"数据管道构建:利用Spark和StreamSets解决数据漂移挑战"。
需积分: 5 46 浏览量
更新于2024-03-24
收藏 11MB PDF 举报
The "Building Data Pipelines with Spark and StreamSets" document explores the challenges of data drift in modern data engineering and the solutions provided by StreamSets Data Collector running pipelines on Spark. Data drift refers to the unpredictable, unannounced, and unending mutation of data characteristics caused by system operations, maintenance, and modernization. This poses a significant challenge to data engineers who need to ensure consistency and accuracy in their data pipelines.
StreamSets Data Collector offers a solution to this problem by providing a platform for ingesting, analyzing, and storing data from various sources. It allows for the creation of robust data pipelines that can adapt to changes in data characteristics over time. Running these pipelines on Spark enables faster processing and analysis of large datasets, making it an effective tool for handling data drift.
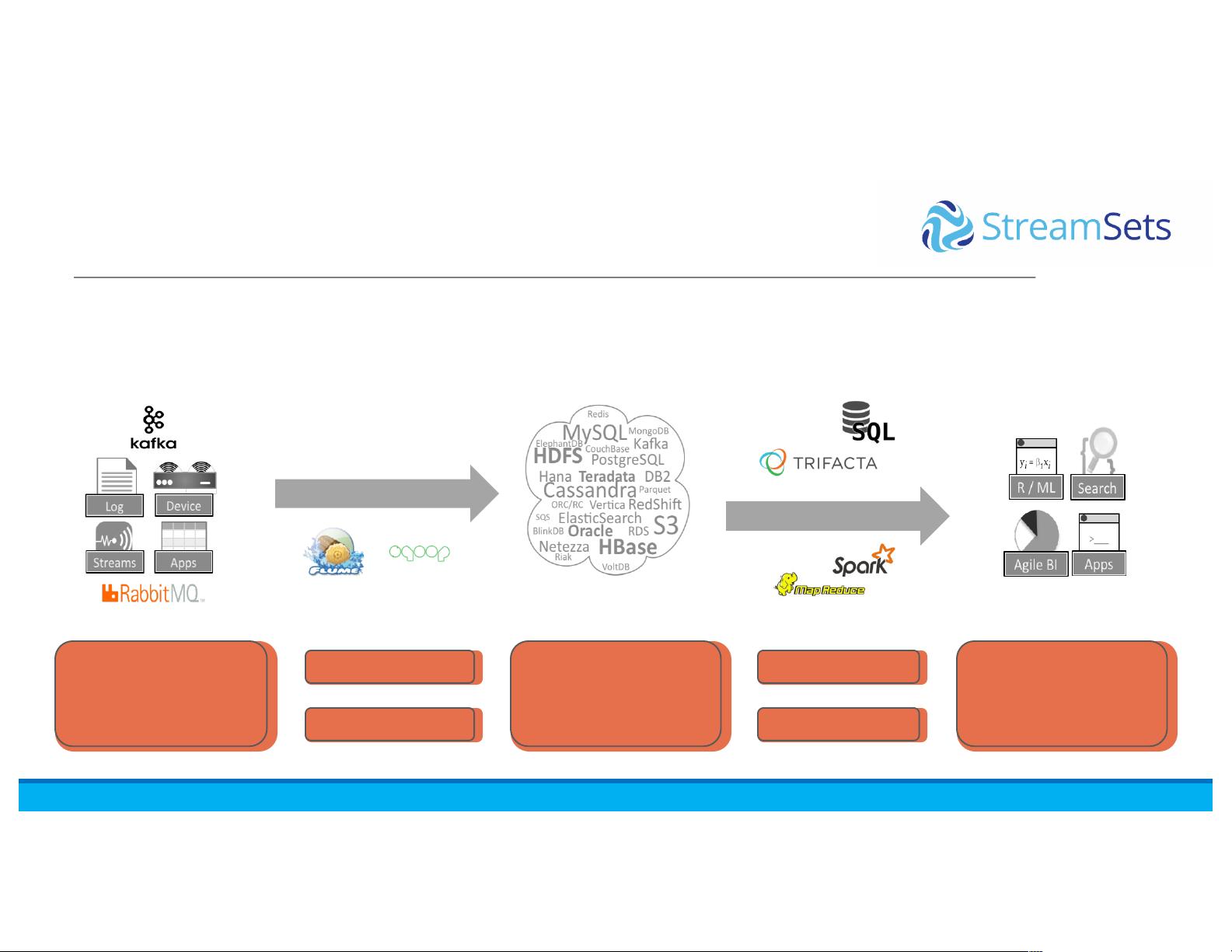
The document outlines the evolution of data-in-motion, from traditional ETL processes to emerging data ingestion and analysis techniques. It emphasizes the importance of building flexible and scalable data pipelines that can accommodate changes in data sources, stores, and consumers.
Overall, "Building Data Pipelines with Spark and StreamSets" provides valuable insights into the challenges of data drift and the solutions offered by StreamSets Data Collector running on Spark. It serves as a comprehensive guide for data engineers looking to build robust and adaptable data pipelines in today's rapidly changing data landscape.
SQL -on-Hadoop-(Hive)
Y/Y-Click-Through-Rate
80%(of(analyst(time( is(spent( preparing( and(validating(data,(
while( the( remaining(20%(is(actual(data(analysis
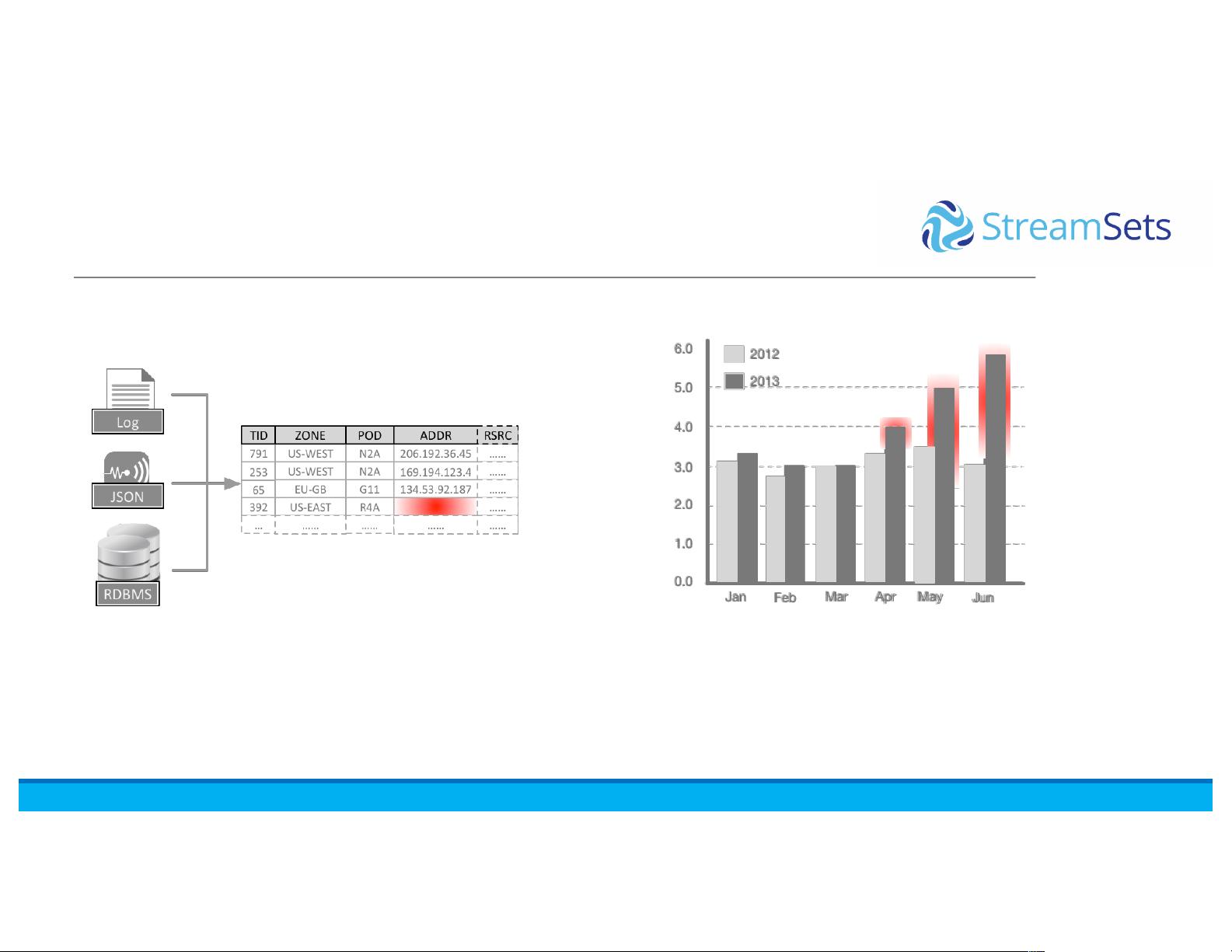
Example:(Data( Loss(and(Corrosion
剩余25页未读,继续阅读
2019-08-28 上传
2023-08-28 上传
2019-12-25 上传
2019-06-08 上传
2020-03-10 上传
2023-09-09 上传
2023-08-26 上传

weixin_40191861_zj
- 粉丝: 86
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- SpringTest:测试一些弹簧功能
- matlab心线代码-EEG-ECG-Analysis:用于简单EEG/ECG数据分析的MATLAB程序
- Stack-C-language-code.rar_Windows编程_Visual_C++_
- 企业名称:Proyecto Reto 2,企业最终要求的软件,企业最终合同的最终目的是在埃塞俄比亚,而在埃塞俄比亚,企业管理者必须是西班牙企业,要求客户报名参加埃洛斯和埃塞俄比亚普埃登的征状,要求参加比赛的男子应征入伍
- bh前端
- scratch-blocks-mod
- hugo-bs-refreshing
- CRC16ForPHP:这是一个符合modbus协议的CRC16校验算法PHP代码的实现
- SnatchBox(CVE-2020-27935)是一个沙盒逃逸漏洞和漏洞,影响到版本10.15.x以下的macOS。-Swift开发
- dep-selector:使用Gecode的Ruby快速依赖解决方案
- clickrup:与R中的ClickUp v2 API交互
- FelCore
- react-markdown-previewer
- ch.rar_通讯编程_Others_
- 图片:允许您向应用提供高度优化的图片
- matlab心线代码-3DfaceHR:基于3D面部界标的基于视频的HR估计项目
