HDFS深度解析:分布式存储与操作实践
需积分: 25 146 浏览量
更新于2024-07-19
收藏 2.15MB PDF 举报
"HDFS原理与操作,分布式存储,数据冗余,Hadoop数据分析,黄志洪,DATAGURU,NameNode,DataNode,事务日志,映像文件,SecondaryNameNode"
分布式文件系统HDFS(Hadoop Distributed File System)是Apache Hadoop项目的核心组件,设计用于处理和存储大量数据。HDFS提供了可扩展的分布式存储机制,能够应对PB级别的大规模数据集,适合大数据分析场景。其核心设计目标是处理硬件故障的常态,通过数据冗余来确保高可用性和容错性。
HDFS支持流式数据访问模式,这意味着数据通常一次性写入后多次读取,而不是频繁进行随机读写操作。这种设计使得HDFS在数据分析任务上表现出色,但不适合需要高速事务处理的应用。HDFS采用简单的一致性模型,文件一旦写入并关闭,就不能再被修改,以简化系统复杂度。
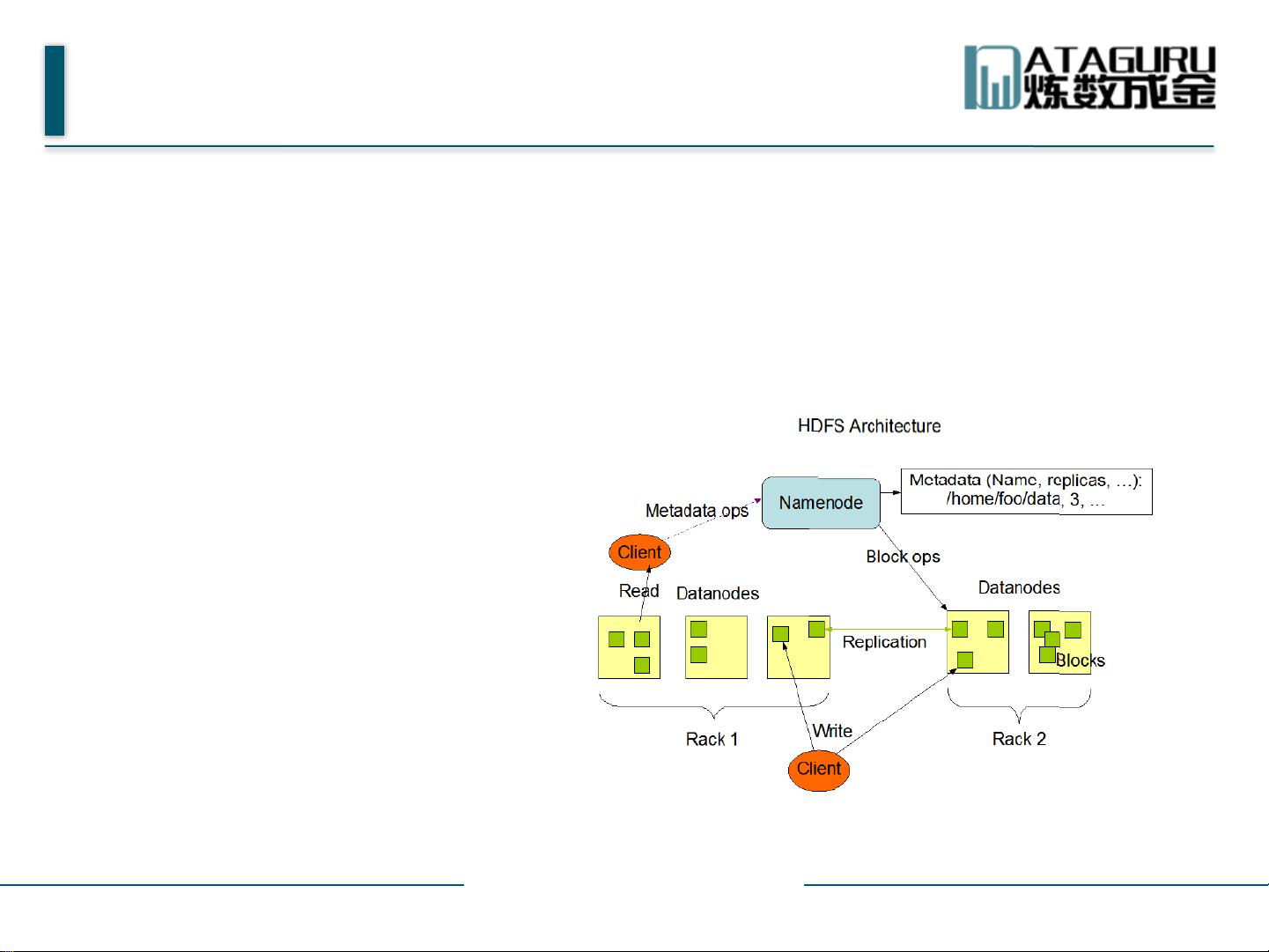
HDFS体系结构主要包括两个主要角色:NameNode和DataNode。NameNode作为主节点,负责管理文件系统的命名空间,记录文件及其数据块在各个DataNode上的位置信息,并协调客户端对文件的访问。NameNode使用事务日志记录HDFS元数据的变化,同时有映像文件存储文件系统的命名空间信息。
DataNode则是数据存储的实际执行者,每个DataNode负责其所在物理节点的存储管理。数据块是一次写入、多次读取的,且文件由多个数据块组成,通常每个数据块的大小为64MB。DataNode会尽可能地将数据块分散到不同的节点,以提高容错性和读取效率。
此外,HDFS还有SecondaryNameNode,它并非NameNode的热备份,而是帮助NameNode定期合并事务日志和映像文件,减轻NameNode的压力,保持元数据的稳定性。
在实际操作HDFS时,用户需要了解如何使用Hadoop命令行工具进行文件的上传、下载、查看等操作,以及如何配置HDFS参数以优化性能。对于Hadoop数据分析平台的使用者来说,理解HDFS的工作原理和操作方式是进行高效大数据处理的基础。
Hadoop数据分析平台 第4版课程 讲师 黄志洪
DATAGURU与业数据分析社区
机架策略
集群一般放在丌同机架上,机架间带宽要比机架内带宽要小
HDFS的“机架感知”
一般在本机架存放一个副本,在其它机架再存放别的副本,返样可以防止机架失敁时
丢失数据,也可以提高带宽利用率
15




剩余90页未读,继续阅读
2019-07-13 上传
2015-11-20 上传
2022-04-18 上传
点击了解资源详情
2017-11-01 上传
2021-09-21 上传
2024-04-11 上传
2023-06-22 上传
2022-03-07 上传

Running_Tiger
- 粉丝: 466
- 资源: 67
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
