机器学习驱动的Web入侵检测新策略
需积分: 19 21 浏览量
更新于2024-09-09
收藏 1.55MB PDF 举报
基于机器学习的Web异常检测是一种新兴的安全防御技术,它利用机器学习算法来弥补传统规则集方法的局限性。随着网络环境的复杂性和攻击手段的不断演变,传统的基于规则的Web防火墙难以有效应对0day攻击和灵活的黑客手段,因为硬编码的规则容易被绕过,且难以适应未知威胁。
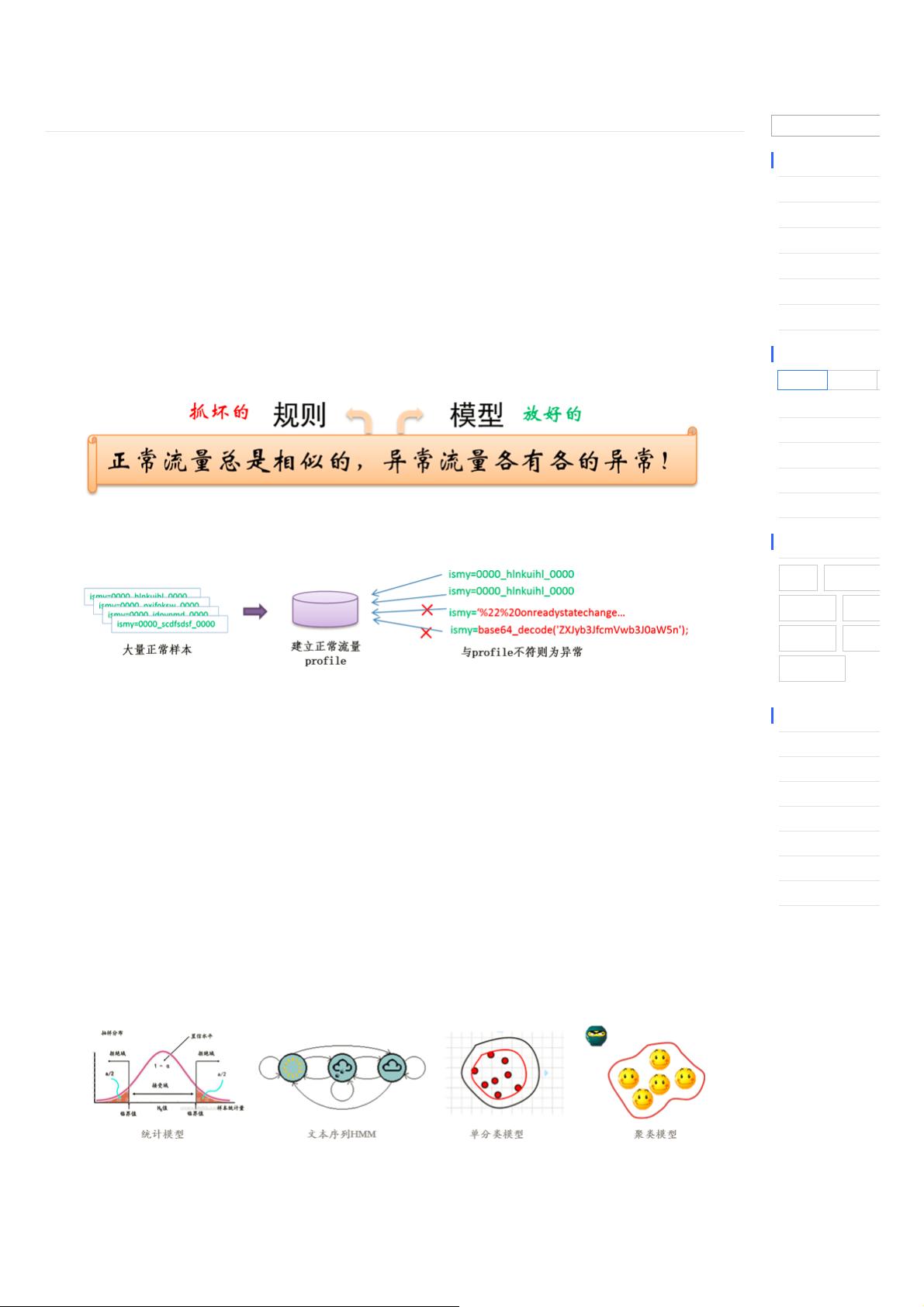
机器学习方法的核心优势在于其能通过大量数据进行自我学习和适应,已广泛应用于图像识别、语音识别和自然语言处理等领域。但在Web入侵检测领域,一个主要挑战是缺乏标注的入侵样本,因为正常访问流量庞大,而异常流量相对稀少且多变,这使得模型的训练和评估变得困难。因此,大部分Web入侵检测系统采用无监督学习策略,通过构建正常访问模式(即Profile),然后将偏离这个模式的行为标记为异常。
构建Profile的方法有多种:
1. **基于统计学习模型**:通过对URL参数的数量、长度统计、字符分布以及访问频率等特征进行量化和分析,构建数学模型,通过统计方法检测异常。这种方法依赖于对正常行为的精确描述,异常检测能力取决于特征选择的准确性和模型的复杂度。
2. **基于文本分析的机器学习模型**:利用自然语言处理技术,如隐马尔可夫模型(HMM)来分析URL参数值的异常模式。这种技术关注文本的序列结构,能够捕捉到潜在的规律,尤其适用于参数值的动态变化。
3. **基于单分类模型**:由于黑样本(即实际入侵行为)稀缺,传统的监督学习方法可能效果不佳。在这种情况下,可以采用基于白样本(正常行为)的异常检测,即仅使用已知的正常访问数据来训练模型,然后识别那些与这些样本显著不同的请求。
基于机器学习的Web异常检测技术通过不断学习和调整,能够在不断变化的网络环境中提供更智能、灵活的防御策略,降低规则维护的成本,并提高对新型威胁的抵御能力。然而,它也面临着数据收集、特征工程、模型解释和实时性等方面的挑战,需要进一步的研究和发展来优化性能和实用价值。
您当前的位置: 安全博客 > 技术研究 > 基于机器学习的web异常检测
基于机器学习的web异常检测
2017年02月08日 10:51 6548
Web防火墙是信息安全的第一道防线。随着网络技术的快速更新,新的黑客技术也层出不穷,为传统规则防火墙带来了挑战。传统web入侵检测技
术通过维护规则集对入侵访问进行拦截。一方面,硬规则在灵活的黑客面前,很容易被绕过,且基于以往知识的规则集难以应对0day攻击;另一方
面,攻防对抗水涨船高,防守方规则的构造和维护门槛高、成本大。
基于机器学习技术的新一代web入侵检测技术有望弥补传统规则集方法的不足,为web对抗的防守端带来新的发展和突破。机器学习方法能够基于
大量数据进行自动化学习和训练,已经在图像、语音、自然语言处理等方面广泛应用。然而,机器学习应用于web入侵检测也存在挑战,其中最大
的困难就是标签数据的缺乏。尽管有大量的正常访问流量数据,但web入侵样本稀少,且变化多样,对模型的学习和训练造成困难。因此,目前大
多数web入侵检测都是基于无监督的方法,针对大量正常日志建立模型(Profile),而与正常流量不符的则被识别为异常。这个思路与拦截规则的构
造恰恰相反。拦截规则意在识别入侵行为,因而需要在对抗中“随机应变”;而基于profile的方法旨在建模正常流量,在对抗中“以不变应万变”,且更
难被绕过。
基于异常检测的web入侵识别,训练阶段通常需要针对每个url,基于大量正常样本,抽象出能够描述样本集的统计学或机器学习模型(Profile)。检
测阶段,通过判断web访问是否与Profile相符,来识别异常。
对于Profile的建立,主要有以下几种思路:
1. 基于统计学习模型
基于统计学习的web异常检测,通常需要对正常流量进行数值化的特征提取和分析。特征例如,URL参数个数、参数值长度的均值和方差、参数字
符分布、URL的访问频率等等。接着,通过对大量样本进行特征分布统计,建立数学模型,进而通过统计学方法进行异常检测。
2. 基于文本分析的机器学习模型
Web异常检测归根结底还是基于日志文本的分析,因而可以借鉴NLP中的一些方法思路,进行文本分析建模。这其中,比较成功的是基于隐马尔科
夫模型(HMM)的参数值异常检测。
3. 基于单分类模型
由于web入侵黑样本稀少,传统监督学习方法难以训练。基于白样本的异常检测,可以通过非监督或单分类模型进行样本学习,构造能够充分表达
白样本的最小模型作为Profile,实现异常检测。
4. 基于聚类模型
通常正常流量是大量重复性存在的,而入侵行为则极为稀少。因此,通过web访问的聚类分析,可以识别大量正常行为之外,小搓的异常行为,进
行入侵发现。
基于统计学习模型
基于统计学习模型的方法,首先要对数据建立特征集,然后对每个特征进行统计建模。对于测试样本,首先计算每个特征的异常程度,再通过模型
对异常值进行融合打分,作为最终异常检测判断依据。
这里以斯坦福大学CS259D: Data Mining for CyberSecurity课程[1]为例,介绍一些行之有效的特征和异常检测方法。
文章分类
社区热门
阿里巴巴直播防控中的实人认证技术
细数iOS上的那些安全防护
Android安全开发之通用签名风险
拥有300万安装量的应用是如何恶意
Android安全开发之ZIP文件目录遍历
标签
短信 积分兑换
漏洞分析 漏洞预警
安全报告 病毒分析
阿里聚安全
友情链接
阿里巴巴集团
阿里云计算
淘宝网
天猫
支付宝
钱盾
E安全
请输入关键词
技术研究
安全资讯
安全报告
安全漏洞
病毒分析
活动沙龙
技术研究 安全资讯
登录
管理后台
首 页 产品与服务 解决方案 文档中心 安全博客 渠道商申请 风险态势
应用更安全,用户更放心!
立即登录
下载后可阅读完整内容,剩余6页未读,立即下载
2021-05-20 上传
2023-08-07 上传
2023-02-06 上传
2023-06-10 上传
2023-05-14 上传
2023-03-26 上传
2024-06-15 上传
2024-07-05 上传
2024-07-04 上传

missmadder
- 粉丝: 1
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
