Unicode编码与emoji处理:Utf-8 vs Utf-16的纠结
27 浏览量
更新于2024-08-03
收藏 341KB DOCX 举报
本文主要讨论了编码、乱码以及Unicode字符集的相关概念,特别是在Windows C++编程中的应用。首先,Unicode是一种字符集,为每个字符分配唯一的编码点,旨在解决不同语言字符的统一表示问题。它包括三种压缩编码方式:Utf-8、Utf-16和Utf-32。
Utf-8是一种变长编码,每个字符占用1到4个字节,这种编码方式的优点在于节省空间,尤其对于英文字符,通常只需1字节,但在处理多字节字符如中文或emoji时,需要额外的字节。Utf-16和Utf-32则是固定长度编码,Utf-16每个字符占用2个字节(对于英文字符)或4个字节(对于emoji),而Utf-32每个字符占用4个字节。然而,Utf-16的最初设计是基于当时字符集的局限性,它被当作定长编码,导致在处理新添加的字符和emoji时出现兼容性问题。
由于Utf-16存在大小端(Little Endian和Big Endian)问题,即字节顺序可能因硬件或系统的不同而不同,这可能会导致乱码。而Utf-8的编码规则则消除了字节序的影响。此外,不推荐使用Utf-32,因为它占用空间更大,且同样存在大小端问题。
在C/C++编程中,字符串处理涉及到源代码字符集、编译器字符集和执行字符集的一致性。例如,char类型通常用于单字节字符,wchar_t用于Utf-16,但对扩展字符的支持有限。如果需要处理emoji,可以使用宽字符类型(wchar_t或TCHAR),后者是根据编译器是否定义UNICODE宏进行编译时预编译的。
当在源代码中输入emoji符号时,如果这些字符集不匹配,可能导致终端或文本显示为乱码。为了确保正确显示,开发人员需要确保这三个字符集在编译和执行过程中保持一致或能够相互转换。
总结来说,本文详细讲解了在Windows C++编程中字符集选择的重要性,尤其是在处理不同语言字符和emoji时,开发者需要理解各种编码方式的优缺点,并注意字符集之间的协调,以避免乱码问题的发生。
Unicode、GBK
Utf-8、Utf-16、Utf-32 是 Unicode 的压缩编码方式,Unicode 是一种字符集,为每个字符
一个编码点,GBK 也是一种字符集,但是只包含中文,无法显示 emoji🐟这种符号。
Utf-8 和 Utf-16 都是不定长的编码方式,比如一个字符需要 1 个字节、2 个字节、3 个字节、
4 个字节,不定长意味着无法随机访问,比如一个 char 数组,你无法通过下标来获取到哪
个字母,因为每个字符占有的字节内容是不确定的,需要遍历一遍,做解析,而 utf-16 也
是这样,但是 utf-16 有历史原因,windows 系统,windows 的 api,UE、以及 java 等语言,
内部都用 utf-16,过去还没有 emoji 以及一些新增字符,它们把它当成定长的了,就是一个
字符占用 2 个字节,但是 emoji🐟这种占用 4 个字节,如果把 emoji 放入 utf-16 的数组,通
过下标进行随机访问,会乱掉。
https://www.zhihu.com/question/308677093/answer/2748648048。
这个回答解释了 utf16 的历史原因,大致就是过去人们以为 utf16 相比于 utf8,是由于定长
的,效率很高,而且能表示所有字符,但是后续新增的字符以及 emoji,导致 utf-16 无法表
示。
而且 utf-16 有大小端问题,因为一个字符占有 2 个字节或者 4 个字节(emoji),无法判断一
个字符的后面字节在前,还是在后,但是 utf-8 的编码规则使得它没有字节序问题。
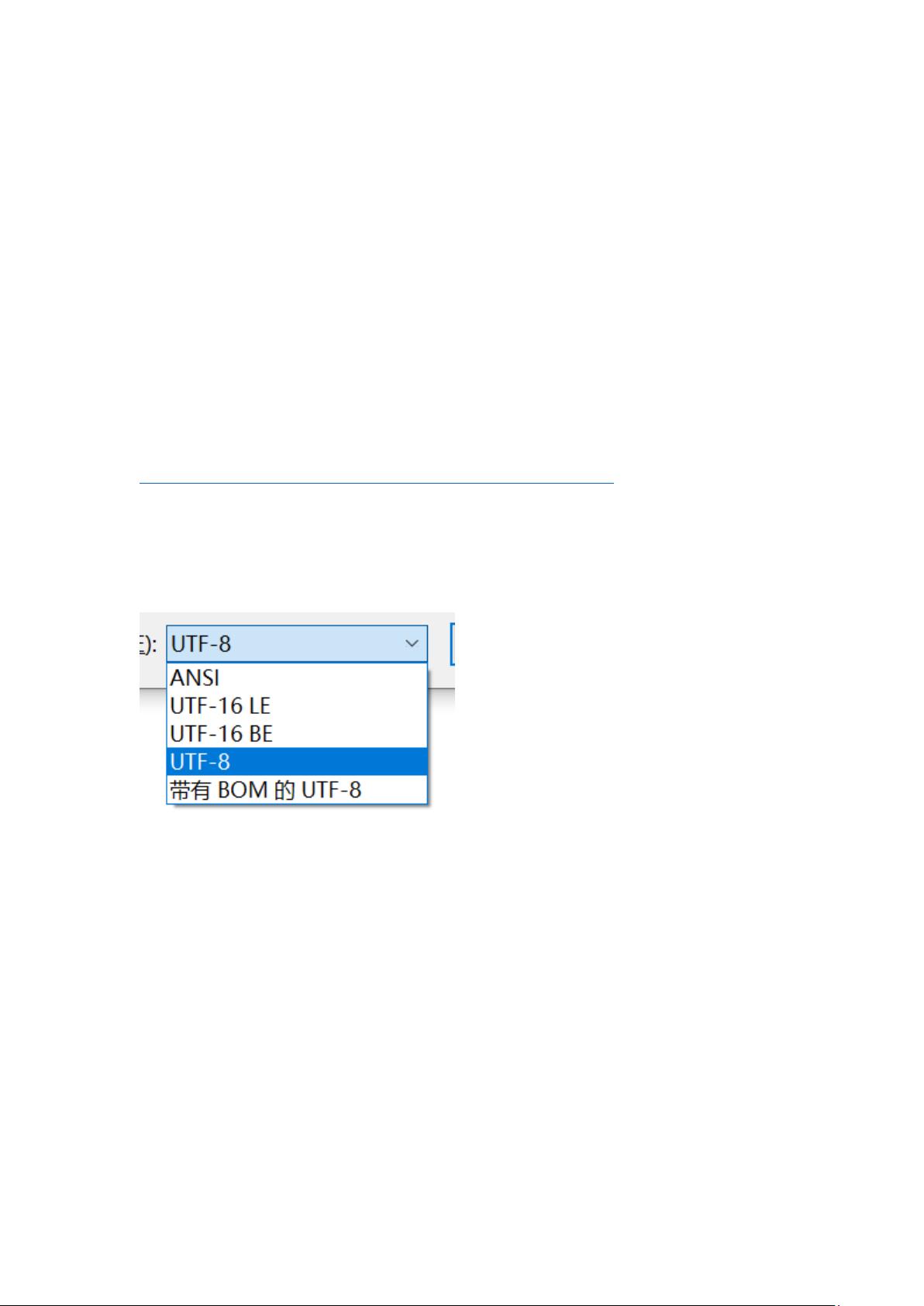
文本的保存这里,LE 表示小端,BE 表示大端,带 BOM 的 UTF-8 后面解释。
不用 utf-32 的原因是,太大了,和 utf-16 一样,有大小端问题。
在源码里面书写一些 emoji 符号,可能在终端或者文本里面是乱码的原因如下:
有 3 种环境,源码字符集,编译器字符集、执行字符集,必须这 3 者都统一,或者可以互
相转换,才能保证编译器编译好的字符串内容输出到终端是正确的。
下载后可阅读完整内容,剩余4页未读,立即下载
2019-09-17 上传
2021-02-03 上传
2021-09-27 上传
2021-09-27 上传
2021-02-04 上传
2021-03-11 上传
2021-09-27 上传

0x0007
- 粉丝: 3692
- 资源: 472
 我的内容管理
展开
我的内容管理
展开







最新资源
- PortafolioAdsi:工业生物技术中心 ADSI 案例研究项目 - Palmira。 软件开发的整个过程将展示实施 Scrum 框架,以同样的方式利用 JAVA、JPA、Mysql、Html5、CSS 等技术
- ISO15118是欧洲的电动汽车充电协议标准,这是第一部分,通用信息及用例定义
- 测试
- teamtool-spring:团队工具(Spring MVC)
- Learners-Academy
- 为桌面和Web应用程序配置Log4Net
- be-kanBAO:后端做看报
- react-redux-flask-mongodb:带有Mongodb的Flask JWT后端和带有Material UI的ReactRedux前端的入门应用程序
- 新的多站点DLL或如何在根目录中开发.NET项目
- fakhrusy.com:我的个人网站
- image-mosaic
- pyg_lib-0.3.0+pt20-cp310-cp310-macosx_11_0_x86_64whl.zip
- N10SG开发教学视频.zip
- Toolint-tests-Empty-TC-Add-Tools-2021-04-07T15-40-16.889Z:为工具链创建
- 122页中国移动互联网2019半年大报告-QuestMobile-2019.7.rar
- practice:练习
