Hadoop架构详解:HDFS与YARN的功能与协作
需积分: 5 103 浏览量
更新于2024-07-17
收藏 6.24MB PDF 举报
本资源是一份关于Apache Hadoop Cloudera Administrator Training的教程,重点关注了Hadoop分布式文件系统(HDFS)和YARN集群的结构、功能以及管理。Hadoop集群分为两个主要部分:HDFS集群和YARN资源调度器。
HDFS(Hadoop Distributed File System)是Hadoop生态系统的核心组件,用于存储海量数据。它具有以下特点:
1. **设计灵感与技术基础**:HDFS是基于Google的GFS(Google FileSystem)开发的,借鉴了其分布式存储和高可用性设计。
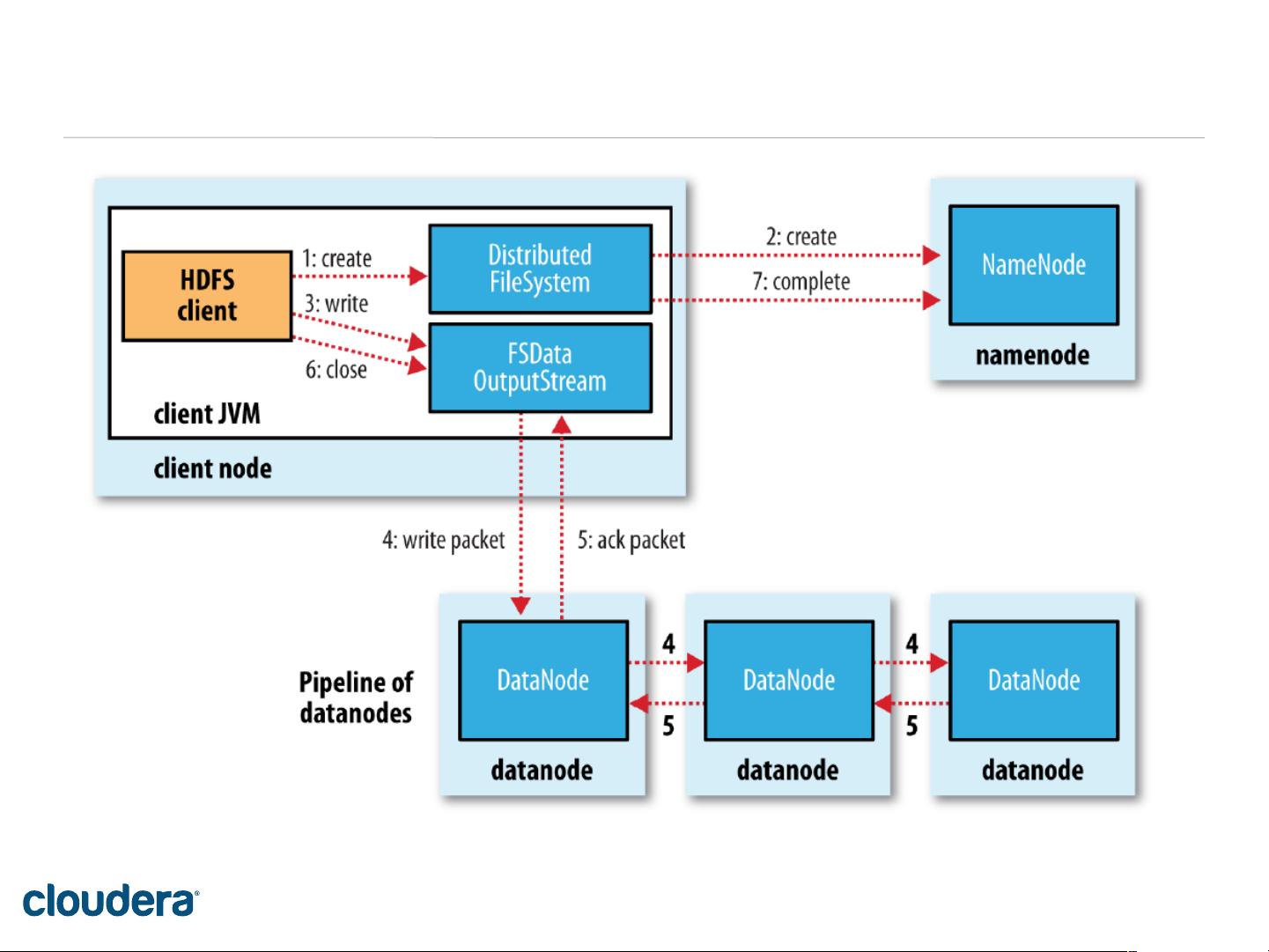
2. **核心角色**:HDFS集群中的关键角色包括NameNode(命名节点),负责元数据管理和存储目录树;DataNode(数据节点),存储实际的数据块;以及SecondaryNameNode,作为NameNode的备份,定期同步元数据。
3. **文件操作**:HDFS支持读写文件,通过NameNode协调数据块的分布和访问路径。
4. **内存管理**:NameNode使用内存来维护元数据,如文件系统的目录结构和块位置信息。
5. **安全性**:Hadoop提供文件安全机制,允许用户和应用程序控制对数据的访问权限。
6. **用户界面**:教程介绍了如何使用NameNode的Web界面进行监控和配置,以及使用Hadoop File Shell工具进行文件系统操作。
YARN(Yet Another Resource Negotiator)则负责资源调度,确保任务在集群中高效运行。YARN的主要组件包括:
1. **ResourceManager**:全局资源管理者,负责分配计算资源(如CPU和内存)给各个任务。
2. **NodeManager**:每个节点上的管理器,负责执行和监控在该节点上运行的任务,并向ResourceManager报告资源使用情况。
此外,该教程还强调了Cloudera的Hadoop发行版(CDH),它是一个企业级的、完整的Hadoop生态系统集成,包含了Apache Hadoop及相关项目的预打包和易于部署的版本。CDH提供了RPM和Ubuntu/Debian/SuSE等平台的安装包,方便管理员在不同环境中部署和管理Hadoop集群。
这份文档深入讲解了HDFS的架构和使用,对于理解和管理大规模数据处理环境中的Hadoop集群具有重要的参考价值。

!"#ZL%
:$8()4.+;"-$<=>=?<=>@$82(0'#.&A$B22$.+;"-,$.#,#.C#'A$D(-$-($/#$.#).('0E#'$F+-"(0-$).+(.$F.+G#H$E(H,#H-$I.(5$82(0'#.&A$
§ &'%()*+%B3?/%39%3./0-H3'1%/-, )%:-?33.%,64+(/0%)-+%-%+*'J6/%A-B/A3?/ %
– !"#$3#E(H'&.4$D&5#D('#$+,$not$&$I&+2(C#.$D&5#D('#$
§ \)/%A-B/A3?/%*+%-%+*'J6/%.3*'(%39%9-*640/%c=IO<d%
§ &'%.0-,H,/1%()*+%*+%'3(%-%B-e 30%*++4/%
– %*13$F+22$/#$0H &C&+2&/ 2#$0H T2$D&5#D('#$+,$.#)2&E#'$
– !"#.#$+,$C#.4$2+G2#$.+,W$(I$'&-&$2(,,$I(.$&$).() #.24$5&H&;#'$,4,-#5$
§ M/,3>/0*'J%903B%-%9-*6/?%A-B/A3?/%*+%0/6-H>/62%/-+2%
– _#$F+22$'+,E0,,$-"+,$) .(E#,,$+H$ '#-&+2 $2&-#.$
3+H;2#$Q(+H-$(I$1&+20.#$
剩余88页未读,继续阅读
2017-10-19 上传
2018-04-04 上传
2023-08-29 上传
2020-09-17 上传
2023-08-30 上传
2018-02-09 上传
2022-10-30 上传
2022-12-24 上传
2024-05-15 上传

JM_steven
- 粉丝: 0
- 资源: 18
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
