二叉树数据结构:存储、排序与查找的比较
版权申诉
193 浏览量
更新于2024-07-01
收藏 73KB DOC 举报
"数据结构(8).doc" 文件主要探讨了数据结构中的二叉树以及其两种主要存储结构——顺序存储和链式存储的优缺点,并通过实例展示了如何将二叉树转换为数组。此外,文件还介绍了树的基本概念,包括根结点、子树、度等术语。
在数据结构中,二叉树是一种特殊的树形结构,每个结点最多有两个子结点,分别称为左子结点和右子结点。二叉树的存储结构主要有两种:
1. **顺序存储**:通常使用数组来实现,优点是访问效率高,因为数组支持随机访问,所以在非完全二叉树中,如果已知索引,可以直接访问到对应节点,时间复杂度为O(0)。但缺点是空间利用率不高,对于非完全二叉树,可能会有很多空闲位置。
2. **链式存储**:通过链表结构来表示二叉树,每个结点包含指向其左右子结点的指针。这种方式在存储不完全二叉树时空间利用率较高,但访问指定节点的时间复杂度为O(nlogn),因为需要遍历链表。
文件中提到了一个程序设计任务,要求实现排序和查找功能,分别使用链表、数组和二叉树数据结构。这样的比较有助于理解不同数据结构的特性:
- **链表**:适合动态插入和删除,但随机访问效率低,排序和查找可能需要线性时间O(n)。
- **数组**:适用于静态数据,支持快速随机访问,排序可以通过内置排序算法实现,如快速排序、归并排序,查找效率取决于排序方式,如二分查找O(logn)。
- **二叉树**:二叉搜索树在平衡情况下(如AVL树、红黑树)查找、插入和删除的时间复杂度均为O(logn),但在最坏情况下(退化为链表)会退化为O(n)。
文件还介绍了二叉树到数组的转换方法,这是一种常见的二叉树遍历策略,即满二叉树或完全二叉树可以按照特定规则映射到一维数组中。例如,根结点在数组的0位置,左子结点在2i+1,右子结点在2i+2的位置。这种转换在某些操作中非常有用,比如存储和打印二叉树。
树的基本概念包括:
- **根结点**:树中没有父结点的结点,是树的起始点。
- **子树**:树中的一个结点及其所有后代形成一个子树。
- **度**:一个结点的子结点数量,度为0的结点称为叶子结点,度大于0的结点称为内部结点。
- **孩子**、**双亲**和**兄弟**:子树的根是其双亲结点的孩子,双亲结点的子树根之间互为兄弟。
理解这些基本概念对于理解和操作树结构至关重要,包括在算法设计中的应用,如树的遍历(前序、中序、后序),以及树的查找、插入和删除操作。
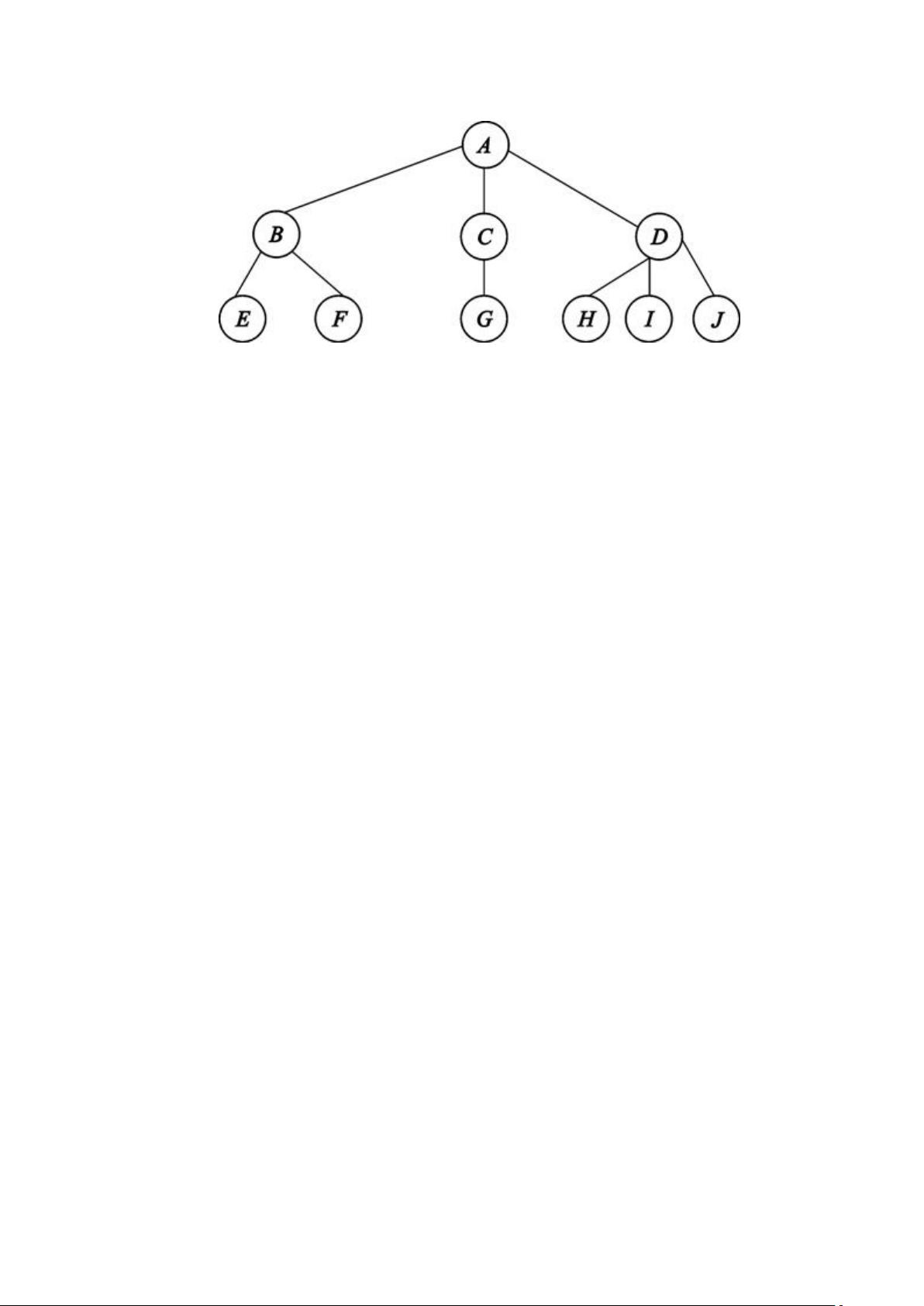
图 5.11
一棵具有 10 个结点的树
树的基本术语有:
孩子、双亲、兄弟:树中某结点的各子树的根称为该结点
的孩子;相应地该结点称为其孩子的双亲;具有相同双亲的结点
互称为兄弟。图 5.11 中,结点 B、C、D 都是结点 A 的孩子,结
点 A 是结点 B 的双亲,也是结点 C、D 的双亲,结点 B、C、D 互
为兄弟。
结点的度:一个结点所拥有的子树的个数称为该结点的度。
图 5.11 中,结点 A 的度为 3,结点 B 的度为 2,结点 E 的度为
0。
叶结点、分支结点:度为 0 的结点称为叶结点,或者称为
终端结点;度不为 0 的结点称为分支结点,或者称为非终端结点。
图 5.11 中,结点 A、B、C、D 为分支结点,结点 E、F、G、H、
I、J 为叶结点。
结点的层数:规定树的根结点的层数为 1,其他任何结点的
层数等于它的双亲结点的层数加 1。图 5.11 中,结点 A 的层数
剩余15页未读,继续阅读
2022-07-11 上传
2022-07-11 上传

是空空呀
- 粉丝: 192
- 资源: 3万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
