改进的CNN模型:解决会话推荐中的长程依赖问题
下载需积分: 9 | PDF格式 | 2.69MB |
更新于2024-08-10
| 197 浏览量 | 举报
本文档《A Simple but Hard-to-Beat Baseline for Session-based》探讨了在基于会话的推荐系统中,卷积神经网络(Convolutional Neural Networks, CNNs)模型的应用。近年来,CNNs被应用于top-N会话推荐任务,将用户在过去会话中交互的一系列项目映射到一个二维的潜在空间,并视作图像进行处理,通过卷积和池化操作来提取特征。
作者首先对现有的基于CNN的会话推荐模型进行了深入剖析。他们发现,这种模型在处理长范围依赖性时存在局限性。会话中的项目序列通常包含着复杂的时空关系,而传统CNN模型可能无法有效地捕捉这些长期依赖。生成模型以及网络架构的设计可能并未充分利用这些上下文信息,导致性能受限。
为了改进这一问题,论文提出了一个新的简单但难以超越的基线方法。该方法针对长距离依赖的建模进行了优化,可能包括引入更先进的编码策略,如自注意力机制或者时间递归结构,以便更好地捕捉项目之间的动态关联。这可能涉及到设计更精细的卷积核,或者利用记忆单元来存储和处理历史信息,确保模型能够学习并适应用户的兴趣随时间的变化。
此外,文章可能还讨论了如何在保持模型简洁的同时,提高其效率和准确性。可能的方法可能涉及参数共享、剪枝或量化技术,以减少计算复杂度。论文可能会提供实验结果,展示新方法在各种评估指标上(如准确率、召回率和NDCG)相较于现有模型的显著优势。
总结来说,这篇论文的核心贡献在于提出了一种针对会话推荐任务的创新CNN架构,旨在解决长程依赖性问题,且在实验证明了其在性能上的优越性。这对于理解和提升基于会话的推荐系统,尤其是在处理用户行为序列复杂性方面,具有重要的理论和实践价值。
A Simple but Hard-to-Beat Baseline for Session-based
Recommendations
Fajie Yuan
∗†
University of Glagow
Glasgow, UK
f.yuan.1@research.gla.ac.uk
Alexandros Karatzoglou
Telefonica Research
Barcelona, Spain
alexandros.karatzoglou@gmail.com
Ioannis Arapakis
Telefonica Research
Barcelona, Spain
arapakis.ioannis@gmail.com
Joemon M Jose
University of Glagow
Glasgow, UK
joemon.jose@glasgow.ac.uk
Xiangnan He
National University of Singapore
Singapore
xiangnanhe@gmail.com
ABSTRACT
Convolutional Neural Networks (CNNs) models have been recently
introduced in the domain of top-
N
session-based recommendations.
An ordered collection of past items the user has interacted with in
a session (or sequence) are embedded into a 2-dimensional latent
matrix, and treated as an image. The convolution and pooling opera-
tions are then applied to the mapped item embeddings. In this paper,
we rst examine the typical session-based CNN recommender and
show that both the generative model and network architecture are
suboptimal when modeling long-range dependencies in the item
sequence. To address the issues, we introduce a simple, but very
eective generative model that is capable of learning high-level
representation from both short- and long-range item dependencies.
The network architecture of the proposed model is formed of a stack
of holed convolutional layers, which can eciently increase the
receptive elds without relying on the pooling operation. Another
contribution is the eective use of residual block structure in recom-
mender systems, which can ease the optimization for much deeper
networks. The proposed generative model attains state-of-the-art
accuracy with less training time in the session-based recommenda-
tion task. It accordingly can be used as a powerful recommendation
baseline to beat in future, especially when there are long sequences
of user feedback.
1 INTRODUCTION
Leveraging sequences of user-item interactions (e.g., clicks or pur-
chases) to improve real-world recommender systems has become
increasingly popular in recent years. These sequences are auto-
matically generated when users interact with online systems in
sessions (e.g., shopping session, or music listening session). For
example, users on Last.fm
1
or Soundcloud
2
typically enjoy a series
of songs during a certain time period without any interruptions, i.e.,
a listening session. The set of songs played in one session usually
have strong correlations [
7
], e.g., sharing the same album, artist,
or genre. Accordingly, a good recommender system is supposed to
generate recommendations by taking advantage of these sequential
patterns in the session.
∗
Work performed while at Telefonica Research, Spain.
†
Preprint. Work in progress.
1
https://www.last.fm
2
https://www.soundcloud.com
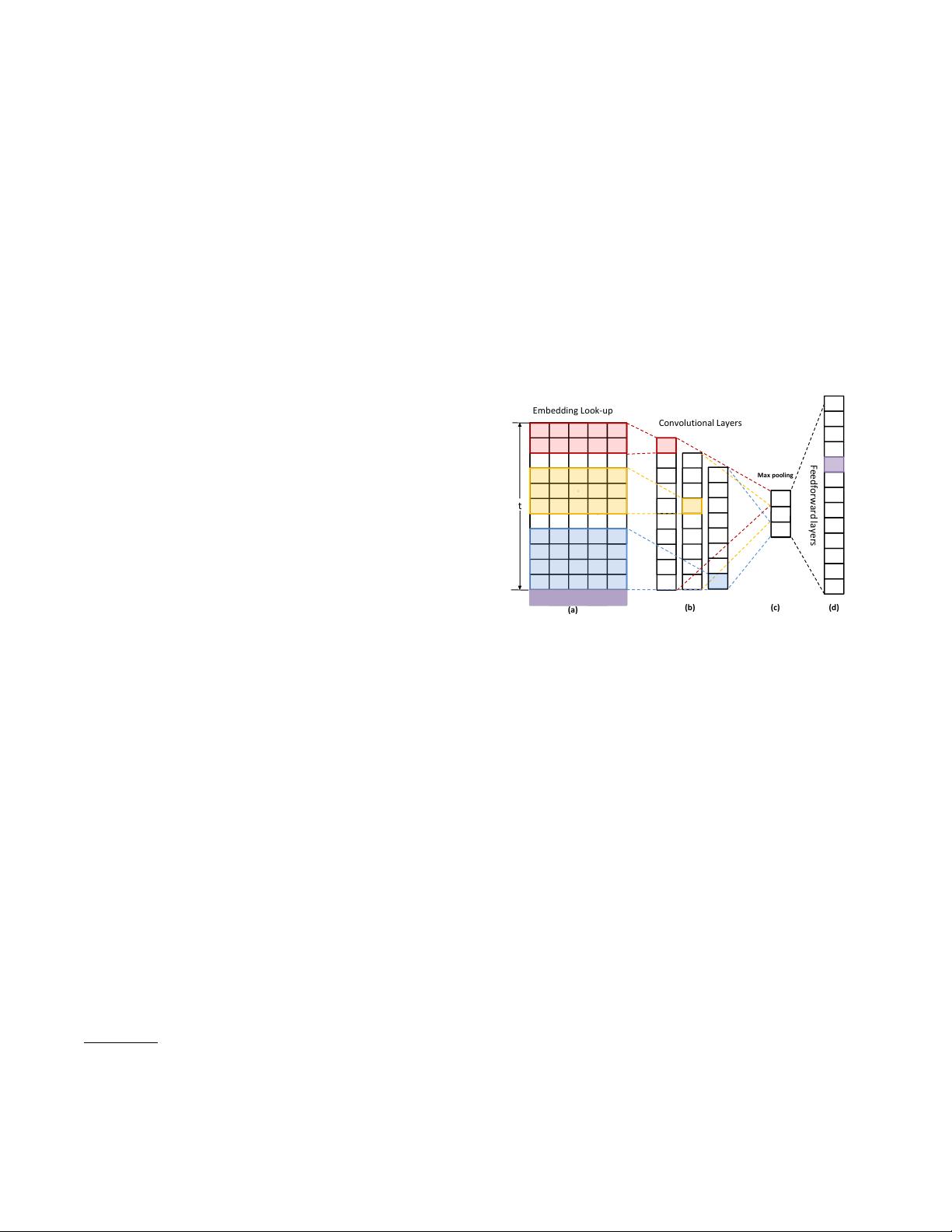
Embedding Look-up
Convolutional Layers
Max pooling
Feedforward layers
t
(a)
(b)
(c)
(d)
Figure 1: The basic structure of Caser [34]. The red, yellow and blue
regions denotes a
2
×k,
3
×k and
4
×k convolution lter respectively,
where k = 5. The purple row stands for the true next item.
A class of models often employed for these sequences of item
interactions are the Recurrent Neural Networks (RNNs). RNNs typ-
ically generate a softmax output where high probabilities represent
the most relevant recommendations. While eective, these RNN-
based models, such as [
3
,
17
,
28
], depend on a hidden state of the
entire past that cannot fully utilize parallel computation within
a sequence [
9
]. Thus their speed is limited in both training and
evaluation.
By contrast, training CNNs does not depend on the computations
of the previous time step and therefore allow parallelization over
every element in a sequence. Inspired by the successful use of CNNs
in image tasks, a newly proposed sequential recommender, referred
to as Caser [
34
], abandoned RNN structures, proposing instead
a convolutional sequence embedding model, and demonstrated
that this CNN-based recommender is able to achieve comparable
or superior performance to the popular RNN model in the top-
N
sequential recommendation task. The basic idea of the convolution
processing is to treat the
t × k
embedding matrix as the “image"
of the previous
t
interactions in
k
dimensional latent space and
regard the sequential pattens as local features of the “image". A max
pooling operation that only preserves the maximum value of the
convolutional layer is performed to increase the receptive eld, as
well as dealing with the varying length of input sequences. Fig. 1
depicts the key architecture of Caser.
arXiv:1808.05163v3 [cs.IR] 30 Aug 2018
下载后可阅读完整内容,剩余9页未读,立即下载
相关推荐






shuterlo
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- SAP NetWeaver与开源框架集成实战
- WEB设计必备资源网址收藏
- Linux内核深度解析:历史、设计与影响
- 实现用户单点登录系统
- 网络软件架构设计:风格与原则详解
- JSP开发环境配置全步骤详解
- MyEclipse 6 Java初学者指南:SSH, JSF, JPA 实战
- 刘长炯著:MyEclipse 6 Java EE开发指南
- Ubuntu 8.04 教程:快速入门与安装指南
- 进销存系统需求规格说明书1.0版
- JIRA使用手册:项目管理和问题跟踪
- MyEclipse快捷键大全:提升Java开发效率
- 金融电子化系统建设的生命周期法
- C++/C编程高质量指南:从命名到内存管理详解
- JGuard安全框架入门指南
- 特征驱动开发(FDD)概述与核心流程
