使用 SVAR 进行数据驱动识别的理论与实证研究
下载需积分: 21 | PDF格式 | 809KB |
更新于2024-07-09
| 98 浏览量 | 举报
"这篇研究论文探讨了一种基于数据的识别理论在结构向量自回归(SVAR)模型和联立方程模型(SEM)中的应用。作者Nikolay Arefiev提出了一种新方法,利用可测试的识别限制来识别具有正交结构冲击的模型,这种方法在满足稀疏条件的情况下,可以生成一组完整的识别限制。文中还通过估计包含6个变量的美国经济SVAR货币模型展示了该方法的实际应用,揭示了信息传递渠道在经济中的重要性。"
这篇工作论文深入研究了识别理论在统计建模中的核心问题,特别是对于结构模型如SVAR和SEM。SVAR是一种用于分析经济或金融时间序列数据的统计工具,它允许研究者考虑多个变量之间的相互依赖关系。SEM则是一种更广泛的框架,它可以处理多个相互关联的方程,这些方程共同描述了经济系统。
识别是SVAR和SEM分析中的关键步骤,因为它决定了模型参数的独特解释。通常,这需要外部信息或识别假设来约束模型,以便从中提取有意义的经济解释。在本文中,作者提出了一种新的数据驱动的识别方法,它结合了概率图模型(PGM)的理论与传统的识别理论。PGM是一种表示变量之间条件依赖性的图形工具,它在统计学和机器学习中有广泛应用。
Arefiev的方法特别关注模型的稀疏性,即模型中只有少数非零元素。在满足稀疏条件的情况下,这种方法能产生一组可测试的包含和排除条件,这些条件足以实现模型的完全识别。这意味着研究者可以通过检验这些条件来确认模型的结构,而无需依赖过于复杂的识别策略。
在实际应用部分,作者估计了一个SVAR货币模型,该模型包含了美国经济的6个关键变量,其中除一个识别限制外,其余变量的识别都是基于可测试的限制。这种方法的优越性在于,它能够生成更窄的脉冲响应函数置信区间,避免了如“价格难题”等常见的识别问题,并能清晰揭示不同变量之间的信息传递机制。
通过这种方式,该研究揭示了结构冲击如何通过各种渠道在整个经济系统中传播,这对于理解政策影响和预测经济动态至关重要。这种方法的创新之处在于它提供了一个统一的框架,将概率图模型与SVAR和SEM的识别理论相结合,为复杂经济系统的建模提供了新的思路和工具。
9
Table 1. Testable identification restrictions for model (1)
Identification restriction Testable property of PDF
z
1
6→ y
2
, so b
21
= 0 corr(z
1
, y
2
|z
2
, y
1
, y
3
) = 0
z
1
6→ y
3
, so b
31
= 0 corr(z
1
, y
3
|z
2
, y
1
, y
2
) = 0
z
2
6→ y
3
, so b
32
= 0 corr(z
2
, y
3
|z
1
, y
1
, y
2
) = 0
There are 2 independent paths
rank (Π (y
1
, y
2
|z
1
, z
2
)) = 2
connecting {z
1
, z
2
} with {y
1
, y
2
}
z
1
y
1
y
2
y
3
z
2
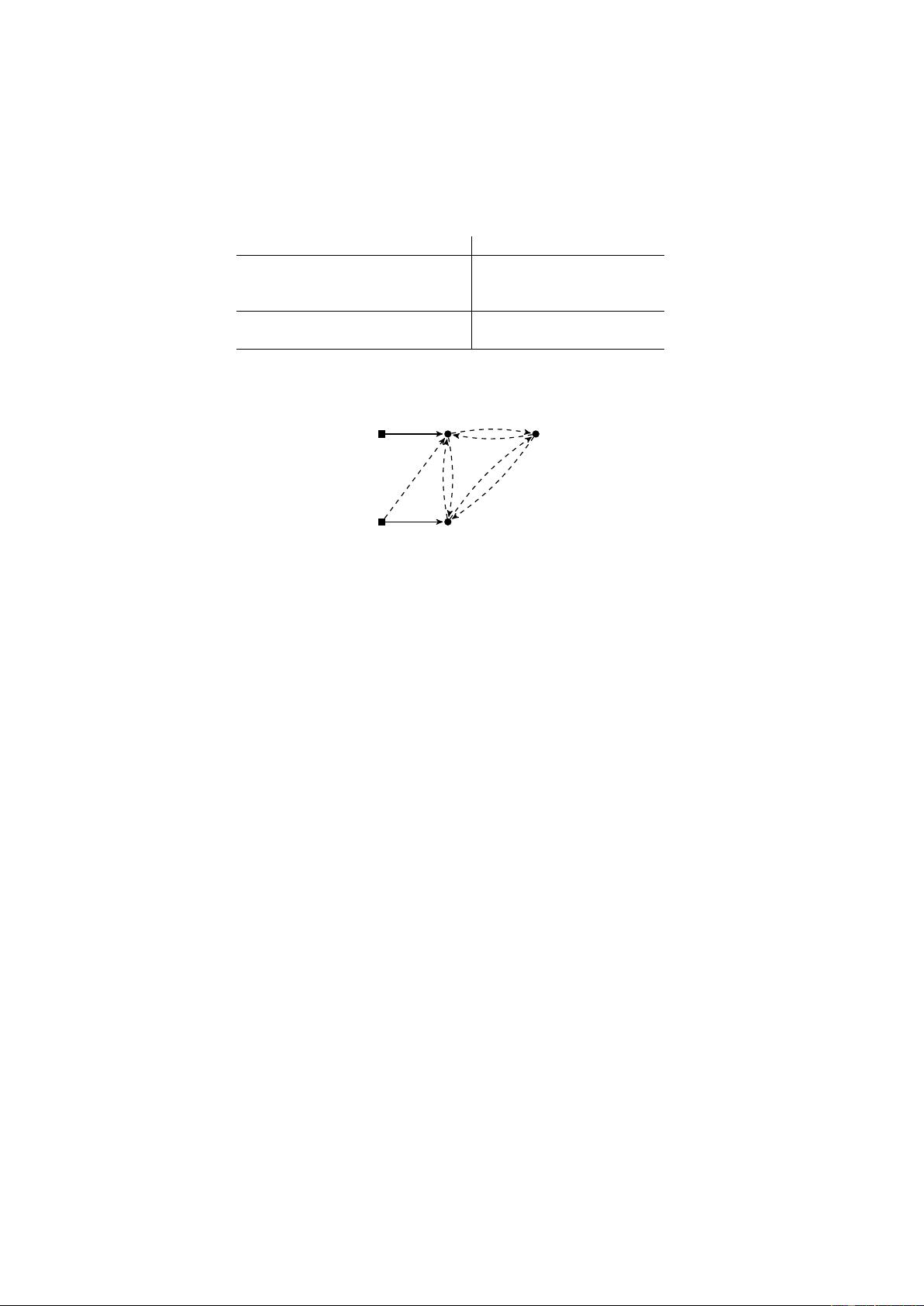
Figure 4. Summary of testable inclusion and exclusion restrictions.
minus the number of rows of Π (y
1
, y
2
|z
1
, z
2
) plus 1, which in the considered example is 1. Finally, I calcu-
late the df smallest eigenvalues λ
1
, . . . , λ
df
of product Π (y
1
, y
2
|z
1
, z
2
) × Π (z
1
, z
2
|y
1
, y
2
) and calculate the
statistic:
(4) s = T
df
X
j=1
ln (1 − λ
j
)
where T is the number of observations. Under the null hypothesis that rank (Π (y
1
, y
2
|z
1
, z
2
)) < 2, the
statistic is asymptotically distributed as χ
2
(df).
Table 1 and Figure 4 summarize the testable inclusion and exclusion restrictions sufficient for the full
identification of the structural model. Each absent edge in Figure 4 is associated with a testable exclusion
restriction, each solid edge is associated with a testable inclusion restriction, and the existence of the dashed
edges is not important for identification, since the model is fully identified whether or not these edges are
present in the causal diagram.
Now compare the true structural model:
(5)
1 0 0
−a
21
1 0
−a
31
−a
32
1
y
1
y
2
y
3
=
c
1
c
2
c
3
+
b
11
0
0 b
22
0 0
z
1
z
2
+
ε
1
ε
2
ε
3


剩余58页未读,继续阅读
相关推荐



weixin_38597889
- 粉丝: 12
 我的内容管理
展开
我的内容管理
展开








最新资源
- Windows平台Redis服务32位程序部署指南
- 复古风格五一劳动节PPT模板,24张幻灯片设计
- s7200PPI驱动程序:编程电缆链接与下载指南
- 简易电商系统设计:2019年毕业项目实现与流程解析
- YUV数据检测专用工具:YUVviewer
- Android平台的后五个项目技术解析
- 掌握WinSock多线程编程,实现高效MFC服务器交互
- Eclipse插件ecside开发所需jar包清单
- HiveFivesChallenge:团队认可API的实现与管理功能
- 严蔚敏《数据结构C版》完整代码汇总
- C++ Builder入门基础代码参考教程
- 光电自准直仪的自动瞄准与读值技术研究
- 计算机安全教案经典教程全方位解析
- C++实现BMP图片信息隐藏技术详解
- RMActionController:iOS中实现自定义视图交互的新框架
- 构建基于Delphi与现场总线的污水处理监控系统











