深入理解Spark:从RDD到性能调优
需积分: 13 126 浏览量
更新于2024-07-22
1
收藏 1.05MB PDF 举报
“AdvancedSpark训练资料,由ReynoldXin在2014年Spark峰会上分享,涵盖了RDD的概念、Spark应用的生命周期、性能调试等内容,适合已经了解基础Spark操作如wordcount的读者。”
在深入探讨Apache Spark之前,我们需要理解其核心概念——弹性分布式数据集(Resilient Distributed Datasets,简称RDD)。RDD是Spark的核心抽象,它提供了一种高级的数据并行计算模型。根据提供的部分内容,我们可以详细讨论以下几个关键知识点:
1. RDD的概念:RDD是一个不可变、分区的数据集,分布在集群的不同节点上。它可以被视为一个逻辑上的分布式集合,物理上被分割成多个分区,并存储在内存或磁盘上。RDD具备容错性,当某个分区丢失时,可以重新计算。
2. RDD的属性:
- 分区:RDD由一系列分区组成,每个分区都是数据集的一部分,可以在不同的工作节点上并行处理。
- 依赖关系:RDD维护了对其父RDD的依赖关系,这有助于Spark理解数据的血统,以便在需要时进行重算。
- 计算函数:每个RDD分区都有一个计算函数,用于从其父RDD生成当前分区的数据。
3. RDD的操作类型:
- 变换(Transformation):这种操作创建一个新的RDD,但不立即执行任何计算。例如,`filter`、`map`和`join`。这些操作仅定义了一个新的数据转换步骤。
- 行动(Action):这类操作触发实际的计算,并返回结果到驱动程序,如`count`、`collect`和`save`。行动会触发整个计算 DAG(有向无环图)的执行。
4. Spark应用的生命周期:从创建`SparkContext`开始,用户代码定义了数据处理逻辑,然后Spark会将这些逻辑转换为任务并在集群上执行。在上述示例中,`new SparkContext()`初始化了Spark环境,`textFile`读取文件,`filter`进行过滤操作,`cache`缓存结果,最后`count`计算记录数。
5. 性能调试:了解RDD的工作原理对于优化Spark应用程序至关重要。通过理解数据分布、内存管理和调度策略,开发者可以有效地定位和解决性能瓶颈。
6. “Mechanical sympathy”:这个概念强调了了解系统底层原理的重要性,即使不需要深入到每个细节,也要理解基本机制,以便更好地利用系统资源。
7. Apache Spark的模块:Spark不仅包括核心的RDD支持,还有SQL、机器学习(MLlib)和图形处理(GraphX)等模块,它们提供了更高级别的接口和功能,以满足不同领域的数据分析需求。
Advanced Spark Training涵盖了从基础RDD概念到性能调优的广泛主题,对于深入理解Spark的工作原理和提升开发效率具有很高的价值。通过深入学习这些概念,开发者可以更好地设计和优化大规模数据处理的应用。

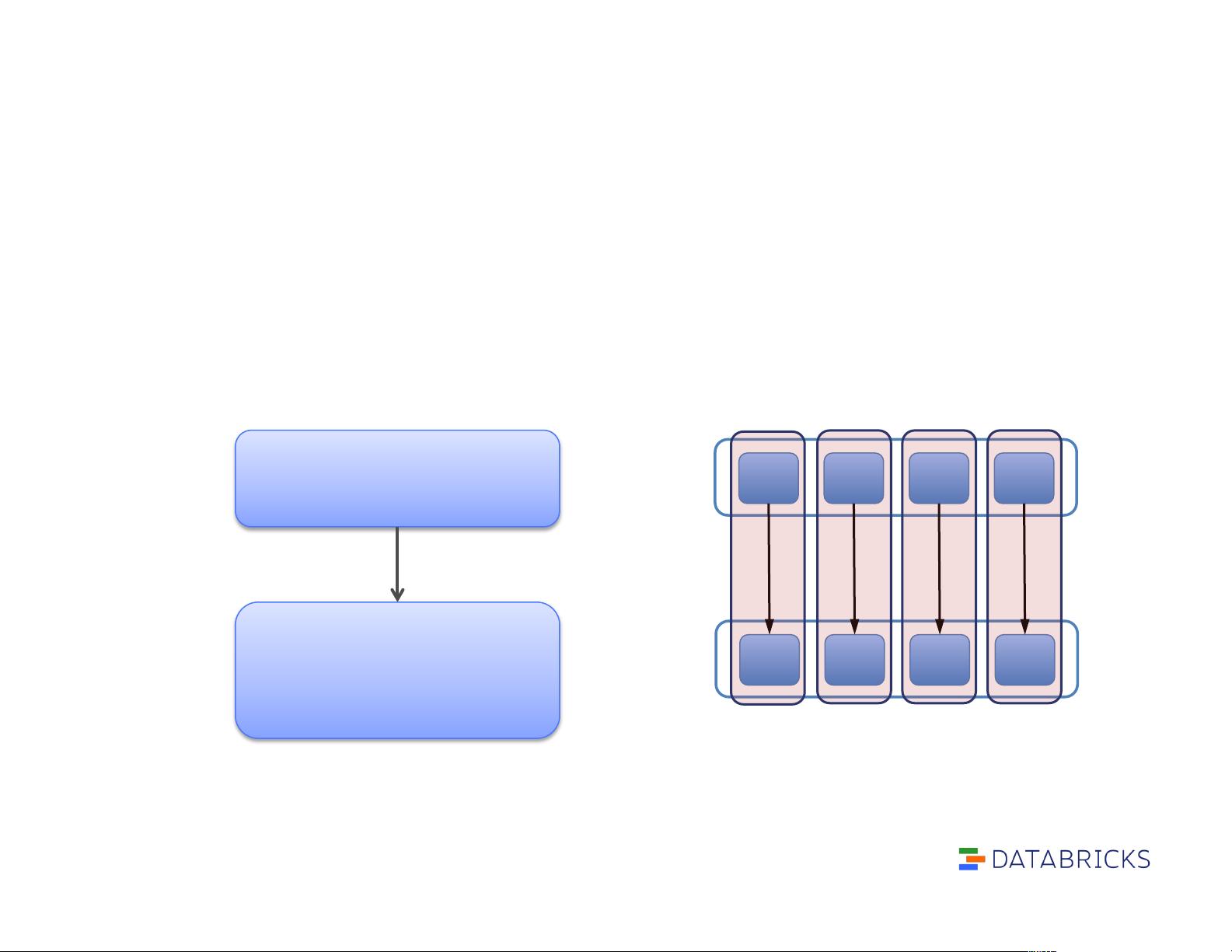
Example: Filtered RDD!
partitions = same as parent RDD!
!
dependencies = “one-to-one” on parent!
!
compute(part) = compute parent and filter it!
!
preferredLocations(part) = none (ask parent)!
!
partitioner = none!
剩余48页未读,继续阅读
2018-04-27 上传
2014-10-22 上传
2022-04-12 上传
2021-02-19 上传
2022-04-08 上传
2019-10-20 上传

mooling
- 粉丝: 2
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- all-the-streets:生成美国所有街道的地图
- hello-tailwindcss:[WIP]学习顺风
- brickpi3
- 2.4G无线鼠标PCB,PADS9.5打开-电路方案
- Teleport:进化的吉西见面会
- EvanSkiStudios.github.io:主题曲
- WordPress主题:Ofiz v1.5业务咨询主题2022年最新版.zip
- bundler.js:组件的打包器和打包指南
- buxfer-api-client:用于访问buxfer.com http API的Java客户端
- overtones:用于音乐理论和复音泛音演唱作曲者的泛音的可视化
- HuGo-开源
- 智能家居,IoT (物联网)恒温器解决方案(3D模型+代码+电路等)-电路方案
- WebFamily:【web面试+ web学习指南】涵盖大部分Web前端开发程序员所需要掌握的核心知识
- jquery.ellipsis:jQuery 的省略号插件 (MIT)
- react-measure:ute计算React组件的度量
- arduino-fan-pwm:结合了其他Arduino草图,以及额外的工作。 寻求更好的风扇pwm控制,适用于arduino uno atmega328p
