HBase大数据查询实践:优化读写性能
PDF格式 | 496KB |
更新于2024-08-29
| 47 浏览量 | 举报
"大数据查询——HBase读写设计与实践"
在大数据处理领域,随着数据量的不断增长,传统的数据库系统往往难以应对高并发的写入和读取需求。本项目针对这一挑战,从Oracle数据库迁移至HBase,以解决check和opinion两张历史数据表的在线查询问题。HBase作为一种分布式、列族式的NoSQL数据库,非常适合存储大规模半结构化数据,并能提供高效的实时查询。
需求分析方面,check表的累计数据量超过5000万行,总计11GB,而opinion表的数据量更是达到了3亿行,约100GB。每天新增数据约50万行,且只做插入操作,不涉及更新。查询需求主要包括:基于check_id获取check表的多条记录列表,以及基于bussiness_no和buss_type查询opinion表并返回记录列表。查询响应时间要求在2秒内,日查询频率约为100笔。
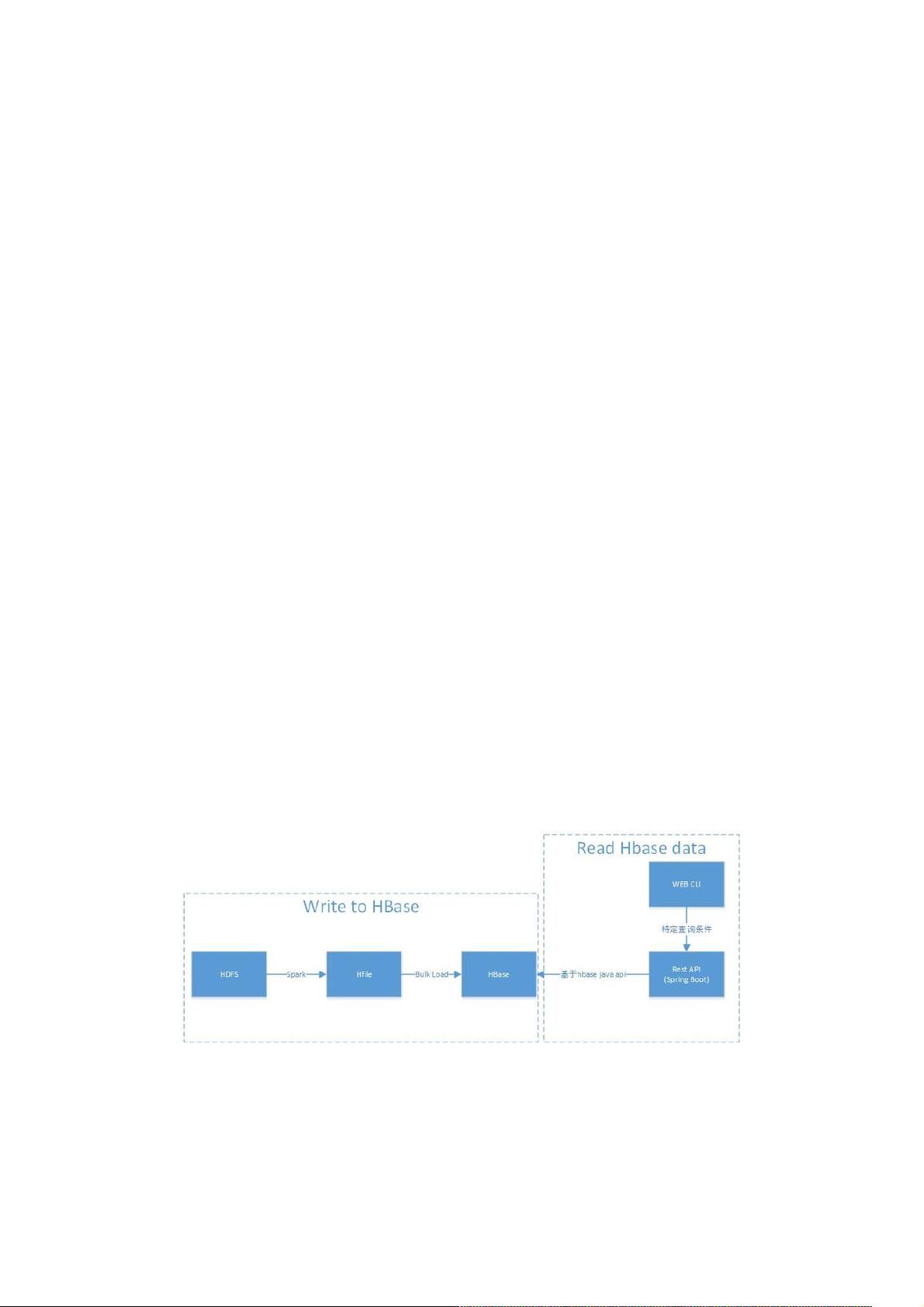
在技术选型上,HBase因其大数据存储能力和实时查询性能成为首选。在设计读取策略时,主要依赖于HBase的RowKey设计以及get和scan等API。RowKey的设计至关重要,因为它直接影响查询效率。对于写入策略,文章重点介绍了采用Spark+BulkLoad的方式,这种方式避免了写WAL(Write-Ahead Log)和数据flush及split,提高了写入效率。
BulkLoad的过程包括通过MapReduce或Spark生成HFile,然后将这些文件复制到HBase的HDFS目录下,最后通知RegionServer加载数据。Spark的并行处理能力使其在生成HFile时能有效提高效率,尤其适用于批量写入大数据量的场景。相比于直接使用Java API或MapReduce作业写入,BulkLoad显著降低了对RegionServer的压力,提升了系统的整体性能。
在实践中,优化RowKey设计可以进一步提升查询效率。例如,将最常用于查询的字段作为RowKey的一部分,可以减少数据扫描的范围。同时,合理的Region分裂策略也能保证负载均衡,防止热点现象出现。
本项目通过将历史数据存储从Oracle迁移到HBase,结合Spark的BulkLoad策略,成功解决了大数据量下的在线查询问题,实现了高性能、低延迟的系统改造。这为类似业务场景提供了有价值的参考,展示了大数据环境下如何有效利用NoSQL数据库进行数据处理和查询。
大数据查询大数据查询——HBase读写设计与实践读写设计与实践
背景介绍
本项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查
询。原实现基于 Oracle 提供存储查询服务,随着数据量的不断增加,在写入和读取过程中面临性能问题,且历史数据仅供业
务查询参考,并不影响实际流程,从系统结构上来说,放在业务链条上游比较重。本项目将其置于下游数据处理 Hadoop 分布
式平台来实现此需求。下面列一些具体的需求指标:
1. 数据量:目前 check 表的累计数据量为 5000w+ 行,11GB;opinion 表的累计数据量为 3 亿 +,约 100GB。每日增量约为
每张表 50 万 + 行,只做 insert,不做 update。
2. 查询要求:check 表的主键为 id(Oracle 全局 id),查询键为 check_id,一个 check_id 对应多条记录,所以需返回对应记
录的 list; opinion 表的主键也是 id,查询键是 bussiness_no 和 buss_type,同理返回 list。单笔查询返回 List 大小约 50 条以
下,查询频率为 100 笔 / 天左右,查询响应时间 2s。
技术选型
从数据量及查询要求来看,分布式平台上具备大数据量存储,且提供实时查询能力的组件首选 HBase。根据需求做了初步的
调研和评估后,大致确定 HBase 作为主要存储组件。将需求拆解为写入和读取 HBase 两部分。
读取 HBase 相对来说方案比较确定,基本根据需求设计 RowKey,然后根据 HBase 提供的丰富 API(get,scan 等)来读取
数据,满足性能要求即可。
写入 HBase 的方法大致有以下几种:
1. Java 调用 HBase 原生 API,HTable.add(List(Put))。
2. MapReduce 作业,使用 TableOutputFormat 作为输出。
3. Bulk Load,先将数据按照 HBase 的内部数据格式生成持久化的 HFile 文件,然后复制到合适的位置并通知 RegionServer
,即完成海量数据的入库。其中生成 Hfile 这一步可以选择 MapReduce 或 Spark。
本文采用第 3 种方式,Spark + Bulk Load 写入 HBase。该方法相对其他 2 种方式有以下优势:
1. BulkLoad 不会写 WAL,也不会产生 flush 以及 split。
2. 如果我们大量调用 PUT 接口插入数据,可能会导致大量的 GC 操作。除了影响性能之外,严重时甚至可能会对 HBase 节
点的稳定性造成影响,采用 BulkLoad 无此顾虑。
3. 过程中没有大量的接口调用消耗性能。
4. 可以利用 Spark 强大的计算能力。
图示如下:
设计
环境信息
Hadoop 2.5-2.7
HBase 0.98.6
Spark 2.0.0-2.1.1
Sqoop 1.4.6
下载后可阅读完整内容,剩余4页未读,立即下载
相关推荐





weixin_38642636
- 粉丝: 12
- 资源: 931
 我的内容管理
展开
我的内容管理
展开







