MIPS指令与运算优化:性能提升与溢出分析
需积分: 0 68 浏览量
更新于2024-08-04
收藏 64KB DOCX 举报
在本资源中,主要涵盖了MIPS指令集、性能优化和计算机体系结构方面的知识点。MIPS(Microprocessor without Interlocked Pipeline Stages)是一种广泛应用的RISC(Reduced Instruction Set Computing)架构,这里提供了两个具体的MIPS指令及其操作:
1. 首先,我们看到`sll $t2, $t0, 4` 是一个左移指令,它将$t0寄存器的内容向左移动4位,结果将存储在$t2中。`or $t2, $t2, $t1` 是逻辑或操作,如果$t1有非零位,那么这些位会被设置在$t2的结果中。但题目并未给出$t0和$t1的具体值,所以无法计算出$t2的确切值。
2. 第二个指令是`sll $t2, $t0, 4` 同样是一个左移操作,这次与`andi $t2, $t2, -1` 结合。`andi` 是按位与指令,它将$t2与-1进行逻辑与操作,因为-1的二进制形式是全1,所以执行这个操作后,$t2的结果会变成所有高位被清除,只保留最低位。这相当于一个移除最高位的操作。
关于性能优化方面,题目提到通过将乘法操作时间从80秒减少到16秒,实现了程序运行速度的五倍提升。这体现的是B.通过流水线(Pipeline)提高性能的思想,流水线技术可以同时处理多个指令,从而提高处理器的执行效率。
对于功耗问题,单纯提高工作电压会导致功耗增加,因此选择A.提高。
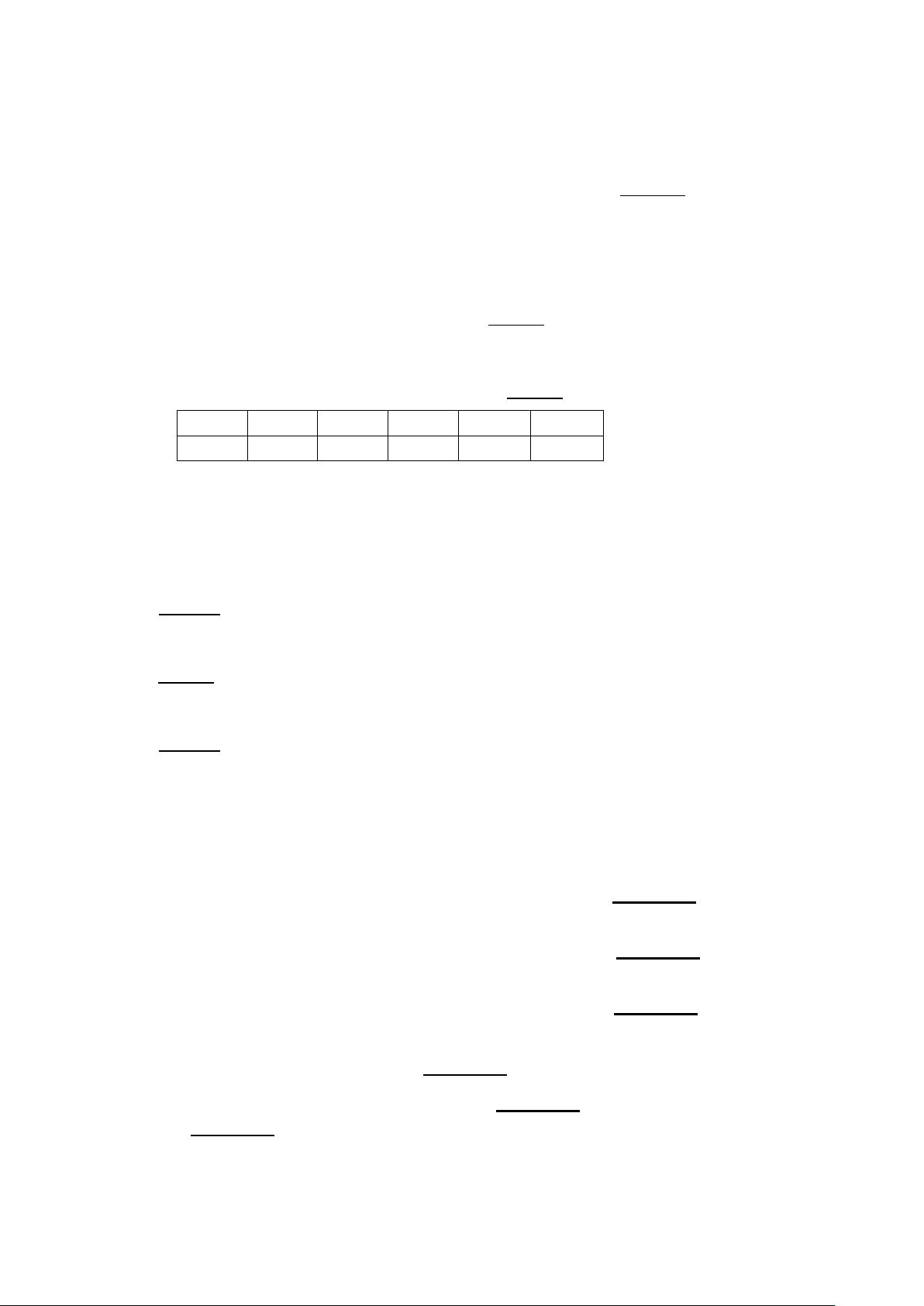
接下来是MIPS指令识别部分,需要根据指令格式判断:
- `sub $t0, $t1, $t2` 是减法指令,不符合图表中的样式。
- `add $t2, $t0, $t1` 也是加法指令,同样不匹配图表。
- `sub $t2, $t1, $t0` 和 `sub $t2, $t0, $t1` 都是减法指令,但前者是第一个操作数减去第二个,后者是第一个操作数减去第三个,题目未提供具体操作数,无法确定。
- 图表部分没有给出,无法判断对应的MIPS指令。
溢出检查涉及整数运算和溢出处理:
- 对于$s0=0x70000000和$s1=0xD0000000的加法,由于$s1的最高位为1,结果可能超过32位表示范围,会溢出,选A。
- 对于$s0=0x80000000和$s1,加法前$s0已经是最大值,加上$s1必然溢出,选A。
- 对于$s0=0x7FFFFFFF和$s1,减去$s1后$s0会变为负值,但不会溢出,选B。
最后,涉及到了MIPS指令的细节操作:
- `sll $t2, $t0, 4` 结果是$t0左移4位。
- `andi $t2, $t2, -1` 后,由于-1相当于二进制的11111111111111111111111111111111,清除所有高位,留下最低位,结果未知。
- 要将乘法结果分段存储,可能需要先执行`mul`指令,然后用`mfhi`和`mflo`提取高32位和低32位。
- 函数调用通常使用`jal`(jump and link)和`jr`(jump return)指令。
- 跳转指令`beq`根据条件转移,$t0=14,$t1=23时,下一条指令地址取决于转移目标,题目没有提供转移条件。
至于C代码到MIPS汇编的转换,涉及到数组访问和算术运算,需要根据具体内存布局和指令集规定编写,这部分内容没有提供完整的C代码,所以无法给出完整的转换。
这段资源包含了MIPS指令执行、性能优化策略、溢出检查以及基本的MIPS指令理解和应用。
1. 一个程序在一台计算机上运行时需要 100 秒,其中 80 秒的时间用于乘法操
作,通过将乘法操作的速度改进到只需 16 秒,从而把程序的运行速度提高
到 5 倍。这里改进性能所使用到的是哪个伟大设计思想 。
A.通过预测提高性能 B.通过流水线提高性能 C.加速大概率事件 D.通
过并行提高性能
2. 对某一芯片只提高工作电压,则其功耗 :
A. 提高; B. 下降;C. 不确定; D. 保持不变;
3. 下面的图表代表的是哪条 MIPS 指令? ( )
op
rs
rt
rd
shamt
funct
0
8
9
10
0
34
A. sub $t0, $t1, $t2 B. add $t2, $t0, $t1
C. sub $t2, $t1, $t0 D. sub $t2, $t0, $t1
4. 假设$s1 中的值是 0xD0000000,给定下列$s0 的值,执行下列指令是否会
产生溢出?
( )(1)$s0=0x70000000, 执行 add $s0,$s0,$s1, A.会溢出
B.不会溢出
( )(2)$s0=0x80000000, 执行 sub $s0,$s0,$s1, A.会溢出 B.
不会溢出
( )(3)$s0=0x7FFFFFFF, 执行 sub $s0,$s0,$s1, A.会溢出
B.不会溢出
5. 假设$t0=0xBEADFEED, $t1= 0xDEADFADE. 求执行下面指令后寄存器
$t2 的值。
(1) sll $t2, $t0, 4
or $t2, $t2, $t1 则$t2= ( )
(2) sll $t2, $t0, 4
andi $t2, $t2, -1 则$t2= ( )
(3) srl $t2, $t0, 3
andi $t2, $t2, 0xFFEF 则$t2= ( )
6. 如果要将乘法指令结果的高 32 位保存在$t1,低 32 位保存在$t2 中,需要
使用两条指令来完成,它们是
7. 为了调用函数 myfunc1,应该使用指令 ,函数返回时应该使用指
令 返回到调用函数处的下一跳指令。
8. 如果指令“beq $t0,$t1, 32”指令位于 0x1000 地址,执行该指令时
下载后可阅读完整内容,剩余3页未读,立即下载
2022-08-08 上传
2022-08-03 上传
2022-08-08 上传
2021-12-09 上传
2021-08-24 上传
2021-12-01 上传
2018-01-23 上传
2021-10-06 上传
2021-10-12 上传

无声远望
- 粉丝: 966
- 资源: 298
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
