揭示Bw-Tree设计全貌:理论与实践挑战
20 浏览量
更新于2024-07-14
收藏 2.19MB PDF 举报
"Building a Bw-Tree Takes More Than Just Buzz Words" 是一篇发表于2018年的研究论文,由Ziqi Wang、Andrew Pavlo、Hyeontaek Lim、Viktor Leis、Huanchen Zhang、Michael Kaminsky和David G. Andersen等人合作完成,他们分别来自卡内基梅隆大学(Carnegie Mellon University)、慕尼黑工业大学(TUM)和英特尔实验室(Intel Labs)。这篇论文关注的是微软在2013年提出的一种名为Bw-Tree的数据结构,它在SQL Server的Hekaton引擎中被设计用于处理高吞吐量的事务型数据库工作负载,特别强调了其无锁(lock-free)特性,通过附加delta记录到树节点和使用比较与交换(Compare-and-Swap, CaS)操作实现原子物理指针更新,从而避免了传统锁机制。
然而,原始论文中存在重要的细节缺失,这使得理解和实现这种技术变得困难。作者们指出,虽然Bw-Tree的概念引人注目,但微软的研究成果并未提供足够的详尽指导,且相关的源代码也没有公开。因此,这篇论文的核心贡献在于填补这一空白,提供了构建Bw-Tree所需的缺失指南和技术细节,包括如何正确处理并发控制、内存管理、冲突解决以及性能优化等方面。
构建Bw-Tree并非仅仅依靠流行术语就能实现,它需要深入理解数据结构的底层原理,如平衡因子维护、节点合并和分裂策略,以及如何利用CaS操作确保在多线程环境中的一致性和原子性。此外,论文还可能探讨了Bw-Tree在实际应用中的局限性、适应不同工作负载的能力,以及如何在保证高性能的同时兼顾其他系统特性,如内存占用和扩展性。
这篇文章对于那些想要深入了解Bw-Tree设计、实现和优化过程的IT专业人士来说,是一份宝贵的资源,它不仅填补了理论空白,还可能包含了一些实用的编码实践和教训,对于后继者在构建类似的数据结构时具有重要参考价值。"
Δinsert [K
1
, V
3
]
Δdelete [K
1
, V
1
]
Δinsert [K
1
, V
4
]
Δdelete [K
1
, V
4
]
V
4
V
4
V
1
V
4
V
3
V
1
V
4
V
2
V
3
V
1
V
4
Leaf node
Delta record
S
present
S
deleted
K
1
V
1
V
2
K
1
Figure 3: Non-unique Key Support
– The two sets (
S
present
,
S
deleted
) track
the visibility of ∆insert and ∆delete records in the Delta Chain.
a new traversal from the root, using the current low key or high
key to reach the previous or the next sibling node.
3.3 Mapping Table Expansion
Since every thread accesses the Bw-Tree’s Mapping Table multiple
times during traversal, it is important that it is not a bottleneck.
Storing the Mapping Table as an array of physical pointers indexed
by the node ID is the fastest data structure. But using a xed-size
array makes it dicult to dynamically resize the Mapping Table as
the number of items in the tree grows and shrinks. This last point
is the problem that we address here.
The OpenBw-Tree pre-allocates large virtual address space for
the Mapping Table without requesting backing physical pages. This
allows it to leverage the OS to lazily allocate physical memory
without using locks; this technique was previously used in the
KISS-Tree [
18
]. As the index grows, a thread may attempt to access
one of the Mapping Table’s pages that have not been mapped to
the physical memory, incurring a page fault. The OS then allocates
a new empty physical page for the virtual page. In practice, the
amount of virtual address space we reserve is estimated using the
total amount of physical memory and the lower bound of virtual
node size.
Although this approach makes it easy to increase the number of
entries in the Mapping Table as the index grows, it does not solve
the problem of shrinking the size of the Mapping Table. To the best
of our knowledge, there is no lock-free way of doing this. The only
way to shrink the Mapping Table is to block all worker threads and
rebuild the index.
4 COMPONENT OPTIMIZATION
A good-faith implementation of the data structure described in
original Bw-Tree paper design can further be improved. We present
our optimizations for the OpenBw-Tree’s key components to im-
prove its performance and scalability. As we show in Section 5,
these optimizations increase the index’s throughput by 1.1–2.5
×
for multi-threaded environments.
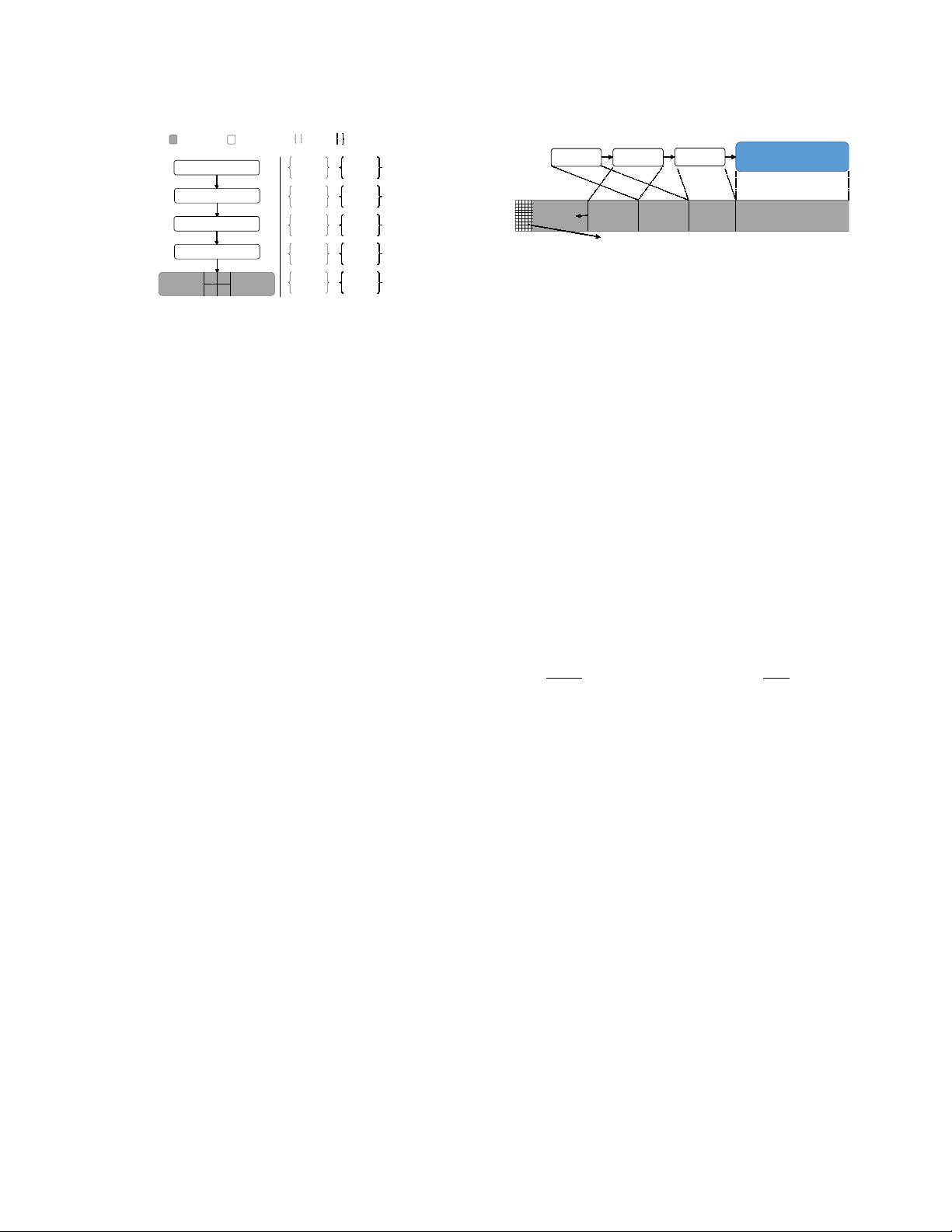
4.1 Delta Record Pre-allocation
As described in Section 2.1, the Delta Chain in Bw-Tree is a linked
list of delta records that is allocated on the heap. Traversing this
linked list is slow because a thread can incur a cache miss for
each pointer dereference. Additionally, excessive allocations of
small objects create contention in the allocator, which becomes a
scalability bottleneck as the number of cores increases.
Δ
1
Base Node
Δ
2
Δ
3
Base node storage
Δ
1
Δ
3
Δ
2
Free
Space
Low address
High address
Logical view
Physical view
Allocation metadata (incl. the marker)
Growing
Figure 4: Pre-allocated Chunk
– This diagram depicts the logical view
and physical view of a OpenBw-Tree node. Slots are acquired by threads
using a CaS on the marker, which is part of the allocation metadata on
lower-address of the chunk.
To avoid these problems, the OpenBw-Tree pre-allocates the
delta records inside of each base node. As shown in Fig. 4, it stores
the base node in the high-address end of the pre-allocated chunk
and stores the delta records from high to low addresses (right-to-left
in the gure). Each chain also maintains an allocation marker that
points to the last delta record or the base node. When a worker
thread claims a slot, it decrements this marker by the number of
bytes for the new delta record using an atomic subtraction. If the
pre-allocated area is full, then this triggers a node consolidation.
This reverse-growth design is optimized for ecient Delta Chain
traversals. Reading delta records in the new-to-old order is likely
to (but not always) access memory linearly from low to high ad-
dresses, which is ideal for modern CPUs with hardware memory
prefetching. But threads must traverse a node’s Delta Chain by
following each delta record’s pointer to nd the next entry, rather
than just scanning from low to high addresses. This is because
the logical order of delta records may not match their physical
locations in memory. Slot allocations and Delta Chain appendings
are not atomic, permitting multiple threads to interleave them. For
example, Fig. 4 shows that delta record
∆
3
was logically added to
the node
before
delta record
∆
2
, but
∆
3
appears
after ∆
2
physically
in memory.
4.2 Garbage Collection
The OpenBw-Tree adopts a garbage collection (GC) scheme that
is similar to the one used in Silo [
34
] and Deuteronomy [
24
]. The
epoch-based GC scheme of the original Bw-Tree [
25
] provides
safe memory reclamation that prevents the index from reusing
memory when there may exist a thread that is accessing it. With
this approach, the index maintains a list of global epoch objects,
and appends new epoch objects to the end of this list at xed
intervals (e.g., every 40 ms). Every thread must enter the epoch
by enrolling itself in the current epoch object before it accesses
the index’s internal data structures (e.g., performing a key lookup).
When the thread completes its operation, it removes itself from the
epoch it has entered. Any objects that are marked for deletion by a
thread are added into the garbage list of the current epoch. Once all
threads exit an epoch, the index’s GC component can then reclaim
the objects in that epoch that are marked for deletion.
Fig. 5a illustrates the centralized GC scheme with three active
epochs, three worker threads (
t
1
,
t
2
,
t
3
), and a background GC
thread (
t
дc
). In this diagram,
t
2
adds a new node to the garbage list
of epoch 103. At the same time, the GC thread
t
дc
installs a new
epoch object to the epoch list. Since the counter inside epoch 101
has reached zero, t
дc
will reclaim all entries in its garbage list.
剩余15页未读,继续阅读
2023-07-17 上传
2021-05-10 上传
2021-03-31 上传
2021-04-03 上传
2021-05-24 上传
2021-04-07 上传

weixin_38696458
- 粉丝: 5
- 资源: 919
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
