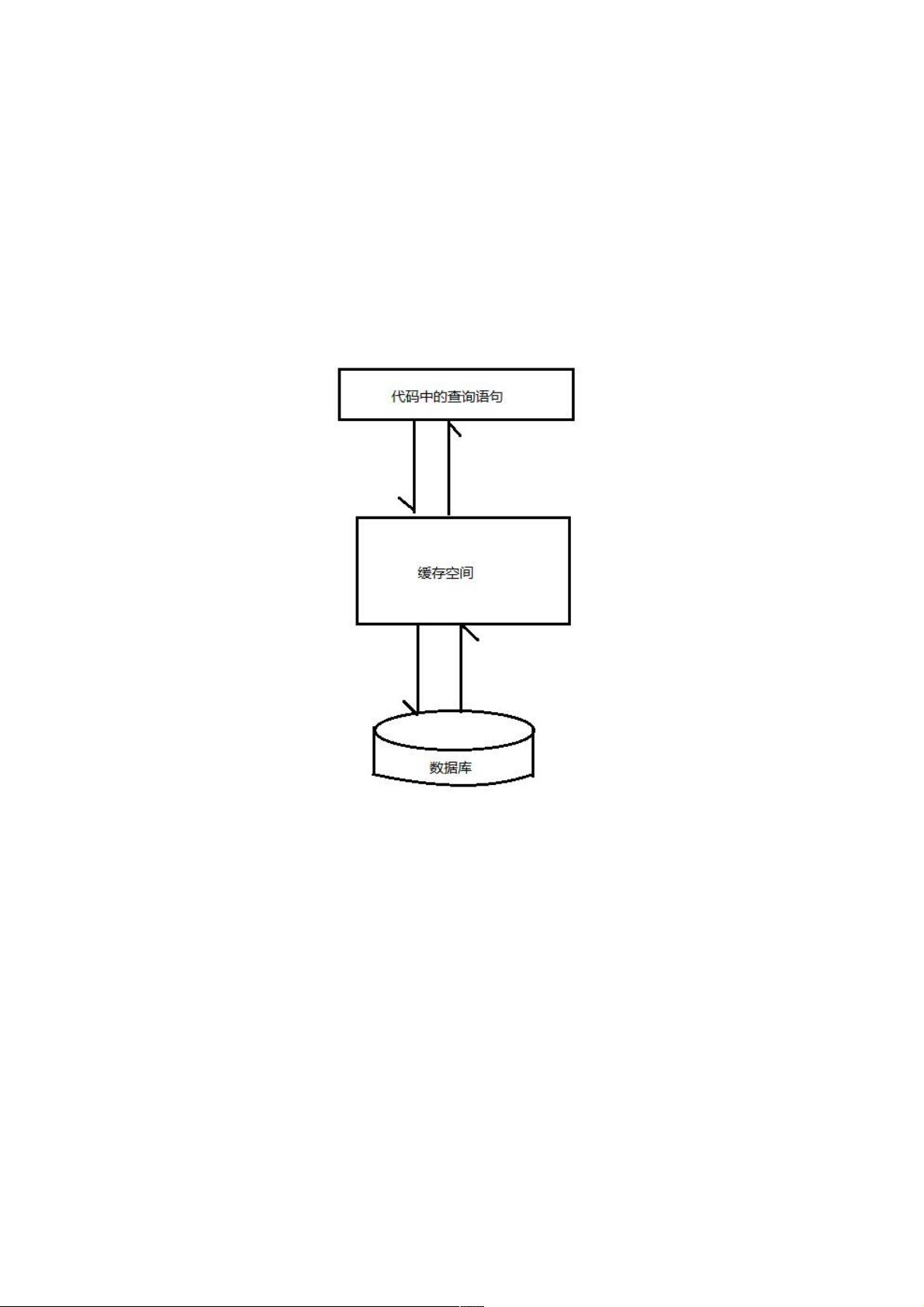
MyBatis的查询缓存机制,根据缓存区的作用域(生命周期)可划分为两种:一级缓存与二级缓存
一、一级查询缓存一、一级查询缓存
MyBatis一级缓存是基于org.apache.ibatis.cache.impl.PerpetualCache类的HashMap本地缓存,其作用域是Sqlsession。在同
一个Sqlsession中两次执行相同的sql语句,第一次执行完毕后,会将查询结果写入到缓存中,第二次会从缓存中直接获取数
据,而不再到数据库中进行查询,从而提高查询效率。
当一个Sqlsession结束后,该Sqlsession中的一级缓存也就不存在了。MyBatis默认一级缓存是开启状态,且不能关闭。
1.一级缓存的存在性证明一级缓存的存在性证明
测试类:
//证明一级缓存的存在
@Test
public void test01(){
//第一次查询
Student student = dao.selectStudentById(2);
System.out.println(student);
//第二次查询
Student student2 = dao.selectStudentById(2);
System.out.println(student2);
}
mapper:
<mapper namespace="com.hcx.dao.IStudentDao">
<select id=selectStudentById resultType="com.hcx.beans.Student">
select * from student where id=#{id}
</select>
</mapper>
控制台:
执行完后,发现只执行了一次从DB中的查询,第二次的结果是直接输出的。说明,第二次是从Sqlsession缓存中读取的。
下载后可阅读完整内容,剩余6页未读,立即下载
2020-09-01 上传
2017-09-29 上传
2020-08-29 上传
2020-08-28 上传
2020-09-09 上传
2020-08-28 上传
2019-04-07 上传
点击了解资源详情
点击了解资源详情

weixin_38557935
- 粉丝: 0
- 资源: 955
 我的内容管理
展开
我的内容管理
展开







最新资源
- Haskell编写的C-Minus编译器针对TM架构实现
- 水电模拟工具HydroElectric开发使用Matlab
- Vue与antd结合的后台管理系统分模块打包技术解析
- 微信小游戏开发新框架:SFramework_LayaAir
- AFO算法与GA/PSO在多式联运路径优化中的应用研究
- MapleLeaflet:Ruby中构建Leaflet.js地图的简易工具
- FontForge安装包下载指南
- 个人博客系统开发:设计、安全与管理功能解析
- SmartWiki-AmazeUI风格:自定义Markdown Wiki系统
- USB虚拟串口驱动助力刻字机高效运行
- 加拿大早期种子投资通用条款清单详解
- SSM与Layui结合的汽车租赁系统
- 探索混沌与精英引导结合的鲸鱼优化算法
- Scala教程详解:代码实例与实践操作指南
- Rails 4.0+ 资产管道集成 Handlebars.js 实例解析
- Python实现Spark计算矩阵向量的余弦相似度
