"支持向量机II:非可分情况下的支持向量总结"
需积分: 0 39 浏览量
更新于2024-03-22
收藏 3.44MB PDF 举报
In the second part of the Support Vector Machine, the concept of support vectors in the non-separable case is discussed. Support vectors are defined as the training examples (x(i), y(i)) for which the corresponding α∗i is greater than 0. The KKT dual complementarity condition is also revisited, where α∗i gi(ω∗) = 0 and η∗i ξi = 0 are the key equations. This condition implies that if α∗i = 0, then y(i)(w∗Tx(i) - b) - 1 ξi = 0 and η∗i ξi = 0.
Support vectors play a critical role in the SVM algorithm, especially in cases where the data is not linearly separable. These support vectors are the data points that lie closest to the decision boundary and have a non-zero α∗i value. By focusing on the support vectors, the SVM algorithm is able to effectively find the optimal hyperplane that maximizes the margin between classes.
Overall, the understanding and identification of support vectors are essential in the successful implementation of Support Vector Machine in both separable and non-separable cases. By leveraging the support vectors and the KKT dual complementarity condition, the SVM algorithm is able to accurately classify data points and make predictions with high accuracy.
Intuitions of Kernel I: Non-Linear Support Vector Machine
The primal optimization problem:
min
ω,b
1
2
kωk
2
2
+ C
n
X
i=1
ξ
i
s.t. y
(i)
(ω
T
x
(i)
+ b) ≥ 1 −ξ
i
, i = 1, ··· , n,
ξ
i
≥ 0, i = 1, ··· , n.
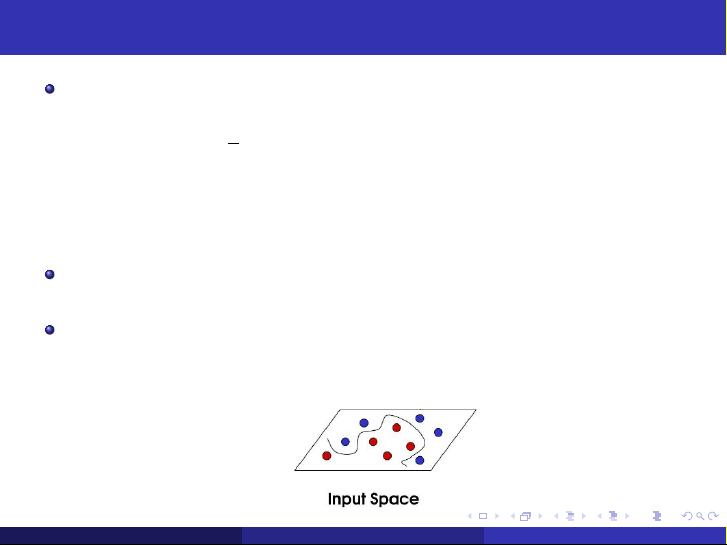
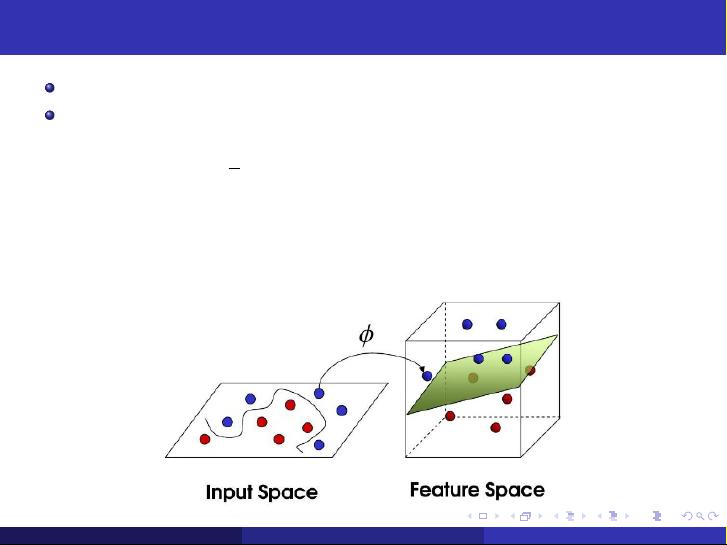
Nonlinear Separable: if we can use a hypersurface to correctly
separate the positive and negative examples.
But the nonlinear problem is usually not easy to solve. Therefore, a
typical method is to transform the nonlinear problem to a linear
problem. Then we can use linear techniques to solve it.
Yanyan Lan (ICT, CAS) Support Vector Machine II November 19, 2017 10 / 57
剩余53页未读,继续阅读
2019-07-11 上传
2022-08-03 上传
2021-10-12 上传
点击了解资源详情
2015-09-22 上传
2020-12-18 上传
2018-07-13 上传
2021-09-28 上传

无声远望
- 粉丝: 873
- 资源: 298
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
