特征提取攻略:Kaggle实战与常用技巧
需积分: 9 103 浏览量
更新于2024-07-17
1
收藏 14.08MB PDF 举报
"特征提取漫游指南:Kaggle和日常工作的一些技巧和代码"
特征提取是机器学习模型的关键环节,它涉及到领域知识、创新思维以及大量的时间投入。本文作者Rahul Agarwal分享了他在特征创建过程中的经验和技巧,包括自动化和手动的方法,处理分类特征的不同方式,以及如何利用经度和纬度特征等。此外,他还介绍了在Kaggle竞赛中的一些实用策略,并提供了关于特征工程的思考。
1. 自动化特征创建:使用featuretools库
featuretools是一个用于自动特征工程的框架,尤其擅长处理时序和关系型数据集。通过这个库,可以将数据库中的多张表转换为适合机器学习的特征矩阵。以一个简单的例子来说明,假设我们有三个数据库表格:Customers(客户)、Sessions(会话)和Transactions(交易)。featuretools可以帮助我们根据这些表格之间的关系自动生成新的特征,如客户的平均交易金额、会话持续时间等。
2. 手动特征创建
虽然自动化工具可以极大地提高效率,但手动特征工程仍然很重要,因为它允许开发者结合领域知识创造更有针对性的特征。例如,对于时间序列数据,可以创建基于时间的特征,如时间间隔、星期几、季度等;对于文本数据,可以进行词频统计或TF-IDF变换。
3. 处理分类特征
分类特征的处理通常涉及编码,如独热编码(one-hot encoding)、序数编码或者使用目标编码(target encoding)。对于高维的分类特征,可以考虑使用类别重要性(category importance)或降维技术,如主成分分析(PCA)。
4. 经度和纬度特征
地理位置信息可以转化为距离特征,比如计算两个地点之间的欧氏距离或曼哈顿距离,这在分析地理位置相关的模式时非常有用。还可以考虑计算点与特定区域(如城市中心)的距离。
5. Kaggle竞赛中的技巧
在Kaggle竞赛中,理解数据集、进行数据预处理、构建基准模型、特征选择和模型融合是常见的策略。Kaggle大神们还会利用交叉验证来优化模型性能,并经常参与讨论区,从他人的见解中获取灵感。
6. 其他特征创建的想法
持续探索数据,寻找隐藏的相关性和模式。可以尝试使用时间序列分解、特征交互(feature interactions)或者基于深度学习的方法如自动编码器(autoencoders)来发现潜在的特征表示。
这篇帖子提供了一系列实用的特征工程方法和技巧,无论是在Kaggle竞赛还是日常工作中,都能帮助提升模型的性能和预测能力。通过自动化的工具和创新的手动特征工程,我们可以更好地挖掘数据的潜力,从而构建更强大的机器学习模型。
featuretools.variable_types.variable.LatLong,
featuretools.variable_types.variable.ZIPCode,
featuretools.variable_types.variable.IPAddress,
featuretools.variable_types.variable.EmailAddress,
featuretools.variable_types.variable.URL,
featuretools.variable_types.variable.PhoneNumber,
featuretools.variable_types.variable.DateOfBirth,
featuretools.variable_types.variable.CountryCode,
featuretools.variable_types.variable.SubRegionCode,
featuretools.variable_types.variable.FilePath]
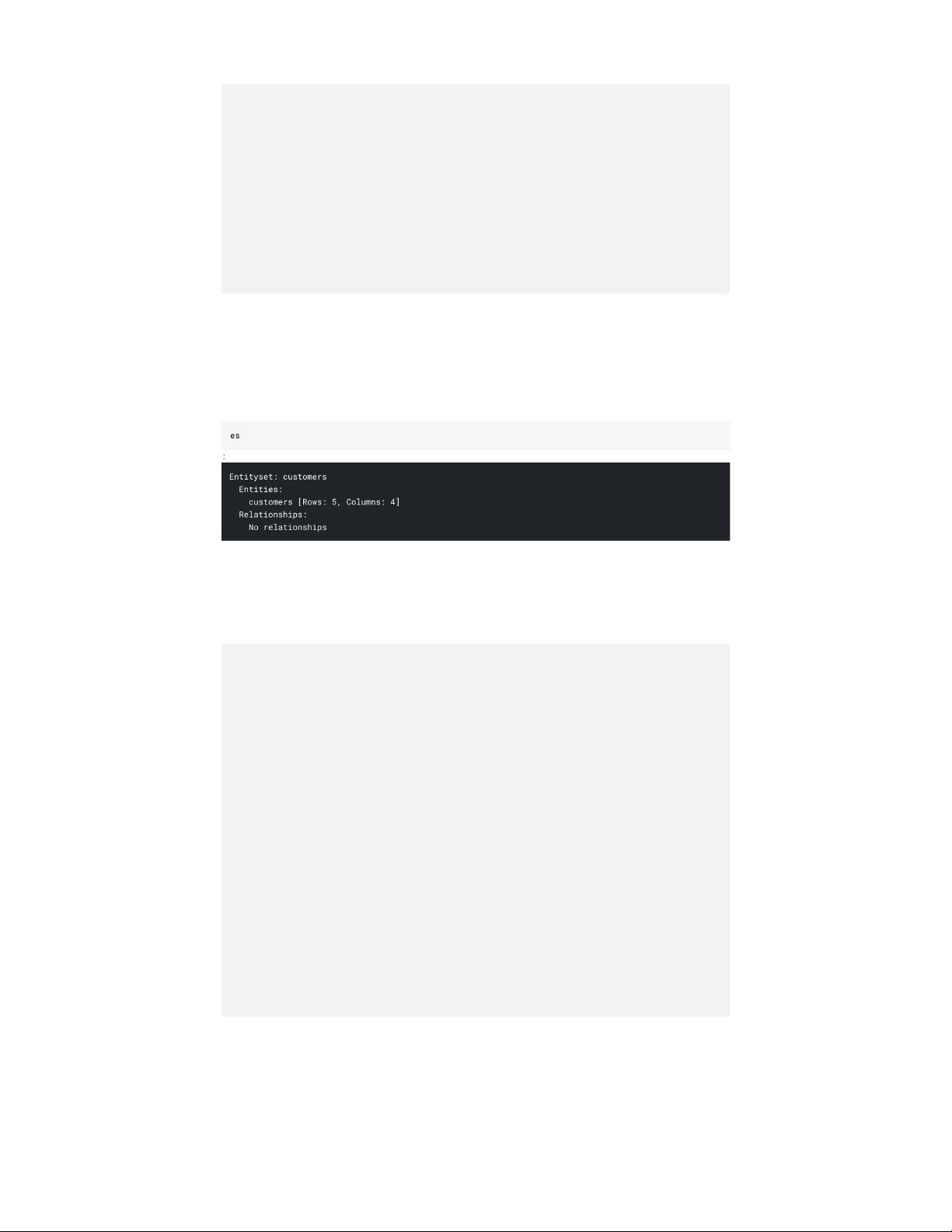
This is how our entityset bucket looks right now. It has just got one
dataframe in it. And no relationships
Let us add all our dataframes:
# adding the transactions_df
es =
es.entity_from_dataframe(entity_id="transactions",
dataframe=transactions_df,
index="transaction_id",
time_index="transaction_time",
variable_types=
{"product_id": ft.variable_types.Categorical})
# adding sessions_df
es = es.entity_from_dataframe(entity_id="sessions",
dataframe=sessions_df,
index="session_id", time_index =
'session_start')
This is how our entityset buckets look now.
剩余27页未读,继续阅读
2021-05-22 上传
2021-06-05 上传
2021-06-18 上传
2021-03-09 上传
2021-06-10 上传
2021-04-15 上传
2021-02-13 上传

tox33
- 粉丝: 64
- 资源: 304
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
