Hadoop大数据分析:Impala与Hive的比较与应用
下载需积分: 50 | PDF格式 | 30.11MB |
更新于2024-07-17
| 49 浏览量 | 举报
"这篇文档是关于Hadoop生态系统中Hive和Impala的介绍,强调了它们在大数据查询和分析中的不同应用。文档涵盖了Hadoop基础知识、选择合适工具、Impala和Hive的查询、数据管理、性能优化以及两者的扩展性等内容。"
在Hadoop生态系统中,Hive和Impala都是用于大数据查询和分析的重要工具。Hive最初设计为批处理查询系统,适合执行长时间运行的复杂数据处理任务,如日志分析或批量报表生成。它采用SQL-like语言(HQL)进行查询,并支持多种数据格式,包括文本、RCFile和Parquet。Hive的一个核心特点是其元数据服务,它允许用户通过定义表结构来管理和访问存储在HDFS上的数据。
相比之下,Impala是由Cloudera开发的实时交互式查询系统,旨在提供更快速的数据分析。Impala直接在HDFS和HBase上运行,避免了Hive中的MapReduce步骤,因此可以实现低延迟的查询性能。它同样支持SQL语法,且与Hive兼容,使得用户可以无缝切换。Impala适用于需要快速反馈和迭代分析的场景,例如数据科学家在探索数据和验证假设时。
两者在数据管理方面有共同点,比如都使用ODBC/JDBC驱动程序,允许通过标准接口连接到各种BI工具。它们都支持灵活的文件格式,包括Parquet,这种列式存储格式对于分析查询特别高效。此外,Impala和Hive都可以利用Hadoop集群的存储资源池,优化查询性能。
在实际操作中,一个常见的策略是先用Hive进行数据预处理和转换,因为Hive更适合处理复杂的转换逻辑,然后使用Impala对处理后的数据进行快速查询和分析。这样,可以结合两者的优点,既实现了数据处理的灵活性,又保证了查询的效率。
在课程中,除了Hive和Impala的介绍,还提到了其他的数据处理工具,如Pig和MapReduce。Pig是一种高级脚本语言,用于处理和分析大规模数据,而MapReduce是Hadoop的原始计算框架,适合执行大规模并行计算任务。此外,文档还涵盖了数据存储和性能优化的相关内容,以及如何通过扩展Hive来满足特定需求。
理解Hive和Impala在大数据分析中的角色及其相互配合是至关重要的。根据工作负载和性能要求,选择合适的工具对于提升大数据处理的效率和用户体验具有决定性作用。
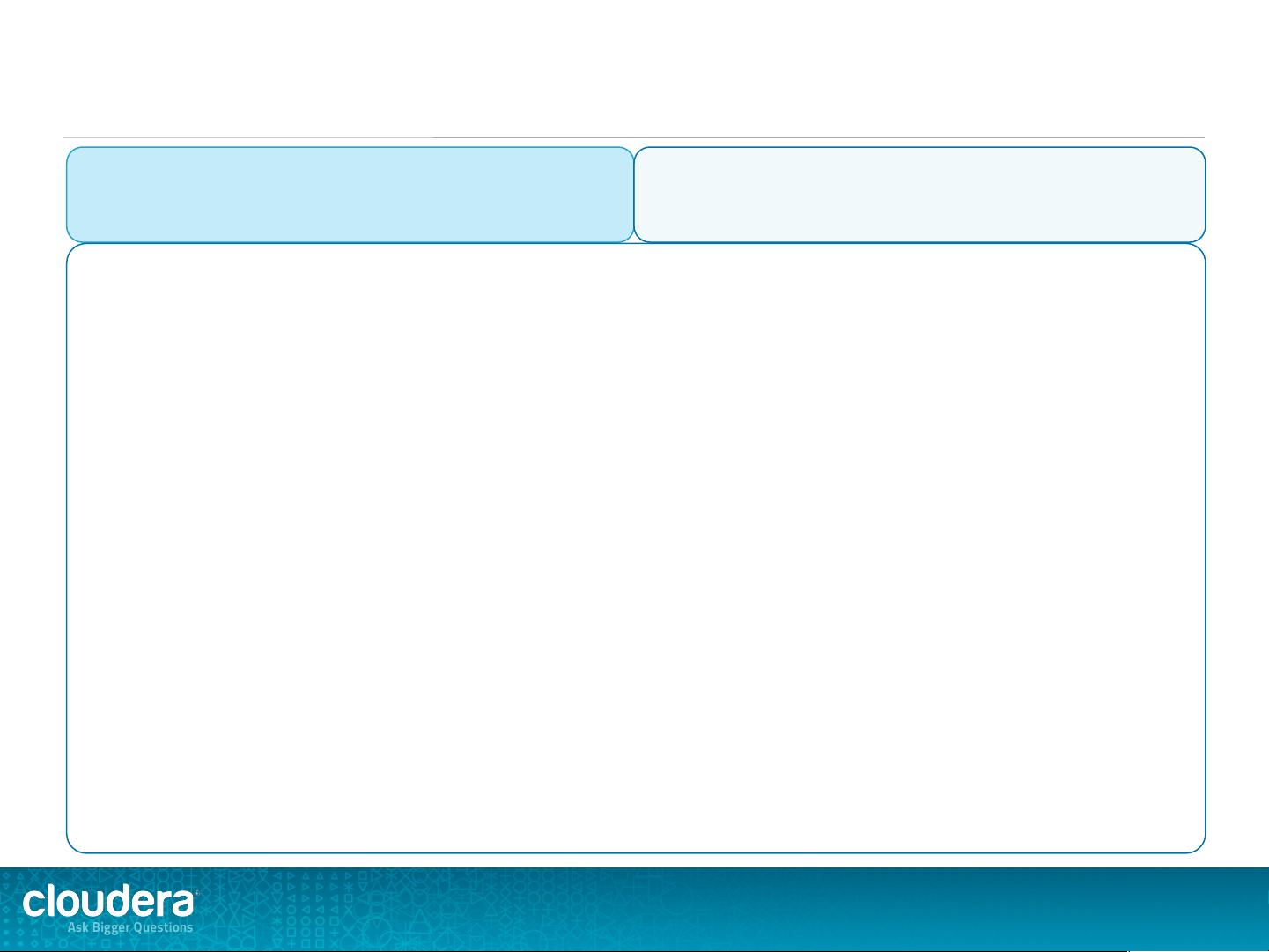
08#27%
!"#$%&'()*+",-.-/,-.0"#1$234'56"711"'()*+8"'484'9436":$+"+$";4"'4%'$32<43"=(+*$2+"%'($'"='(>4?"<$?84?+6"
!YImpala%and%Hive%are%tools%for%performing%SQL%queries%on%data%in%HDFS%
!YHiveQL%and%Impala%SQL%are%very%similar%to%SQL#92%
–YJ58&"+$"145'?"G$'"+*$84"=(+*"'415A$?51"3 5+5;584"4N%4'(4?<4"
–YB$=494'W"3$48"not"'4%15<4"&$2'"TIEOS"
!YHive%generates%jobs%that%run%on%the%Hadoop%cluster%data%proc e ssing%e ngine %
–YT2?8"O5%T432<4"\$;8"$?"B53 $$% ";5843"$ ?"B( 94RK"8+5+4D4?+8"
!YImpala%execute%queries%dir ectly%on%the%Hadoop%cluster%
–YZ848"5"94'&"G58+"8%4<(51(Q43"SRK"4?)(?4W"?$+"O5%T432<4"
!YTables%are%really%directories%of%files%in%HDFS%
–Y@?G$'D5A$?"5;$2+"+*$84"+5;1 48"(8"U4%+"(? "+*4"O4+58+$'4"`(?" 5?"TIEOS a"
J884?A51"M$(?+8"

剩余257页未读,继续阅读
相关推荐







JM_steven
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Ember.js用户活跃度跟踪,实现高效交互检测
- 如何在Android中实现Windows风格的TreeView效果
- Android开发:实现自定义标题栏的统一管理
- DataGridView源码实现条件过滤功能
- Angular项目中Cookie同意组件的实现与应用
- React实现仿Twitter点赞动画效果示例
- Exceptionless.UI:Web前端托管与开发支持
- 掌握Ruby 1.9编程技术:全面英文指南
- 提升效率:在32位系统中使用RamDiskPlus创建内存虚拟盘
- 前端AI写作工具:使用AI生成内容的深度体验
- 综合技术源码包:ASP学生信息管理系统
- Node.js基础爬虫教程:入门级代码实践
- Ruby-Vagrant:简化虚拟化开发环境的自动化工具
- 宏利用与工厂模式实践:驱动服务封装技巧
- 韩顺平Linux学习资料包:常用软件及数据库配置
- Anime-Sketch-Colorizer:实现动漫草图自动化上色
