
ELK构建云时代的构建云时代的logging解决方案解决方案
一、概述
随着现在各种软件系统的复杂度越来越高,特别是部署到云上之后,再想登录各个节点上查看各个模块的log,基本是不可行
了。因为不仅效率低下,而且有时由于安全性,不可能让工程师直接访问各个物理节点。而且现在大规模的软件系统基本都采
用集群的部署方式,意味着对每个service,会启动多个完全一样的POD对外提供服务,每个container都会产生自己的log,仅
从产生的log来看,你根本不知道是哪个POD产生的,这样对查看分布式的日志更加困难。
所以在云时代,需要一个收集并分析log的解决方案。首先需要将分布在各个角落的log收集到一个集中的地方,方便查看。收
集了之后,还可以进行各种统计分析,甚至用流行的大数据或maching learning的方法进行分析。当然,对于传统的软件部署
方式,也需要这样的log的解决方案,不过本文主要从云的角度来介绍。
ELK就是这样的解决方案,而且基本就是事实上的标准。ELK是三个开源项目的首字母缩写,如下:
E: Elasticsearch
L: LogStash
K: Kibana
LogStash的主要作用是收集分布在各处的log并进行处理;Elasticsearch则是一个集中存储log的地方,更重要的是它是一个全
文检索以及分析的引擎,它能让用户以近乎实时的方式来查看、分析海量的数据。Kibana则是为Elasticsearch开发的前端
GUI,让用户可以很方便的以图形化的接口查询Elasticsearch中存储的数据,同时也提供了各种分析的模块,比如构建
dashboard的功能。
我个人认为将ELK中的L理解成Logging Agent更合适。Elasticsearch和Kibana基本就是存储、检索和分析log的标准方案,而
LogStash则并不是唯一的收集log的方案,Fluentd和Filebeats也能用于收集log。所以现在网上有ELK,EFK之类的缩写。
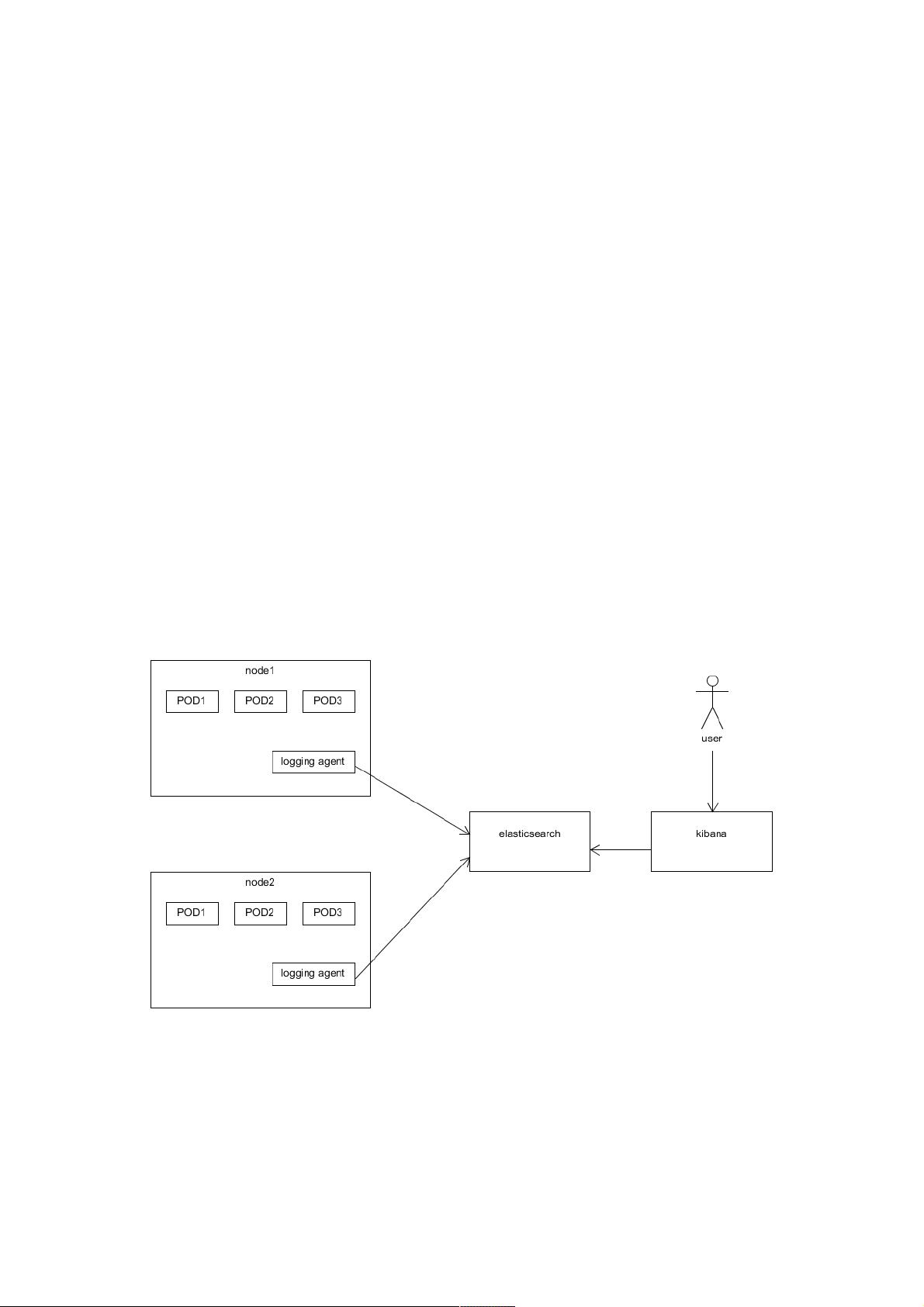
一般采用的架构如下图所示。通常一个小型的cluster有三个节点,在这三个节点上可能会运行几十个甚至上百个容器。而我们
只需要在每个节点上启动一个logging agent的实例(在kubernetes中就是DaemonSet的概念)即可。
二、Filebeats、LogStash、Fluentd三者的区别和联系
这里有必要对Filebeats、LogStash和Fluentd三者之间的联系和区别做一个简要的说明。Filebeats是一个轻量级的收集本地log
数据的方案,官方对Filebeats的说明如下。可以看出Filebeats功能比较单一,它仅仅只能收集本地的log,但并不能对收集到
的Log做什么处理,所以通常Filebeats通常需要将收集到的log发送到Logstash做进一步的处理。
Filebeat is a log data shipper for local files. Installed as an agent on your servers, Filebeat monitors the log directories or
specific log files, tails the files, and forwards them either to Elasticsearch or Logstash for indexing
LogStash和Fluentd都具有收集并处理log的能力,网上有很多关于二者的对比,提供一个写得比较好的文章链接如下。功能上
二者旗鼓相当,但LogStash消耗更多的memory,对此LogStash的解决方案是使用Filebeats从各个叶子节点上收集log,当然
Fluentd也有对应的Fluent Bit。
下载后可阅读完整内容,剩余3页未读,立即下载

weixin_38750644
- 粉丝: 5
- 资源: 907
 我的内容管理
展开
我的内容管理
展开







最新资源
- OptiX传输试题与SDH基础知识
- C++Builder函数详解与应用
- Linux shell (bash) 文件与字符串比较运算符详解
- Adam Gawne-Cain解读英文版WKT格式与常见投影标准
- dos命令详解:基础操作与网络测试必备
- Windows 蓝屏代码解析与处理指南
- PSoC CY8C24533在电动自行车控制器设计中的应用
- PHP整合FCKeditor网页编辑器教程
- Java Swing计算器源码示例:初学者入门教程
- Eclipse平台上的可视化开发:使用VEP与SWT
- 软件工程CASE工具实践指南
- AIX LVM详解:网络存储架构与管理
- 递归算法解析:文件系统、XML与树图
- 使用Struts2与MySQL构建Web登录验证教程
- PHP5 CLI模式:用PHP编写Shell脚本教程
- MyBatis与Spring完美整合:1.0.0-RC3详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


