高可用在线服务:持续演进与策略探索
需积分: 9 98 浏览量
更新于2024-07-18
收藏 5.67MB PPTX 举报
"高可用的在线平台通过不断演进来确保服务稳定性和用户满意度。本文将探讨如何在持续演进的过程中实现高可用性,包括定义高可用性、采取的关键技术和策略,以及不同环境下的巡检与告警机制。"
在当前数字化时代,高可用性(High Availability, HA)是在线服务的基础,它保证了系统能够在预期的工作时间内持续提供服务,即使在硬件故障、网络中断或其他异常情况下也不例外。高可用性不仅仅是系统无故障运行的时间比例,更是一种设计和服务理念,它涵盖了预防、检测、恢复和改进等多方面的策略。
定义高可用性:
高可用性通常通过一个称为“正常运行时间百分比”的指标来衡量,例如99.99%的正常运行时间意味着系统每年只能有5分钟的停机时间。然而,高可用性并不仅仅是数字,它还涉及快速响应和解决故障的能力,以及通过冗余和自动化的机制来减少停机时间和影响。
持续演进中的关键策略:
1. 负载均衡:负载均衡技术是提高在线服务高可用性的核心,它通过分散流量到多个服务器,避免单点故障,保证服务的连续性。可以采用硬件负载均衡器或软件解决方案如Nginx、HAProxy等。
2. 数据库冗余:数据库复制和分片是保持数据一致性和防止数据丢失的重要手段。主从复制可以保证写操作在一个节点上,读操作在多个节点上进行,分片则将大型数据库拆分为更小的部分,分布在多个服务器上。
3. 缓存策略:缓存可以显著提升服务性能并减轻后端系统的压力。使用Redis、Memcached等缓存服务,可以快速响应频繁的读取请求,降低延迟。
4. 容错设计:通过错误检测、自动恢复和故障隔离,确保系统在部分组件故障时仍能继续运行。例如,使用健康检查和心跳机制监控服务状态,一旦发现问题,能够迅速切换到备用资源。
5. 持续集成与持续部署(CI/CD):自动化测试和部署流程可以减少人为错误,快速修复问题,同时确保新功能的稳定发布。
巡检与告警机制:
为了及时发现和处理问题,需要实施全面的巡检与告警系统。这包括在客户环境、办公环境和内部环境设置监控点,定期执行不同频率的检查用例,如每5秒、5分钟或1小时一次。当服务出现异常时,告警系统应立即通知运维人员,以便快速响应。
不同的环境要求不同的监控策略。例如,办公环境可能需要关注员工使用的SpringboardAgentGroup和业务服务的健康状况,开发环境可能侧重于代码质量和测试覆盖率,而运营环境则需要确保生产服务的稳定运行,如BusinessServiceGroup、LogicServiceGroup、CacheGroup和StorageGroup。
智能设备和跨平台支持也是现代在线服务的重要组成部分。无论是H5、PC、智能手机,还是基于Node.js、Windows、iOS或Android的应用,都需要考虑其在不可控情况下的高可用性设计,确保服务在各种设备和平台上都能稳定运行。
总结来说,构建高可用的在线服务平台是一项持续演进的任务,涉及到架构设计、监控、自动化等多个方面。通过不断优化和改进,我们可以提高服务的稳定性和用户体验,以应对日益复杂和变化的互联网环境。
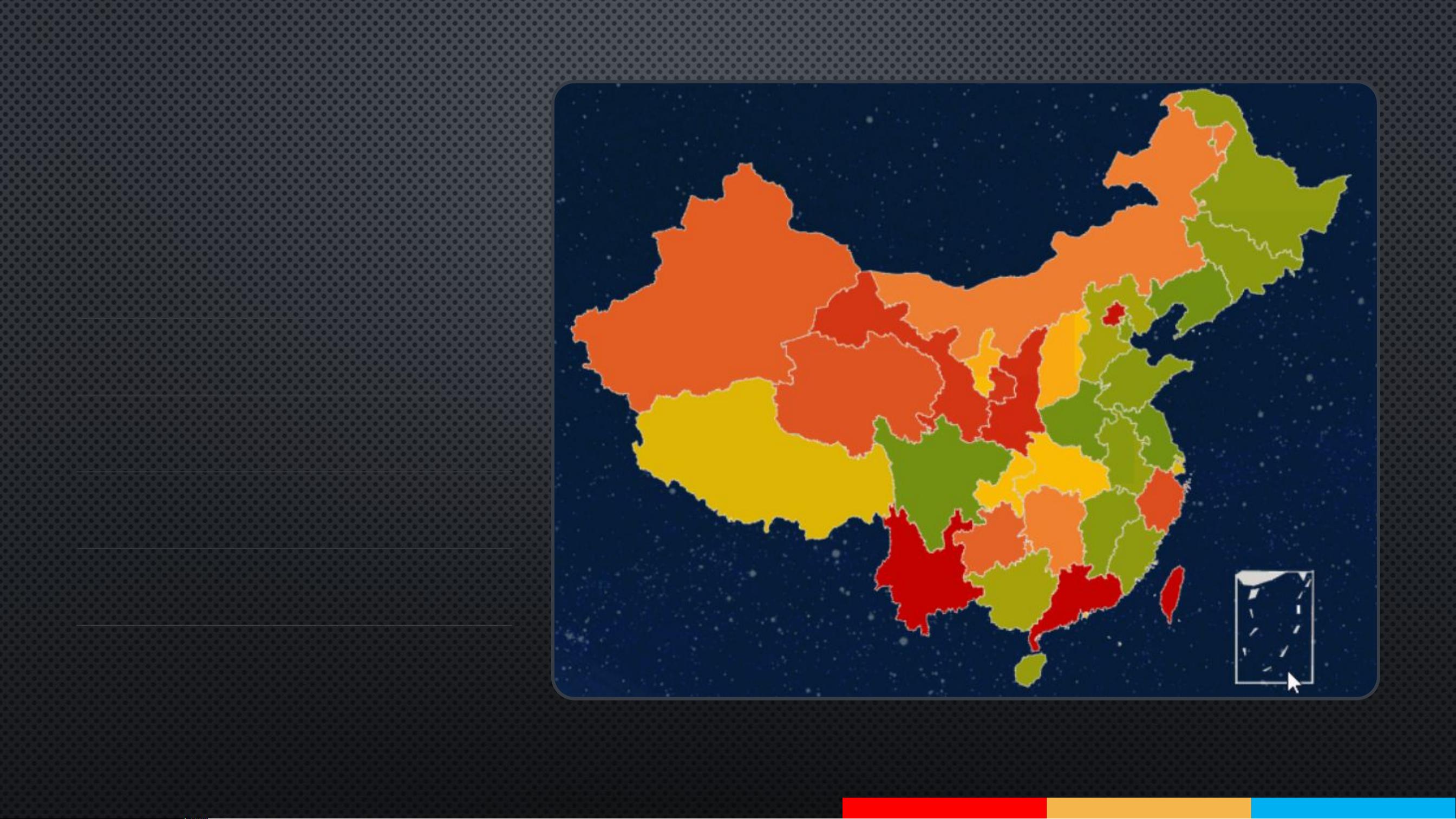
7
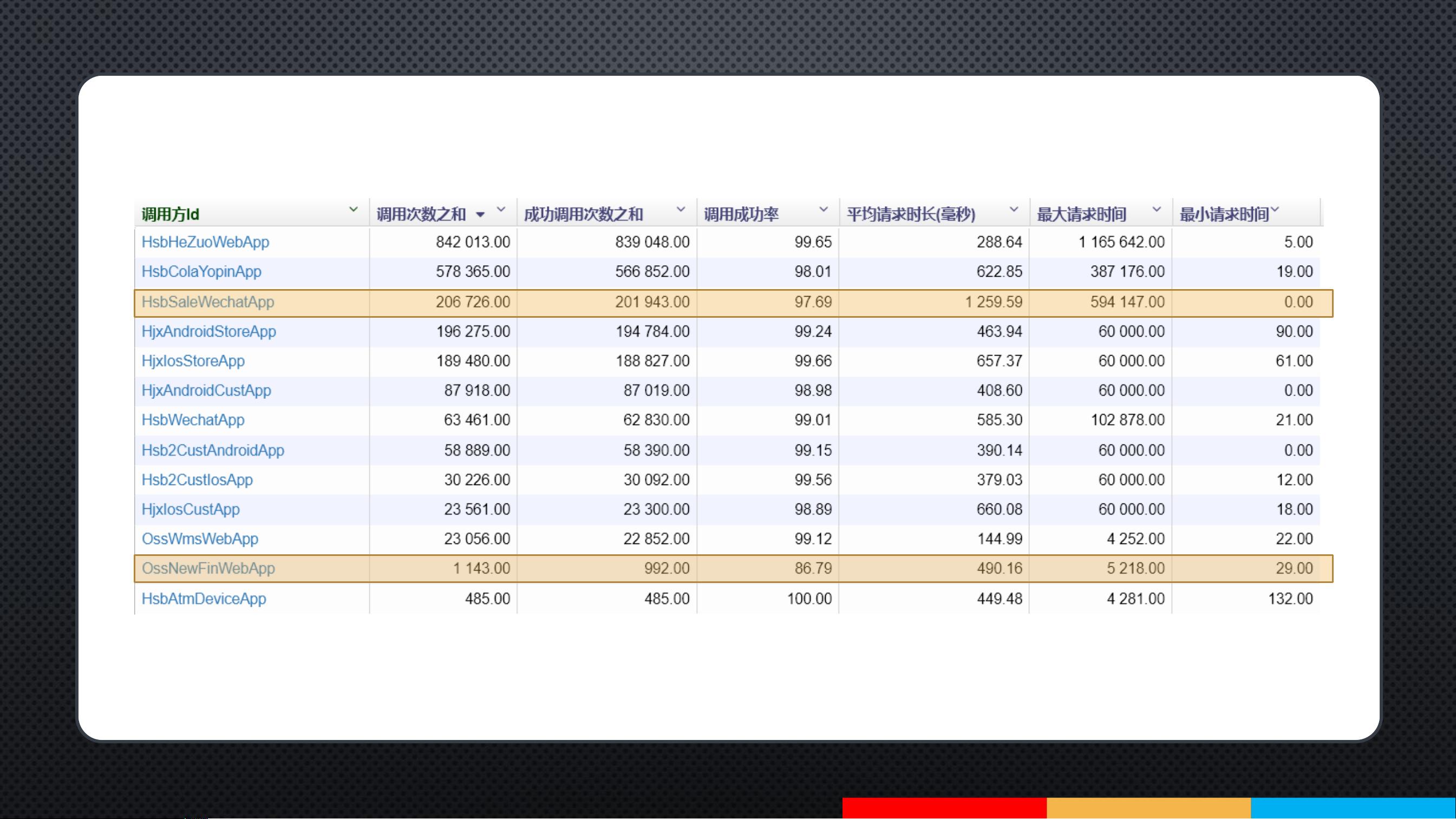
调用量
Call volume
成功率
Success rate
响应时长
Average response time
按地区分布
Regional distribution
形成热力图
Forming a heat map
剩余36页未读,继续阅读
2023-08-02 上传
2023-04-23 上传
2023-03-27 上传
2023-07-08 上传
2023-07-15 上传
2024-08-23 上传

勇哥@物联网
- 粉丝: 10
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
