分布式网络爬虫设计:多线程与Nanomsg实现
版权申诉
92 浏览量
更新于2024-08-04
收藏 287KB PDF 举报
本文档是一份关于分布式网络爬虫的设计毕业设计,由刘祎睿、陈蔚瀚和李嘉共同完成。研究的目的是开发一个高效能的分布式爬虫,能够从给定的网址中分析URL并爬取网页,同时支持分布式爬取并记录网页大小,利用多线程技术提高性能。
实验目标包括:
1. 分析指定网站的URL,爬取所有不重复的网页。
2. 实现分布式爬取,实时记录网页大小。
3. 基于多线程结构设计,确保高并发和性能优化。
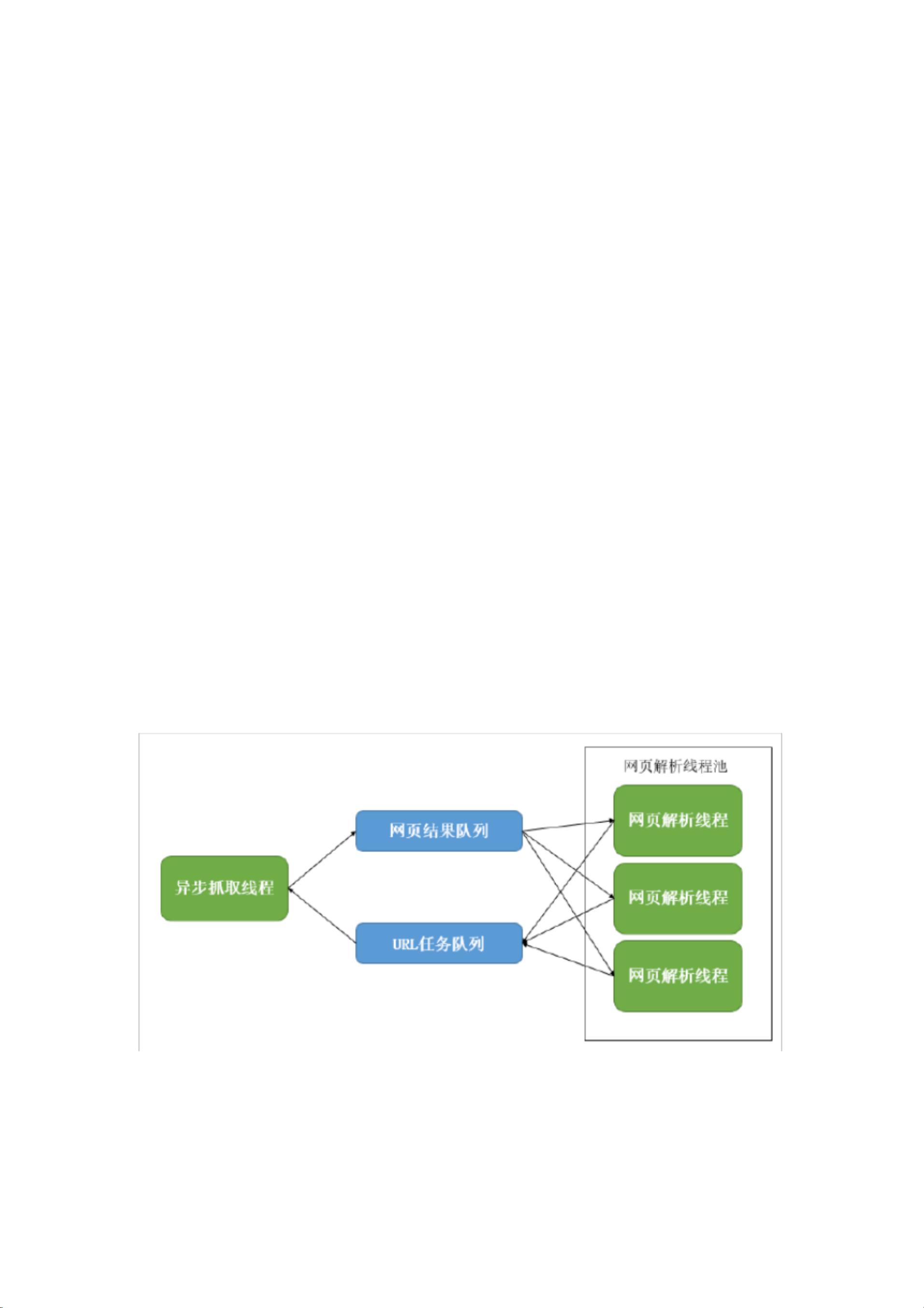
整体架构设计采用主线程、异步抓取线程和网页解析线程的协作。主线程负责创建异步抓取线程和网页解析线程池,而这两个核心线程通过Nanomsg的轻量级消息队列(Pipeline模式)进行通信。异步抓取线程通过Libevent库的Reactor模型实现,通过register的receiveResponse_cb和eventcb事件来管理网络连接、请求发送和响应接收。当接收到数据时,线程会从URL任务队列中获取新的URL进行抓取,然后将网页内容放入结果队列。
网页解析线程则负责从网页结果队列提取网页,进一步分析其中的URL,并将有效URL放入任务队列中,形成一个持续的抓取与解析循环。解析部分主要针对HTML语言,使用有限状态自动机技术提取其中的链接。
文档详细介绍了系统的核心实现技术,如异步网络通信、多线程处理以及HTML解析,展示了如何通过这些技术构建一个功能强大且高效的分布式网络爬虫。
分布式网络爬虫设计文档
刘祎睿陈蔚瀚李嘉
一、实验目标:
本次实验目标为设计一个分布式网络爬虫实现一下功能:
1. 从一个给定的网址中分析其所包含的 URL并爬取对应的网页, 直到爬取完全部不重复的
网页为止。
2. 支持分布式爬取,同时记录输出每一个网页的大小。
3. 采用多线程结构设计,实现高性能的网络爬虫。
二、整体架构设计:
本系统整体架构如下图, 由主线程、 异步抓取线程、 网页解析线程三类线程构成, 其中,
网页分析线程由网页分析线程池统一分配调度。线程间的通信由网页结果队列和 URL 人任
务队列负责,两个消息队列由轻量级消息队列 Nanomsg 创建采用 Pipeline 模式。主线程主
要负责异步抓取线程和网页解析线程池的创建。异步抓取线程主要负责从 URL 任务队列中
获取网页网址,然后完成网页的 Socket 抓取,并将得到的网页存入网页结果队列中。网页
解析线程池主要负责分配网页解析线程从网页结果队列提取网页进行分析。 网页解析线程主
要负责从网页内容中提取出有效的 URL并存入 URL任务队列。
下载后可阅读完整内容,剩余3页未读,立即下载
2022-11-05 上传
2022-07-10 上传
2022-06-17 上传
2022-11-26 上传
2021-07-04 上传
2021-07-04 上传
2021-12-05 上传
2022-06-28 上传
2022-11-25 上传

小虾仁芜湖
- 粉丝: 105
- 资源: 9352
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
