"基于内存的英文全文检索搜索引擎设计和实现"
需积分: 0 86 浏览量
更新于2023-12-26
收藏 4.5MB PDF 举报
CS1807-U201814745-朱槐志
课程名称:Java语言程序设计
实验名称:基于内存的搜索引擎设计和实现
院系:计算机科学与技术
专业班级:CS1807
学号:U201814745
姓名:朱槐志
指导教师:纪俊文
日期:2021年4月8日
面向对象程序设计实验报告
一、需求分析
1. 题目要求
实现一个基于内存的英文全文检索搜索引擎,需要完成以下功能:
功能 1:将指定目录下的一批.txt格式的文本文件扫描并在内存里建立倒排索引,这里面包含必须的子功能包括:
(1)读取文本文件的内容;
(2)将内容切分成一个个的单词;
(3)过滤掉其中一些不需要的单词,例如数字、停用词(the, is and 这样的单词)、过短或过长的单词(例如长度小于3或长度大于20的单词);
(4)利用Java的集合类在内存中建立倒排索引。
2. 需求分析
搜索引擎是一种非常常见的工具,它可以在大量的文本数据中进行快速准确的搜索,因此对于信息检索和文本分析来说,搜索引擎的建立是非常必要的。为了满足这一需求,本实验旨在实现一个基于内存的英文全文检索搜索引擎。为了实现这一目标,首先需要完成对指定目录下的一批.txt格式的文本文件进行扫描,并在内存里建立倒排索引,包括读取文本文件的内容,切分成单词并过滤掉不需要的单词。其次,需要实现基于Java集合类的倒排索引的建立,以完成搜索引擎的核心功能。
二、概要设计
基于需求分析,概要设计将包括以下几个部分:
1. 文本文件扫描模块:负责扫描指定目录下的.txt格式的文本文件,并将内容读取到内存中。
2. 单词切分与过滤模块:将文本文件中的内容切分成一个个的单词,并进行过滤去掉不需要的单词。
3. 倒排索引建立模块:利用Java的集合类在内存中建立倒排索引,实现文本内容到单词的映射关系。
三、详细设计
1. 文本文件扫描模块
在该模块中,需要实现一个文件扫描器,负责扫描指定目录下的.txt格式的文本文件。可以使用Java中的文件操作类,递归地扫描指定目录下的文件,并判断文件格式是否为.txt,然后将文本文件的内容读取到内存中。
2. 单词切分与过滤模块
在该模块中,需要实现对文本文件内容的切分与过滤。可以使用Java中的字符串操作方法,将文本内容按照空格、标点符号等进行切分,得到单词集合。然后对单词集合进行过滤,去掉数字、停用词和长度不符合要求的单词。
3. 倒排索引建立模块
在该模块中,需要利用Java的集合类,如HashMap或TreeMap,建立倒排索引。可以使用单词作为键,将文本文件的内容作为值,建立单词到文本内容的映射关系。这样就可以快速地根据单词查找到包含该单词的文本文件内容。
实验报告到此结束。
面向对象程序设计实验报告
- 7 -
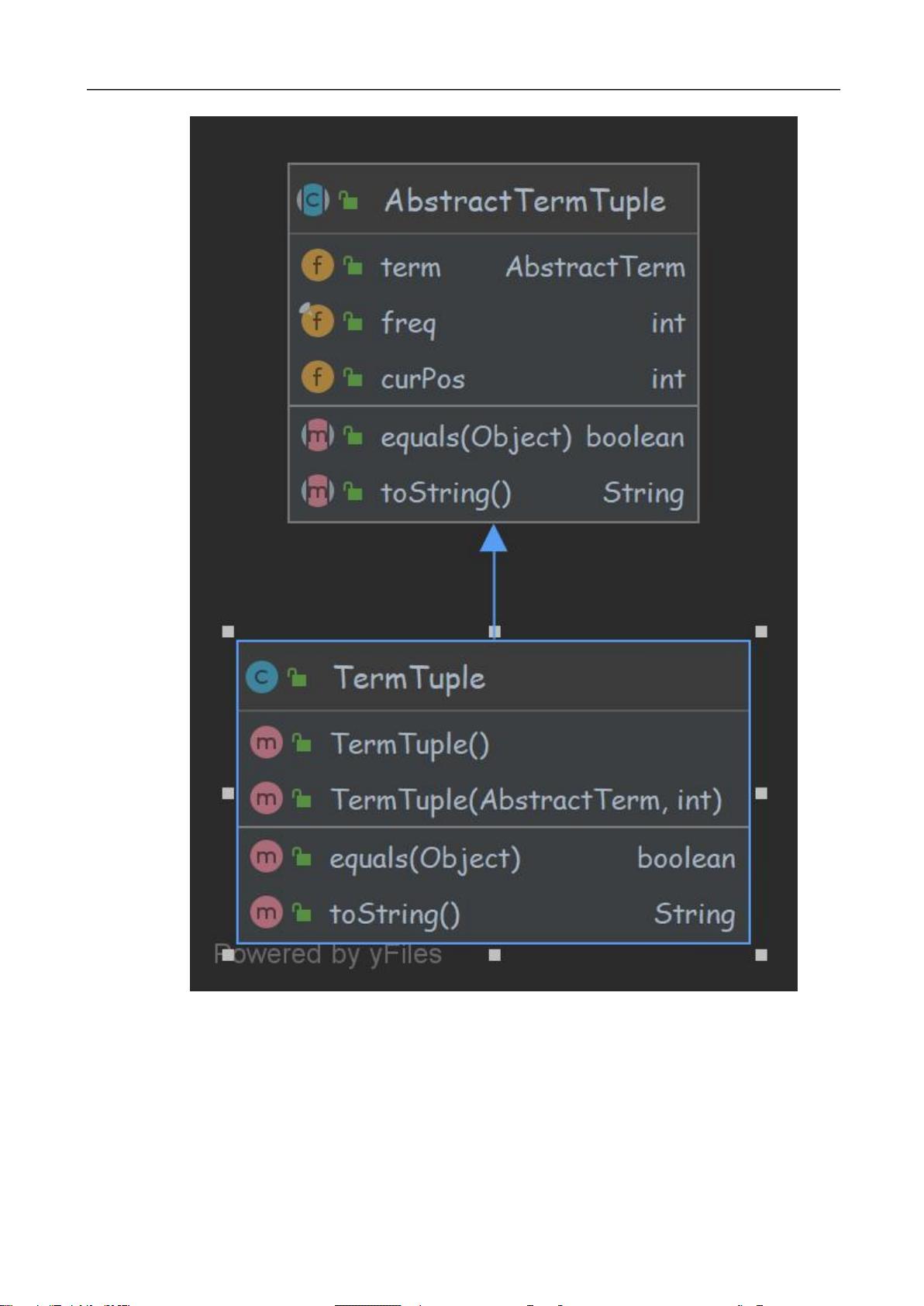
图 2-3 TermTuple 类图
TermTuple 类表示一个单词三元组。数据域包含一个 AbstractTerm 类型的对象
term,以及一个 int 类型的 freq,表示 term.content 出现的次数,默认为 1 和一个 int
类型的 curPos,表示 term.content 出现在文档中的位置。
Equals 方法比较两个 AbstractTermTuple 的数据域内容,如果相等则返回 true;
ToString 方法返回三元组的字符串表示:{Term: , freq: ,curPos: }
3) Posting 类
剩余43页未读,继续阅读
2022-08-08 上传
2022-08-08 上传
2022-08-03 上传
2022-08-03 上传
2022-08-08 上传
2022-08-08 上传
2022-08-03 上传
2022-08-08 上传

鸣泣的海猫
- 粉丝: 25
- 资源: 292
 我的内容管理
展开
我的内容管理
展开







最新资源
- 印度市场入门策略白皮书-白鲸出海-201908.rar
- virgo:调音
- 2014-2020年扬州大学646中国古代史考研真题
- 大一下数据结构实验-图书馆管理系统(基于哈希表).zip
- Excel模板大学社团建设标准表.zip
- amazonia:Map of Interativo do uso da terra daAmazônia
- ember-resolver
- reviewduk:形态丰富的语言中的韩语情感分析器
- 这次大作业是根据课程所学,制作一款数字图像处理系统。该系统基于QT与OpenCv。.zip
- monitor —— logger 日志监控
- script_千年挂黑白捕校_千年
- cicumikuji:nikkanchikuchiku遇见omikuji! https
- Excel模板大学社联财务报表.zip
- loan-simulator
- CSE4010
- pactester:从 code.google.compactester 自动导出
