Python爬虫项目结构与部署实战
需积分: 5 30 浏览量
更新于2024-08-03
收藏 110KB PDF 举报
"该资源是一个Python爬虫项目结构的示例,包含了一个基本的爬虫框架,以及部署和测试的相关文件。项目结构清晰,适用于学习和构建实际的爬虫项目。"
在Python爬虫工程中,合理的项目结构有助于提高代码的可读性和维护性。从给出的文件列表可以看出,这个项目包含以下几个关键部分:
1. **main.py**:通常作为项目的主入口文件,用于启动爬虫程序。
2. **setup.py**:这是Python项目的配置文件,用于安装和打包项目,通过它可以将项目设置为一个可安装的Python包。
3. **requirements.txt**:列出项目依赖的Python库,方便在新环境中安装所有必要的包。
4. **sample** 和 **wechat** 目录:代表两个不同的爬虫模块,可能分别处理不同的数据源或者有不同的功能。每个目录下有`__init__.py`表示它们是Python包,`spider.py`可能是具体的爬虫脚本,而`utils`子目录包含了通用的辅助工具,如`redis.py`和`mongodb.py`可能分别用于与Redis和MongoDB数据库的交互。
5. **docs** 目录:包含项目文档,可能使用Sphinx等工具生成。
6. **tests** 目录:存放单元测试文件,如`test_basic.py`和`test_advanced.py`,用于验证代码的正确性。
7. **start.sh**:这是一个Shell脚本,很可能用于一键启动爬虫或相关服务。
8. **Supervisor**:提到的Supervisor是一个进程管理工具,用于管理Python爬虫的后台运行,确保爬虫服务的稳定性和可靠性。
在项目结构中,我们还看到一个简单的Web应用结构,如`web/blog`目录,这可能是一个基于Django或Flask的后端应用,用于展示或处理爬取的数据。它包含常规的Web应用目录结构,如`admin.py`、`models.py`、`static`和`templates`,表明这是一个包含数据库操作、视图、模板和静态文件的完整Web应用。
在`utils`模块中,`redis.conn`和`mongodb`的引用意味着项目可能使用Redis作为中间件缓存数据,而MongoDB作为存储爬取数据的数据库。
最后,`start.sh`脚本的执行可能会启动爬虫和Web服务,使得爬取的数据能够实时地展示在Web应用上。这提供了一种完整的数据抓取、处理和展示的解决方案。
总结来说,这个Python爬虫项目展示了如何组织和部署一个包含爬虫、数据存储以及Web展示的综合系统。学习这个项目可以了解到如何构建可扩展和可维护的爬虫工程,以及如何结合数据库和Web应用来处理和展示爬取的数据。
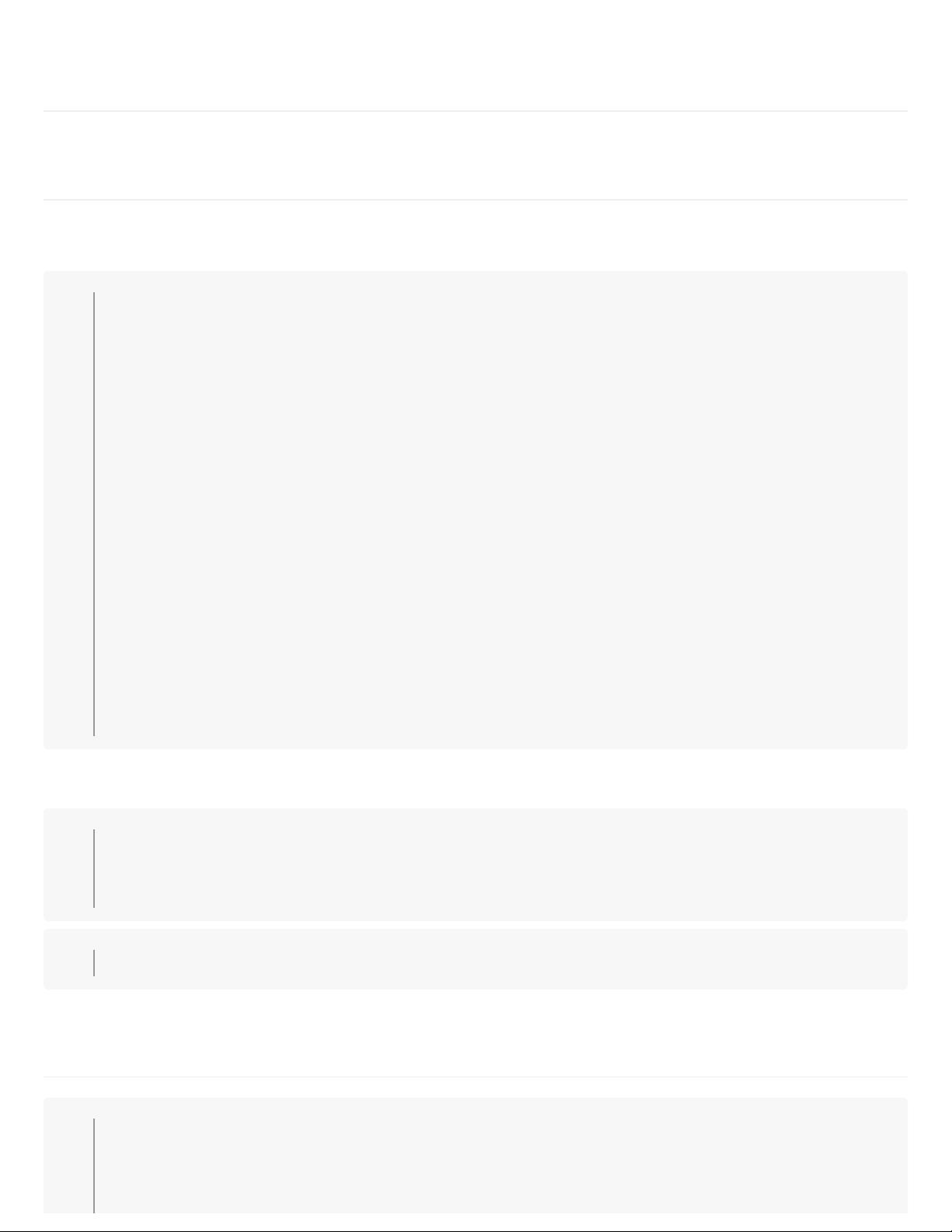
main.py
python
!"#$%"&'(
)*+",-"
./012&23
4/5164/'/70.&080
.9'2:/;<<6760<<&23
.9'2:/;'967&23
.9'2:/;.26(/4&23
.9'2:/;106:.;<<6760<<&23
.9'2:/;106:.;4/(6.&23
.9'2:/;106:.;'=7>=(?&23
@/AB90;<<6760<<&23
@/AB90;'967&23
(=A.;A=7C&23
(=A.;67(/8&'(
0/.0.;0/.0<?9.6A&23
0/.0.;0/.0<9(D97A/(&23
.0940&.BEEFE
G
H
I
J
K
L
M
N
O
GP
GG
GH
GI
GJ
GK
GL
GM
C4='E&106:.E6'2=40E4/(6.QE'=7>=(?
4/(6.&A=77
'=7>=(?&
G
H
I
.BE.0940&.B
G
web
RSSE?:=>
TEEERSSE<<6760<<&23
TEEERSSE9('67&23
G
H
I
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
269 浏览量
134 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
127 浏览量

普通网友
- 粉丝: 1049
 我的内容管理
展开
我的内容管理
展开







最新资源
- Vue.js波纹效果组件:Vue-Touch-Ripple使用教程
- VHDL与Verilog代码转换实用工具介绍
- 探索Android AppCompat库:兼容性支持与Java编程
- 探索Swift中的WBLoadingIndicatorView动画封装技术
- dwz后台实例:全面展示dwz控件使用方法
- FoodCMS: 一站式食品信息和搜索解决方案
- 光立方制作教程:雨滴特效与呼吸灯效果
- mybatisTool高效代码生成工具包发布
- Android Graphics 绘图技巧与实践解析
- 1998版GMP自检评定标准的回顾与方法
- 阻容参数快速计算工具-硬件设计计算器
- 基于Java和MySQL的通讯录管理系统开发教程
- 基于JSP和JavaBean的学生选课系统实现
- 全面的数字电路基础大学课件介绍
- WagtailClassSetter停更:Hallo.js编辑器类设置器使用指南
- PCB线路板电镀槽尺寸核算方法详解
