Hadoop集群安装配置与详解
需积分: 18 173 浏览量
更新于2024-07-19
收藏 4.05MB DOCX 举报
"Hadoop安装与配置"
在深入探讨Hadoop的安装与配置之前,我们先来了解一下这个开源分布式计算平台的基础知识。Hadoop是Apache软件基金会的重要项目,它提供了一个可扩展、容错性强的分布式计算框架。核心组件包括Hadoop分布式文件系统(HDFS)和MapReduce,两者共同构建了大数据处理的基础。
1.1 Hadoop简介
Hadoop的设计目标是处理和存储海量数据,其灵感来源于Google的论文。HDFS是Hadoop的核心部分,它是一个分布式文件系统,能存储海量数据并确保高可用性。MapReduce则是一种编程模型,用于处理和生成大规模数据集,它将大型任务拆分为许多小任务,在多台机器上并行处理,然后汇总结果。
Hadoop集群由两类节点组成:Master节点和Slave节点。在HDFS中,Master节点通常称为NameNode,负责管理文件系统的元数据和客户端的访问控制。Slave节点,即DataNode,存储实际的数据块并响应来自NameNode的指令。在MapReduce框架中,Master节点是JobTracker,它负责调度任务和监控TaskTracker,后者运行在每个Slave节点上,执行分配给它的任务。
1.2 环境说明
为了进行Hadoop的安装与配置,我们需要一个由4个节点组成的集群,包括1个Master节点和3个Slave节点。所有节点应处于局域网内,彼此之间能够通信。系统环境为CentOS 6.0,且所有节点上都有相同用户hadoop。Master节点承担NameNode和JobTracker的角色,而Slave节点作为DataNode和TaskTracker,负责数据存储和任务执行。为了提高可用性和容错性,通常会有一个备用的Master节点,以防主Master故障。
安装Hadoop时,首先需要安装Java环境,因为Hadoop依赖Java运行。接着,下载并解压Hadoop的二进制包,配置环境变量,如HADOOP_HOME,以及Hadoop配置文件如`core-site.xml`、`hdfs-site.xml`、`mapred-site.xml`和`yarn-site.xml`。在这些配置文件中,我们需要指定NameNode和DataNode的地址,以及JobTracker和TaskTracker的位置。
在配置HDFS时,需要设置数据块复制因子,这决定了数据的冗余程度和容错能力。同时,需要创建HDFS的目录结构,例如通过`hadoop fs -mkdir /user`命令创建用户目录。MapReduce的配置则涉及到JobTracker和TaskTracker的相关参数,以及内存分配等。
集群启动后,可以通过`start-dfs.sh`和`start-yarn.sh`命令启动HDFS和YARN服务。使用`jps`命令检查各个节点上的进程是否正常运行。为了测试集群,可以写一个简单的MapReduce程序,例如WordCount,将其提交到集群执行,验证Hadoop的工作状态。
为了确保高可用性,还需要配置Hadoop的HA(High Availability)特性,这通常涉及NameNode HA和ResourceManager HA。NameNode HA可以通过设置多个NameNode实例,并启用ZooKeeper来实现故障切换。类似地,ResourceManager HA使用standby模式的ResourceManager来备份active模式的ResourceManager。
总结起来,Hadoop的安装与配置是一个复杂的过程,需要对分布式系统有深入理解。正确配置环境、设置好各个节点的角色、调整参数以及确保高可用性,是成功搭建Hadoop集群的关键。通过实践和学习,可以掌握这一强大的大数据处理工具。
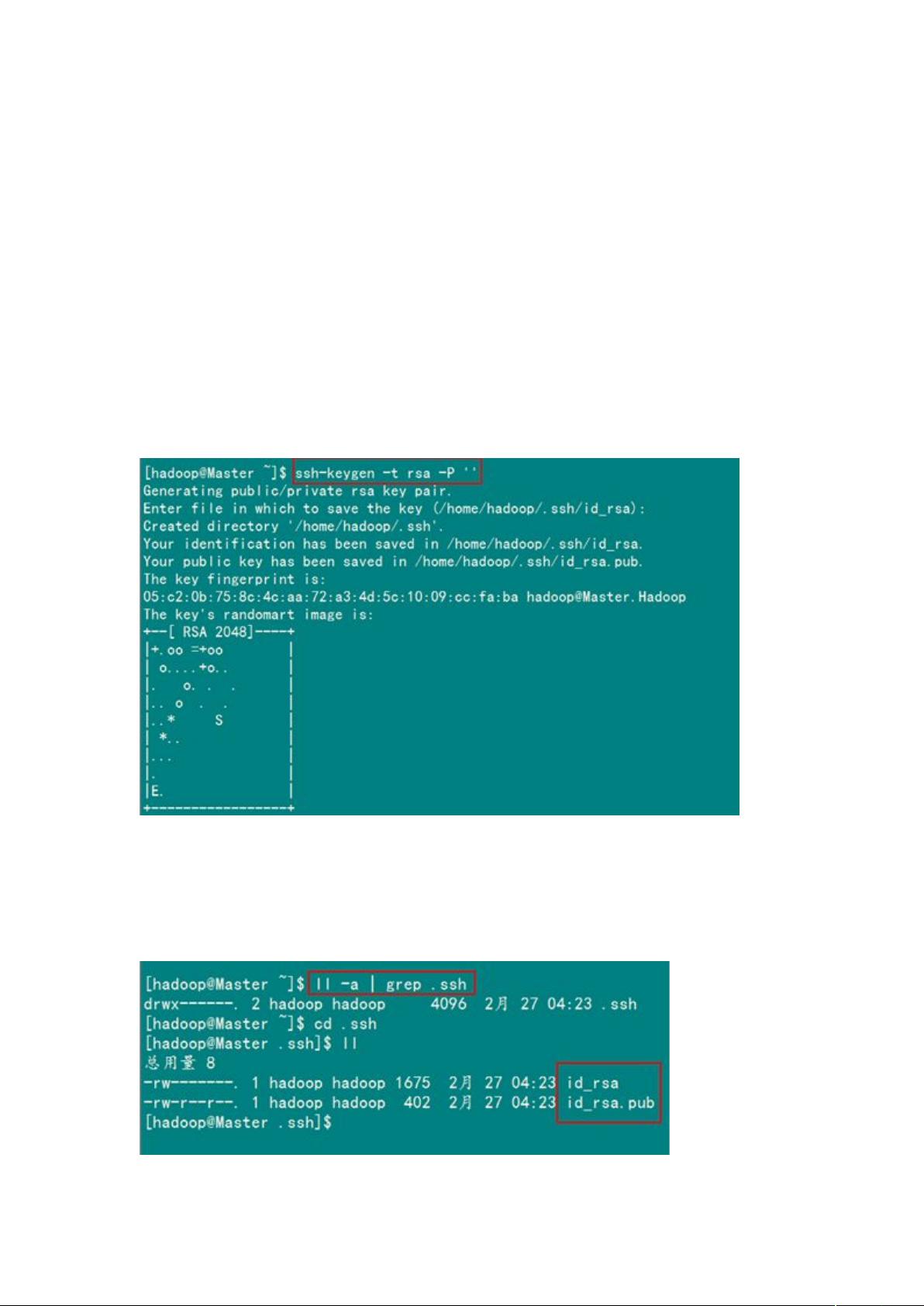
解密数无误之后就允许 进行连接了。这就是一个公钥认证过程,其间不需要用户
手工输入密码。重要过程是将客户端 复制到 上。
2)Master 机器上生成密码对
在 节点上执行以下命令:
: $GG'JJ
这条命是生成其无密码密钥对,询问其保存路径时直接回车采用默认路径。生成的密
钥对:K 和 K+,默认存储在%/home/hadoop/.ssh%目录下。
查看%111%下是否有%+%文件夹,且%+%文件下是否有两个刚生产的
无密码密钥对。

剩余54页未读,继续阅读
2017-10-23 上传
2022-06-22 上传
2023-11-06 上传
点击了解资源详情
2023-09-13 上传
2023-11-05 上传
2023-10-24 上传
2023-09-26 上传
2024-05-29 上传

xxx123xyz
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- landing-page
- test2:测试
- FMake-开源
- [影音娱乐]秀影电影程序VodCMS 6.0.3_showmo.rar
- MOGAN
- 安卓京东2022自动炸年兽v2.0.txt打包整理.zip
- HardwarEngineerRequiredReadingGongLue,单机片c语言源码,c语言项目
- Ma réussite Ulaval-crx插件
- mailer:一个免费的表格数据到电子邮件平台,任何人都可以使用。-开源
- web3:mmmm
- adsds:比萨大学计算机科学系“算法和数据结构(用于数据科学)”课程的页面
- PersonalBudget-Web
- DEC5502_USB,像素鸟c语言源码,c语言项目
- 手机号码归属地查询 PHP版_m_php_工具查询网站开发模板(使用说明+PHP源代码+html).zip
- libLASi-开源
- une banane-crx插件
