使用Puppeteer在Node.js中构建复杂爬虫实战解析
77 浏览量
更新于2024-08-28
收藏 168KB PDF 举报
"本文主要讲解如何使用Node.js的Puppeteer库进行复杂的网络爬虫开发,涉及Puppeteer的基本架构和工作原理,并对比了Puppeteer与Cheerio的区别,最后简单介绍了开始使用Puppeteer时应具备的基础知识。"
在现代Web开发中,数据抓取或网络爬虫是收集大量信息的有效手段。Puppeteer是Node.js的一个库,它提供了高级API来控制无头Chrome或Chromium浏览器,通过DevTools协议实现自动化测试和网页抓取。无头模式意味着浏览器不会显示用户界面,而是专注于后台处理任务,这对于服务器端的自动化操作非常有用。
Puppeteer的架构包括四个关键组件:
1. **Puppeteer**:它是Node.js中的接口,允许开发者编写控制Chromium或Chrome的代码。
2. **Browser**:这是一个包含多个**Page**的浏览器实例,通常是Chromium或Chrome的无头版本。
3. **Page**:代表一个独立的浏览器页面,至少包含一个**Frame**。
4. **Frame**:页面中的一个框架,拥有自己的JavaScript执行环境,可以承载网页内容并执行JavaScript。
Puppeteer的优势在于它可以模拟真实的用户交互,如点击、滚动、输入等,还能处理异步加载的内容,因为它实际上是在浏览器环境中运行,而不是仅仅解析静态HTML。相比之下,Cheerio库更适合处理静态HTML文档,它不支持执行JavaScript,因此对于依赖JavaScript动态加载的数据,Cheerio可能无法获取。
要开始使用Puppeteer,你需要了解其基本API,如`puppeteer.launch()`用于启动浏览器,`page.goto()`用于导航到指定URL,`page.evaluate()`用于在页面上下文中执行JavaScript代码,以及各种选择器方法如`page.$()`和`page.$$()`来查找和操作页面元素。
在进行复杂爬虫项目时,Puppeteer可以方便地处理登录、表单提交、动态内容加载等情况。例如,你可以用Puppeteer登录网站,然后浏览多页面,收集特定数据,最后将数据保存到文件或数据库。
总结起来,Puppeteer是一个强大的工具,它使得在Node.js环境中进行Web自动化和爬虫变得简单。对于需要处理动态加载内容、模拟用户行为或需要浏览器环境的场景,Puppeteer是绝佳的选择。如果你还不熟悉Puppeteer,建议先阅读官方文档,了解其基本用法和API,以便更好地利用这个工具。
详解详解Node使用使用Puppeteer完成一次复杂的爬虫完成一次复杂的爬虫
本文介绍了详解Node使用Puppeteer完成一次复杂的爬虫,分享给大家,具体如下:
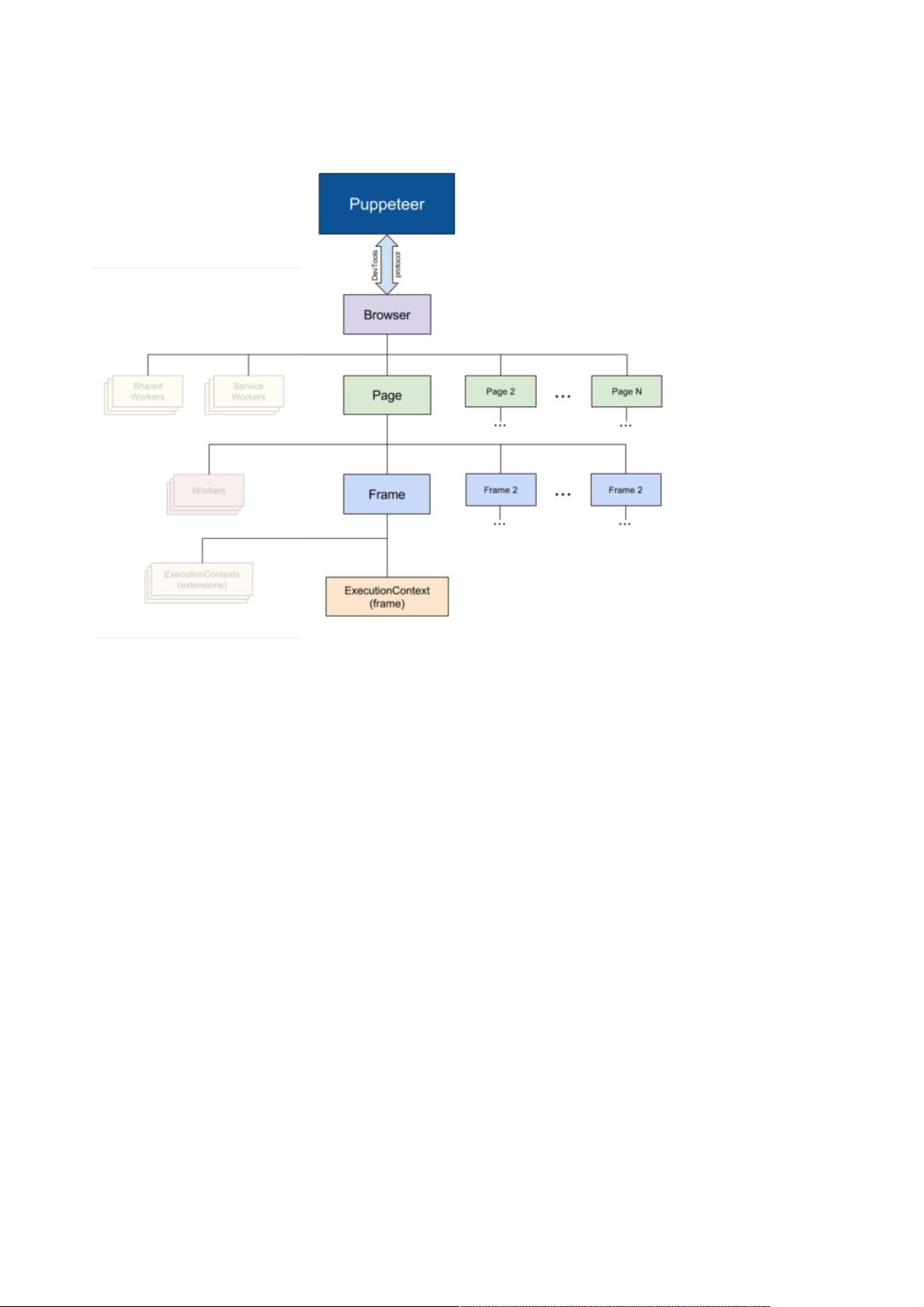
架构图
Puppeteer架构图
Puppeteer 通过 devTools 与 browser 通信
Browser 一个可以拥有多个页面的浏览器(chroium)实例
Page 至少含有一个 Frame 的页面
Frame 至少还有一个用于执行 javascript 的执行环境,也可以拓展多个执行环境
前言前言
最近想要入手一台台式机,笔记本的i5在打开网页和vsc的时候有明显卡顿的情况,因此打算配1台 i7 + GTX1070TI or
GTX1080TI的电脑,直接在淘宝上搜需要翻页太多,并且图片太多,脑容量接受不了,因此想爬一些数据,利用图形化分析
一下最近价格的走势。因此写了一个用Puppeteer写了一个爬虫爬去相关数据。
什么是什么是Puppeteer??
Puppeteer is a Node library which provides a high-level API to control headless Chrome or Chromium over the DevTools
Protocol. It can also be configured to use full (non-headless) Chrome or Chromium.
简而言之,这货是一个提供高级API的node库,能够通过devtool控制headless模式的chrome或者chromium,它可以在
headless模式下模拟任何的人为操作。
和和cheerio的区别的区别
cherrico本质上只是一个使用类似jquery的语法操作HTML文档的库,使用cherrico爬取数据,只是请求到静态的HTML文档,
如果网页内部的数据是通过ajax动态获取的,那么便爬去不到的相应的数据。而Puppeteer能够模拟一个浏览器的运行环境,
能够请求网站信息,并运行网站内部的逻辑。然后再通过WS协议动态的获取页面内部的数据,并能够进行任何模拟的操作(点
击、滑动、hover等),并且支持跳转页面,多页面管理。甚至能注入node上的脚本到浏览器内部环境运行,总之,你能对一个
网页做的操作它都能做,你不能做的它也能做。
开始开始
本文不是一个手把手教程,因此需要你有基本的Puppeteer API常识,如果不懂,请先看看官方介绍
Puppeteer官方站点
PuppeteerAPI
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-01 上传
2020-10-17 上传
2019-08-10 上传
2019-08-10 上传
2019-08-10 上传
2020-09-17 上传

weixin_38707240
- 粉丝: 5
- 资源: 921
 我的内容管理
展开
我的内容管理
展开







最新资源
- adanque.github.io
- 常用的三个Button按钮案例
- hello-world-apis:API API de grafos的世界您好
- Accuinsight-1.0.20-py2.py3-none-any.whl.zip
- 行业分类-设备装置-基于智能家居控制系统项目的DSP应用技术教学设备.zip
- Algorithm-Book:一个包含各种数据结构和算法代码的 Web 应用程序
- 基于PHP的最新仿53客服网站在线客服系统商业版php源码.zip
- Pre-trained Word Vectors for Spanish 西班牙语的预训练词向量-数据集
- Android剪切图片的Demo
- A5Orchestrator-1.0.1-py3-none-any.whl.zip
- .NET一个简单的媒体播放器的ASP毕业设计(源代码+论文).zip
- ngrinder_scripts
- TasClock:自由职业者和其他想要管理自己时间的人的 Android 任务管理器
- akandelanre.github.io:个人网页
- 封装的启动引导图
- phrg-js-spa-project:PCA JS SPA项目
