CentOS7安装Hadoop2.5.2与Spark1.1.1指南
需积分: 12 106 浏览量
更新于2024-07-21
收藏 2.94MB PDF 举报
"该文档是关于在CentOS7系统上安装Hadoop 2.5.2和Spark 1.1.1的详细步骤,适用于大数据处理的初学者或需要搭建Hadoop和Spark环境的IT从业者。文档作者建议在非操作系统盘符下安装以避免权限问题,并提供了相关软件的下载链接,包括Hadoop、Scala、Spark和VMware的下载地址。在安装过程中,提到了可能遇到的C盘权限问题以及如何解决。此外,文档还详细介绍了如何在VMware上安装虚拟机VMware Workstation 10,配置CentOS7的操作系统,包括虚拟机的命名、内存设置、网络配置等。"
本文档主要涵盖了以下几个重要的知识点:
1. **Hadoop安装**:Hadoop是Apache基金会的一个开源项目,用于分布式存储和计算的大数据处理框架。Hadoop 2.5.2版本是Hadoop的稳定版本之一,提供高可用性、容错性和扩展性。在CentOS7上安装Hadoop涉及下载Hadoop的tar.gz文件,解压,配置环境变量,修改配置文件如`core-site.xml`、`hdfs-site.xml`、`yarn-site.xml`和`mapred-site.xml`,以及初始化HDFS和启动相关服务。
2. **Spark安装**:Spark是一个快速、通用且可扩展的数据处理引擎,它提供了内存计算以提升大数据处理速度。Spark 1.1.1是早期版本,具备基本的功能,适合学习和基础应用。安装Spark需要下载对应版本的tar.gz文件,同样进行解压和环境变量配置。此外,由于Spark依赖Scala,因此还需要安装Scala环境。
3. **虚拟机环境搭建**:在Windows系统上,通过VMware创建一个运行CentOS7的虚拟机是常见的做法。这包括下载VMware软件并安装,配置虚拟机的硬件参数如内存大小,设置虚拟网络为NAT模式,以及分配静态IP地址以便于后续的网络通信。
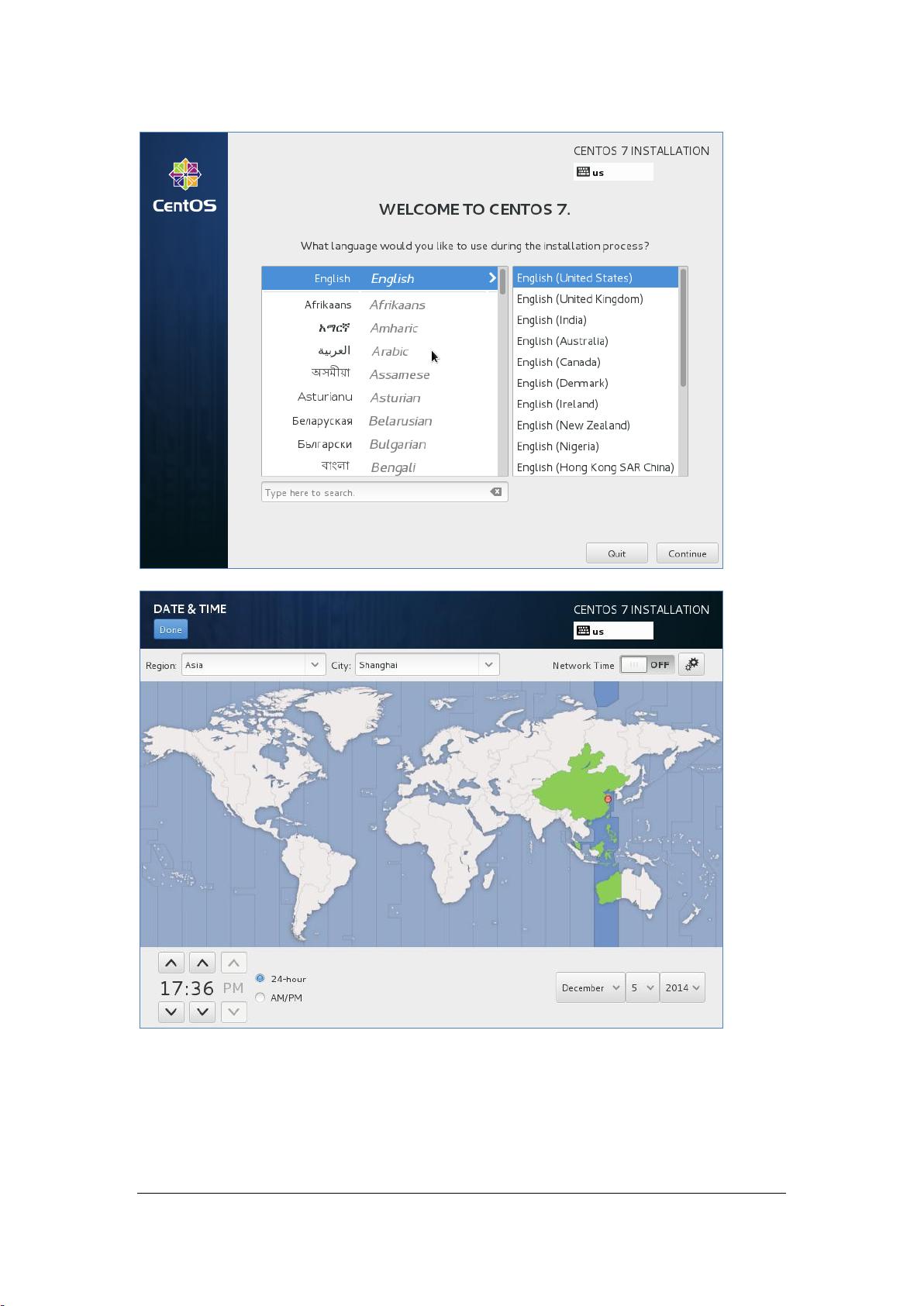
4. **CentOS7安装与配置**:在虚拟机中安装CentOS7涉及到语言选择、时间区域设置,以及网络配置。确保网络连接正常是进行Hadoop和Spark安装的关键,通常会配置静态IP以保持网络的稳定性。
5. **权限管理**:在Windows系统中,可能会遇到因C盘权限问题导致无法写入的情况。解决方法是修改文件夹权限,将当前用户添加到具有完全控制权限的组中。
6. **网络配置**:在VMware中,使用虚拟网络编辑器可以设置虚拟机的网络连接方式,配置静态IP地址、子网掩码、网关和DNS,这对于集群间的通信至关重要。
这个文档提供了从零开始在CentOS7上搭建Hadoop和Spark环境的详细步骤,对于想要学习和实践大数据处理的用户非常有帮助。在实际操作中,需要注意每个步骤的细节,尤其是配置文件的修改和网络设置,以确保服务能够正常启动和运行。
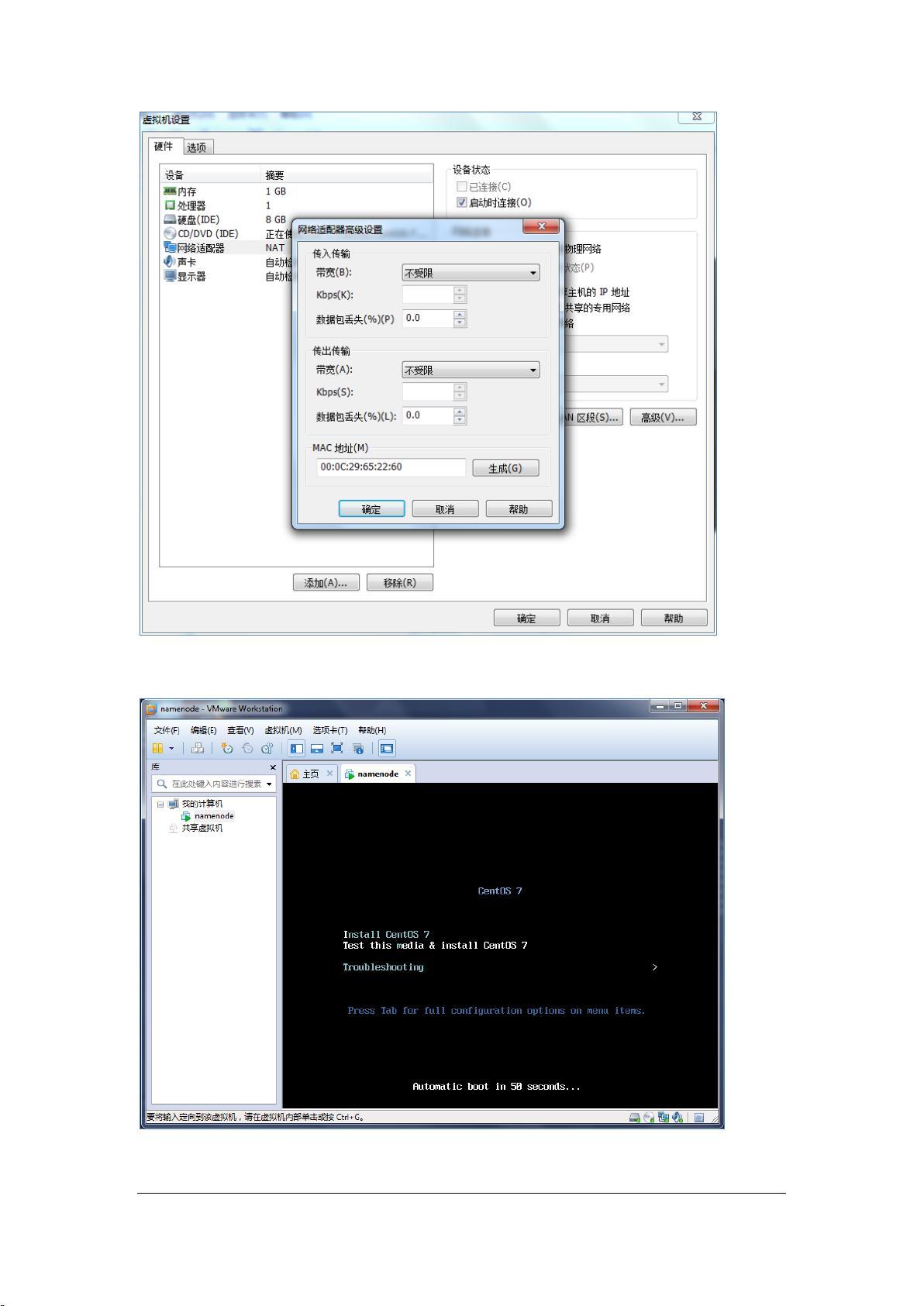
7 / 38 talonliu@163.com
输入 MAC 值,后面配置如果用到请安装此方式查看
开启虚拟机
选语言种类,下一步
剩余37页未读,继续阅读
2019-10-12 上传
2018-03-28 上传
2021-10-01 上传
2022-07-10 上传
2020-06-06 上传
2022-11-11 上传
2021-02-03 上传
2016-12-01 上传









