深度学习驱动的MRI图像处理与分析综述
版权申诉
深度学习在MRI图像分析中的应用已经成为当前研究的热点,随着非侵入性和高软组织对比度的优势,MRI(磁共振成像)技术吸引了越来越多的关注。本文旨在提供深度学习在MRI图像处理与分析领域的全面概述。
首先,深度学习是一种强大的机器学习方法,其基于人工神经网络,能够自动从大量数据中学习复杂的特征表示,已经在诸如图像分析、自然语言处理和专家系统等领域展现出卓越性能。在MRI图像分析中,深度学习通过其强大的表征学习能力,有助于提高图像质量的增强、噪声抑制以及疾病的早期检测和精确定位。
文章开篇对深度学习的基本概念进行了简要介绍,包括深度神经网络的结构、反向传播算法等核心原理。接下来,它详细探讨了MRI图像的不同成像模式,如T1、T2加权成像、弥散加权成像等,这些对于理解深度学习如何适应不同类型的MRI数据至关重要。
然后,文中着重介绍了几种常见的深度学习架构在MRI图像处理中的应用,例如卷积神经网络(CNN),用于识别和分类不同组织结构;循环神经网络(RNN)或长短期记忆网络(LSTM)处理序列数据,可用于动态MRI分析;以及生成对抗网络(GAN)用于图像重建和合成。这些架构通过多层次的学习,实现了对复杂图像特征的高效提取和处理。
在实际应用方面,文章列举了深度学习在MRI图像中的具体应用,包括病灶检测(如肿瘤、脑白质病变)、分割(区分正常和异常组织)、定量分析(如血流速度测量)以及影像配准等。此外,深度学习还在功能MRI(fMRI)中展现了在认知功能研究中的潜力,通过分析大脑活动与神经影像之间的关联。
深度学习方法的另一个关键领域是磁共振成像的自动化解读,如智能辅助诊断系统,通过训练模型来辅助医生进行疾病诊断,提高准确性和效率。此外,深度学习也在研究中探索了跨模态融合,结合多种MRI序列和临床信息,以实现更全面的疾病评估。
总结来说,本文综述了深度学习在MRI图像处理和分析中的最新进展,展示了其在提升图像质量和疾病检测中的重要作用,并展望了未来深度学习与MRI技术结合的广阔前景。随着硬件的进步和数据集的扩大,深度学习在MRI领域有着巨大的发展潜力,有望推动医学影像分析进入新的高度。
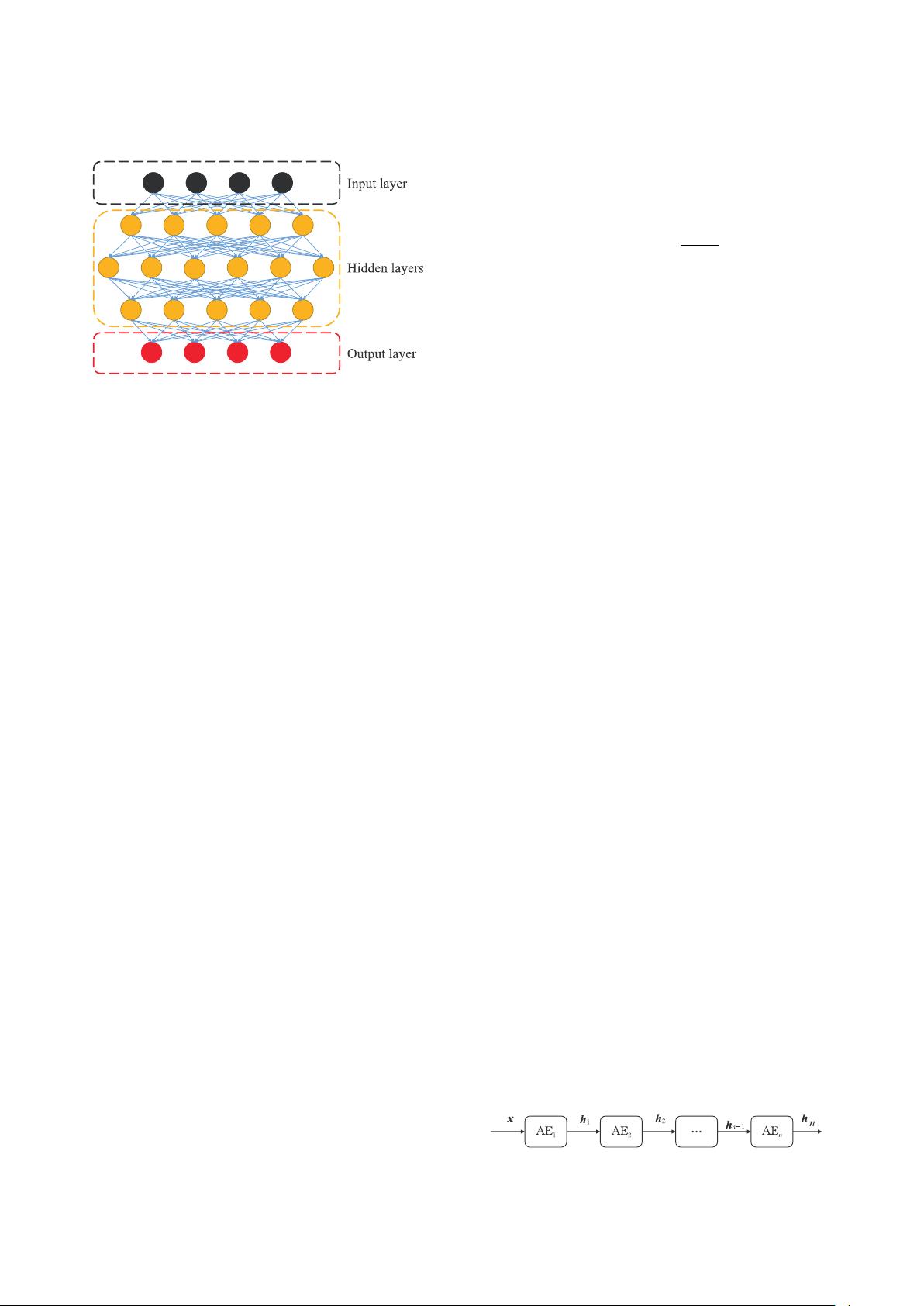
4 Big Data Mining and Analytics, March 2018, 1(1): 1-18
Fig. 1 An example of a deep feedforward network with an
input layer, three hidden layers, and an output layer.
Therefore, the deep feedforward network is one of the
most primitive deep learning architectures.
2.3 Stacked autoencoders
An autoencoder
[33–35]
is a simple deep feedforward
network, which includes an input layer, a hidden
layer, and an output layer. Meanwhile, according to
different functions, an autoencoder can be divided into
two parts: the encoder and decoder. The encoder
(denoted as f .x/) is used to generate a reduced feature
representation from an initial input x by a hidden layer
h, and the decoder (denoted as g.f .x//) is used to
reconstruct the initial input from the output of the
encoder by minimizing the loss function:
L.x; g.f .x/// (1)
By these two processes, high-dimensional data can
be converted to low-dimensional data. Therefore, the
autoencoder is very useful in classification and similar
tasks.
The autoencoder has three common variants: the
sparse autoencoder
[36, 37]
, denoising autoencoder
[38–40]
,
and contractive autoencoder
[41, 42]
, as follows:
Sparse autoencoder: Unlike autoencoders, the
sparse autoencoders add a sparse constraint ˝.h/
to the hidden layer h. Thus, its reconstruction error
can be evaluated by
L.x; g.f .x/// C ˝.h/ (2)
Denoising autoencoder: Unlike sparse
autoencoders, which add a sparse constraint
to the hidden layer, denoising autoencoders are
aimed at minimizing the loss function:
L.x; g.f .
e
x/// (3)
where
e
x is based on x with some noise.
Contractive autoencoder: Similar to sparse
autoencoders, contractive autoencoders add the
explicit regularizer ˝.h/ to the hidden layer h,
and minimize the explicit regularizer. The explicit
regularizer is
˝.h/D
@f .x/
@x
2
F
(4)
where ˝.h/ is the squared Frobenius norm
[43]
of the Jacobian partial derivative matrix of the
encoder function f .x/, and is a free parameter.
A stacked autoencoder
[31, 44]
is a neural network
with multiple autoencoder layers as shown in
Fig. 2. Furthermore, the input of the next layer
comes from the output of the previous layer in the
stacked autoencoders. An autoencoder usually consists
of only three layers and does not have a deep learning
architecture. However, the stacked autoencoder does
have a deep learning architecture with a stacked number
of autoencoders. It is worth mentioning that the training
of the stacked autoencoder can only accomplish an
action, layer-by-layer. For example, if we want to
train a network with an n ! m ! k architecture
using a stacked autoencoder, we must first train the
network n ! m ! n to get the transformation n ! m,
and then train the network m ! k ! m to get the
transformation m ! k, and finally stack the two
transformations to form the stacked autoencoder (i.e.,
n ! m ! k). This process is also called layer-wise
unsupervised pre-training
[17]
.
2.4 Deep belief networks
The Boltzmann machine
[45–48]
is derived from statistical
physics and is a modeling method based on energy
functions that can describe the high order interaction
between variables. Although the Boltzmann machine is
relatively complex, it has a relatively complete physical
interpretation and a strict mathematical statistics theory
as its basis. The Boltzmann machine is a symmetric
coupled random feedback binary unit neural network,
which includes a visible layer and multiple hidden
layers. The nodes of the Boltzmann machine can
be divided into visible units and hidden units. In a
Boltzmann machine, its visible and hidden units are
used to represent the random neural network learning
model, and its weights between two units in the
model are used to represent the correlation between the
Fig. 2 An example of a stacked autoencoder with n
autoencoders (i.e., AE
1
, AE
2
,.., AE
n
).
剩余17页未读,继续阅读
2018-08-15 上传
2021-02-03 上传
2021-08-18 上传
2021-09-01 上传
2021-08-31 上传
2021-09-01 上传
点击了解资源详情
2021-08-04 上传
2021-07-10 上传

Fun_He
- 粉丝: 19
- 资源: 104
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
