优化实体解析的监督梯度学习算法
需积分: 5 123 浏览量
更新于2024-07-09
收藏 1.3MB PDF 举报
"这篇论文介绍了一种监督学习的梯度基算法,用于优化实体解析任务。作者包括Orion F. Reyes-Galaviza、Witold Pedrycza、Ziyue He、Nick J. Pizzidi等人,分别来自加拿大阿尔伯塔大学、沙特阿拉伯国王阿卜杜拉齐兹大学、波兰科学院系统研究所和加拿大的InfoMagnetics Technologies Corporation。文章重点讨论了概率记录链接(record linkage)即实体解析中的关键问题,如字段选择、比较函数、人工审核阈值和自动链接阈值等,并提出了一种基于梯度下降的决策模型。"
文章的核心内容围绕监督学习算法在优化实体解析中的应用展开。实体解析是将不同数据源中指向同一实体的记录进行匹配和链接的关键任务,对于医疗保健、政府、执法部门以及私营企业等领域具有重要意义,因为它能够整合分散的信息,提高数据质量和分析效率。
在实体解析中,一个主要挑战是如何有效地选择参与比较的字段(field selection),这些字段应当包含能有效区分不同实体的特征。论文中可能探讨了如何通过监督学习来确定哪些字段对识别重复记录最为关键,这通常涉及到特征选择和权重分配。
比较函数(comparison functions)用于评估两个记录之间的相似性,是实体解析过程中的核心组件。该算法可能涉及了多种比较函数,以适应不同类型的数据和不同的相似性度量标准。论文可能会详细阐述如何设计或选择合适的比较函数,以提高匹配的准确性。
此外,人工审核阈值(clerical review threshold)和自动链接阈值(autolink threshold)是控制实体解析过程中的决策边界。前者决定何时需要人工介入,后者则用于自动决定两个记录是否应该被链接。论文可能介绍了如何通过梯度下降方法优化这些阈值,以平衡误匹配和漏匹配的风险。
最后,基于梯度下降的决策模型是论文的核心贡献。梯度下降是一种常用的优化算法,用于最小化损失函数并调整模型参数。在实体解析中,这个模型可能用于学习最佳的比较策略和阈值设置,以最大化正确链接的记录数,同时减少错误链接的发生。
这篇论文深入探讨了实体解析的关键技术和挑战,并提出了一种新的监督学习方法,通过梯度下降优化实体解析过程,提升了数据整合和分析的准确性和效率。
matching process, viz. avoid comparing all records from one source with all records coming from another source. Indexing the data
produces data structures that facilitate an effective generation of candidate record pairs, which likely are matches, or may refer to the
same entity.
At the second step, the record pair comparison analysis starts, where candidate record pairs from the indexed data structures are
compared by using various (selected) field comparison functions (methods). Once all the results or scores have been obtained, at the
third step, the comparison scores are split into training and testing sets. The idea behind this step is to adjust (train) the learning
structure (algorithm) with the training set, and then present new unseen record pairs to the decision model generated to assess its
performance. The known outputs (matches or non-matches) coming from the training set are used as a target to carry out supervised
learning. Subsequently, the training of the algorithm starts. Afterwards, the training set is fed to the network, and the error is
evaluated and back propagated into the model until a desired output is achieved or a number of iterations is completed. The final
step is the performance assessment of the model; here we determine how many matches, non-matches, and potential matches (“?”)
were classified. If record pairs are classified as “?”, these will require a clerical review. We also need to count the number of false
positives and false negatives and review these records to find out why they were misclassified.
3.1. The development of the learning model
Now that we have a better grasp of the overall process, we detail the construction of the decision models in the following sections
(see Figs. 2(a) and 2(b)). Since the proposed models heavily rely on the learning algorithm, we will concentrate on the fourth step. To
offer a better explanation, and to maintain conciseness of the presentation, let us consider that the decision model is constructed on
the basis of experimental data, which in most cases come as a collection of input-output data pairs
uktk((),())
ij
, k =1,2,…, N; i =1,2,
…, m; j =1,2,…, c, where u(k)
∈
R
mc
and t(k)
∈
R. More specifically, u(k)
∈
[0, 1]
mc
and t(k)
∈
[0, 1], where N is the number of
record pairs compared, m is the number of data fields selected, c is the number of comparison functions, and
m
c
is the size of each
vector u, which corresponds to all m fields processed by each j
th
method. The j
th
method applied to the i
th
field returns a matching
result u
ij
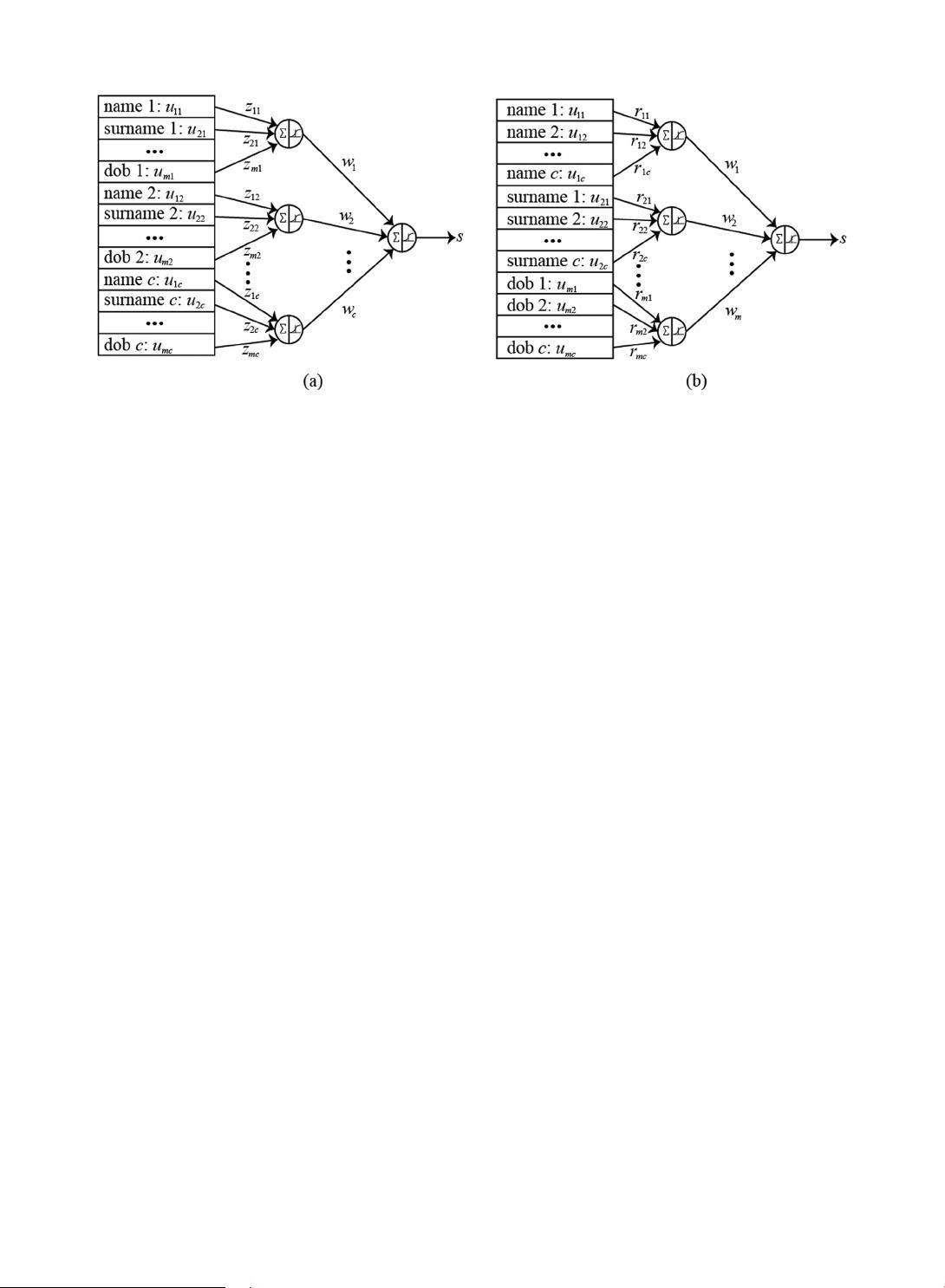
. To aggregate these results, two architectures (models) are considered. In both figures, for illustration purposes, let us
assume that field 1 corresponds to the name, field 2 to surname, and field m to DOB, and each field is processed by j =1,2,…, c
comparison methods. The way the fields are aggregated is di fferent in each model, as illustrated in Fig. 2.
Once all the scores have been produced, at the third step and the data are split into training and testing sets, an aggregation of the
scores starts. For Model 1 (Fig. 2(a)), each jth node only aggregates the fields where the jth comparison function was used, and there
are no other weights connecting with nodes corresponding to the other j +1,j +2,…, j + c – 1 functions. Considering all m fields
coming from the training set, and only the jth comparison function, the aggregate result y
j
is,
∑
p
uz y fp=,=(
)
j
i
m
ij ij
jj
=1
(1)
where f is a monotonically increasing function with values in (0, 1). z is a vector of weights z =
zz z
[
,, …,
]
jj mj12
initially with values in
[−1, 1], which expresses the significance of the i=1, 2, …, m fields. Considering all y
j
, j =1,2,…, c aggregations, we obtain the final
aggregated score s in the following form,
∑
lywsfl=,=(
)
j
c
j
j
=1
(2)
where w =[
w
ww,, …,
c
12
] is a second vector of weights which expresses the relevance of each function, and s is the output of the
Fig. 2. Aggregation of the scores coming from (a) different comparison methods or (b) different fields. Here each node sums the inputs multiplied by a weight and
then a sigmoid activation function computes the result of the aggregation for each node.
O.F. Reyes-Galaviz et al.
Data & Knowledge Engineering 112 (2017) 106–129
110
剩余23页未读,继续阅读
2019-08-09 上传
2022-07-13 上传
2021-09-17 上传
2020-05-28 上传
2010-07-22 上传
2021-03-30 上传
2023-09-01 上传
2021-10-19 上传
2021-02-10 上传

dududuv
- 粉丝: 0
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
