Hadoop 3 HDFS集群搭建教程与端口详解
76 浏览量
更新于2024-08-30
收藏 628KB PDF 举报
在本篇Hadoop3自学入门笔记中,主要探讨了Hadoop 3的HDFS分布式搭建,包括Hadoop 2与Hadoop 3之间的端口区别,以及具体的集群架构设置。首先,文章强调了理解不同版本Hadoop的端口差异,这对于集群管理至关重要,例如Hadoop 3中的NameNode可能使用新的端口配置,如Second NameNode的存在。
集群规划部分列出了四台机器的IP地址和角色分配:
1. NameNode和DataNode合一的节点(192.168.3.61),扮演核心数据管理和存储的角色。
2. DataNode(192.168.3.62)负责数据的存储副本。
3. Second NameNode(192.168.3.63),虽然不是必需的,但在大型集群中可提高容错性和性能。
4. 另一个DataNode(192.168.3.64),增加系统的冗余性。
接下来,作者详细介绍了集群的安装步骤:
- 安装JDK:通过SFTP上传并解压JDK到指定路径,并配置环境变量JAVA_HOME和PATH,确保系统能够识别Java环境。
- SSH免密登录配置:虽然未在文中提供具体步骤,但这是部署Hadoop时常见的安全设置,确保后续操作便捷。
- 配置Hadoop:通过SFTP下载Hadoop 3.2.1的tar.gz包,然后进行解压。Hadoop配置涉及到几个关键文件,如hadoop-env.sh、core-site.xml、hdfs-site.xml和workers,这些文件分别用于设置运行环境变量、核心配置、HDFS特定配置以及定义工作节点。
在配置过程中,会涉及以下步骤:
- 修改hadoop-env.sh,设置必要的环境变量,如JAVA_HOME和HADOOP_HOME。
- 更新core-site.xml,配置Hadoop的基本参数,如Hadoop的命名空间和副本因子等。
- 配置hdfs-site.xml,调整HDFS的高级特性,如数据块大小、副本策略等。
- 在workers文件中指定DataNode节点,以帮助Hadoop管理数据分布。
此外,文章还提到格式化HDFS,这是在集群首次部署或重大更改后必须执行的步骤,以创建或更新HDFS的元数据。最后,启动Hadoop服务,并通过浏览器访问HDFS的WebUI来验证集群是否成功搭建。
总结来说,这篇笔记提供了Hadoop 3 HDFS分布式集群的搭建步骤,包括基础环境的准备、配置文件的修改、HDFS的初始化以及服务的启动,对于想要学习和实践Hadoop 3的人来说是一份实用的指南。
hadoop3自学入门笔记自学入门笔记(2)—— HDFS分布式搭建分布式搭建
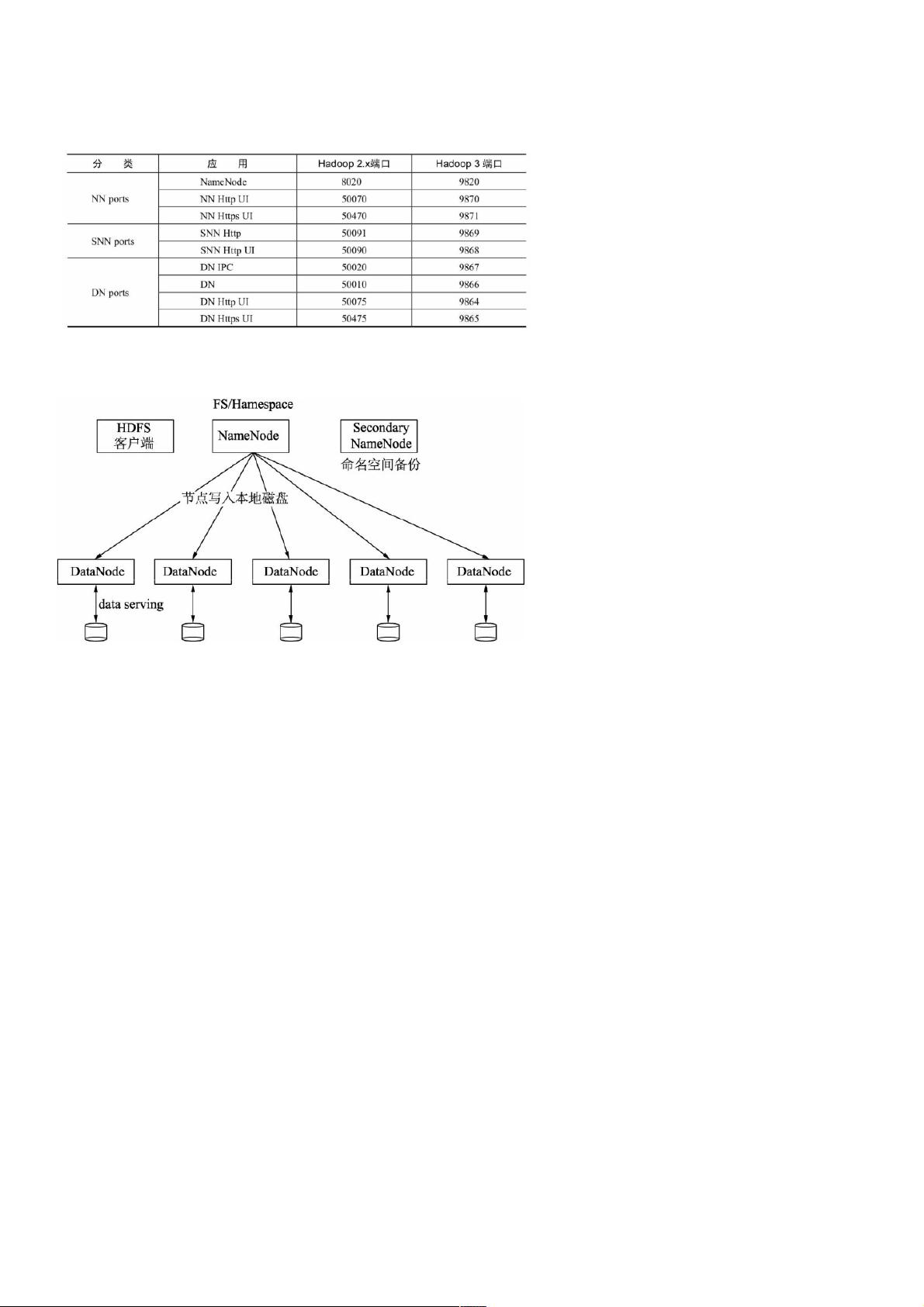
目录目录一些介绍Hadoop 2和Hadoop 3的端口区别Hadoop 3 HDFS集群架构我的集群规划1.安装JDK2.配置Hadoop2.1部署及配置2.2 将配置复制到其他服务器2.3配置下hadoop的环境
变量,方便输入命令2.4格式化3.启动4.打开浏览器查看HDFS监听页面参考书籍
一些介绍一些介绍
Hadoop 2和和Hadoop 3的端口区别的端口区别
Hadoop 3 HDFS集群架构集群架构
我的集群规划我的集群规划
name ip role
61 192.168.3.61
namenode,
datanode
62 192.168.3.62 datanode
63 192.168.3.63 secondnamenode
64 192.168.3.64 datanode
1.安装安装JDK
利用FileZilla sftp功能进行上传到指定文件夹下/root/software,下图是配置sftp.
下载后可阅读完整内容,剩余4页未读,立即下载
416 浏览量
432 浏览量
249 浏览量
117 浏览量
163 浏览量
2021-04-18 上传
285 浏览量
163 浏览量
147 浏览量

weixin_38530202
- 粉丝: 2
- 资源: 876
 我的内容管理
展开
我的内容管理
展开







