鸢尾花数据可视化:探索Speal长度与宽度对种类的影响
需积分: 10 56 浏览量
更新于2024-09-07
收藏 407KB PDF 举报
在本篇代码示例中,主要涉及的是数据可视化,特别是使用Python的几个关键库来探索和分析鸢尾花数据集(Iris dataset)中的关系。该数据集通常包含四个特征:花瓣长度(PetalLengthcm)、花瓣宽度(PetalWidthcm)、花萼长度(SpealLengthcm)和花萼宽度(SpealWidthcm),以及三种不同的鸢尾花品种:Iris-setosa、Iris-versicolor和Iris-virginica。
首先,代码导入了必要的库,如NumPy、Matplotlib、Seaborn和Pandas,这些库在数据处理和可视化中起着关键作用。`sns.set(style="white", color_codes=True)`设置了Seaborn的风格和颜色代码,使得图表更易读。
通过`pd.read_csv()`函数加载数据集,并给特征列指定名称。`iris_data.head()`用于查看数据集的前几行,以便了解数据结构。接着,通过`iris_data["Species"].value_counts()`统计了每种鸢尾花的种类数量,展示了数据集中物种的分布情况。
代码中的核心可视化部分开始于`iris_data.plot(kind="scatter", x="SpealLengthcm", y="SpealWidthcm")`,这是一个散点图,用来直观地观察 SpealLengthcm 和 SpealWidthcm 两个特征之间的关系,初步了解数据点的分布模式。这有助于识别是否存在某种趋势或模式。
进一步的分析,通过`sns.jointplot(x="SpealLengthcm", y="SpealWidthcm", data=iris_data, size=5)`创建了一个联合图,它在同一图中同时显示了两个变量之间的分布和它们各自的直方图,这对于理解两者之间的关系更为全面。
最后,`sns.FacetGrid(iris_data, hue="Species", size=5)`创建了一个分面网格,其中每个面板代表一个鸢尾花种类。`map(plt.scatter, "SpealLengthcm", "SpealWidthcm")`在每个面板上绘制散点图,每个点代表一个样本,颜色表示其对应的鸢尾花种类。`add_legend()`添加了图例,帮助解读不同种类的标记。
这段代码通过一系列数据可视化技术,包括散点图和联合图,深入探究了鸢尾花数据集中不同特征(特别是花萼长度和宽度)与花的种类之间的关系,为后续的数据分析和模型构建提供了基础。通过这样的可视化,研究人员可以更好地理解和解释数据,发现潜在的规律和异常值,为进一步的统计建模或者机器学习算法打下基础。
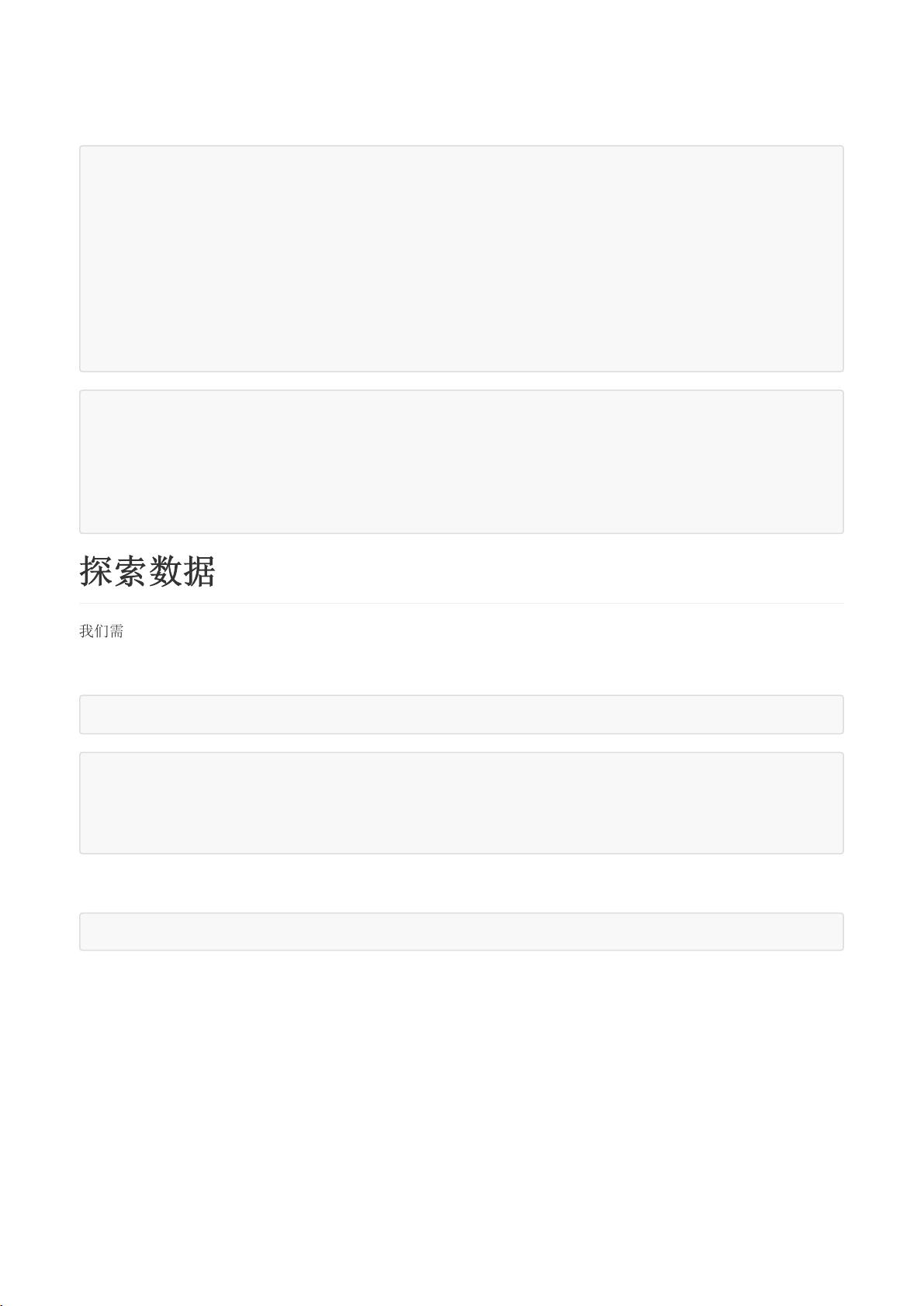
SpealLengthcmSpealWidthcmPetalLengthcmPetalWidthcmSpecies
05.13.51.40.2Iris‐setosa
14.93.01.40.2Iris‐setosa
24.73.21.30.2Iris‐setosa
34.63.11.50.2Iris‐setosa
45.03.61.40.2Iris‐setosa
探
索
数
据
我们需要探索鸢尾花四个数据之间与种类的关系
首先我们来看下种类的分布
Iris‐versicolor50
Iris‐setosa50
Iris‐virginica50
Name:Species,dtype:int64
给的数据三种种类是一样的,我们来看看他Speal长度和宽度的大致分布,画个图
importnumpyasnp
importmatplotlib.pyplotasplt
importseabornassns
importpandasaspd
sns.set(style="white",color_codes=True)
%matplotlibinline
iris_data=pd.read_csv("input/iris.csv",names=
["SpealLengthcm","SpealWidthcm","PetalLengthcm","PetalWidthcm","Species"])
print(iris_data.head())
iris_data["Species"].value_counts()
iris_data.plot(kind="scatter",x="SpealLengthcm",y="SpealWidthcm")
下载后可阅读完整内容,剩余7页未读,立即下载
2018-12-29 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

XGF的碎碎念
- 粉丝: 6
- 资源: 20
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
