Kafka深度解析:分布式日志系统与消息中间件
79 浏览量
更新于2024-08-29
收藏 778KB PDF 举报
"浅谈分布式消息技术Kafka"
Kafka是一个高度可扩展和高性能的分布式消息系统,最初由LinkedIn设计,并于2010年成为Apache软件基金会的顶级项目。Kafka的主要功能是作为日志收集系统和消息中间件,它在大数据处理和实时流处理中扮演着关键角色。
Kafka的核心设计目标包括:
1. 高效的消息持久化:Kafka以O(1)的时间复杂度实现消息持久化,这意味着无论数据量多大,其访问速度都能保持恒定,确保了大规模数据处理的高效性。
2. 高吞吐量:Kafka能够在低成本的硬件上实现每秒处理数十万条消息,这使得它在大数据环境中具有极高的性能表现。
3. 分区与复制:消息被分发到不同的partition中,每个partition在Kafka集群内有多个副本,增强了系统的容错性和可用性。同时,每个partition内部保持消息顺序,保证了数据的一致性。
4. 处理灵活性:Kafka支持实时和离线数据处理,满足不同场景的需求。
在Kafka架构中,几个关键组件协同工作:
- Broker:是Kafka集群中的服务器节点,负责存储和转发消息。
- Topic:主题是消息的分类,用户可以创建多个主题来区分不同类型的数据。
- Partition:主题被分成多个分区,每个分区是一个有序的消息队列。分区有助于提高并行处理能力和负载均衡。
- Segment:partition由多个segment组成,每个segment包含一定数量的消息。
- Offset:在每个partition中,消息被分配唯一的offset,用于定位和追踪消息。
- Producer:生产者是消息的发布者,它们将消息发送到Kafka的broker。
- Consumer:消费者从broker读取消息,可以是实时消费或者批量消费。
- Consumer Group:消费者可以分组,每个组内的消费者会共享消息消费,确保每个消息只被一个消费者处理,实现负载均衡和容错。
Kafka通过Zookeeper进行集群管理,如选举领导者、维护配置信息和处理消费者组的变化。Producer使用推送(push)模式将消息发布到Broker,而Consumer使用拉取(pull)模式从Broker订阅和消费消息。
Kafka凭借其强大的消息处理能力、高可用性和可扩展性,广泛应用于日志聚合、实时流处理、数据集成等多个领域,是现代大数据架构中的重要组成部分。
浅谈分布式消息技术浅谈分布式消息技术Kafka
Kafka的基本介绍
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也
可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并
成为顶级开源项目。
主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
1.以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
2.高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
3.支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
4.同时支持离线数据处理和实时数据处理。
Kafka的设计原理分析
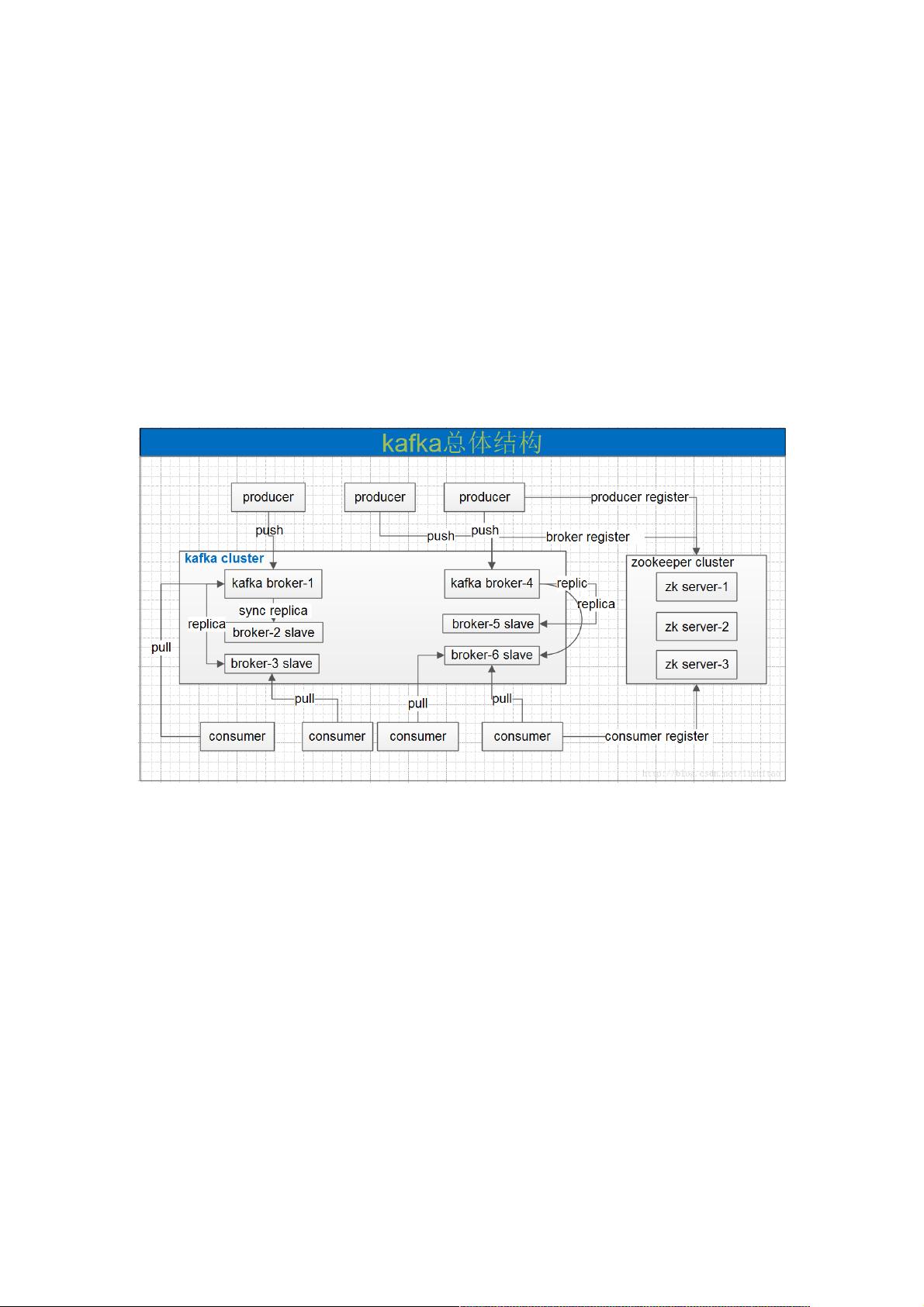
一个典型的kafka集群中包含若干producer,若干broker,若干consumer,以及一个Zookeeper集群。Kafka通过Zookeeper管
理集群配置,选举leader,以及在consumer group发生变化时进行rebalance。producer使用push模式将消息发布到
broker,consumer使用pull模式从broker订阅并消费消息。
Kafka专用术语:
1.Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
2.Topic:一类消息,Kafka集群能够同时负责多个topic的分发。
3.Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
4.Segment:partition物理上由多个segment组成。
5.offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都
有一个连续的序列号叫做offset,用于partition唯一标识一条消息。
6.Producer:负责发布消息到Kafka broker。
7.Consumer:消息消费者,向Kafka broker读取消息的客户端。
8.Consumer Group:每个Consumer属于一个特定的Consumer Group。
Kafka数据传输的事务特点
at most once:最多一次,这个和JMS中"非持久化"消息类似,发送一次,无论成败,将不会重发。消费者fetch消息,然后保
存offset,然后处理消息;当client保存offset之后,但是在消息处理过程中出现了异常,导致部分消息未能继续处理。那么此
后"未处理"的消息将不能被fetch到,这就是"at most once"。
下载后可阅读完整内容,剩余7页未读,立即下载
2020-08-20 上传
2018-08-14 上传
2021-01-07 上传
2020-08-25 上传
2021-10-17 上传
2021-02-25 上传
2020-08-28 上传
2022-05-21 上传
2021-07-14 上传

weixin_38675465
- 粉丝: 6
- 资源: 958
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
