Druid入门:架构解析与实时分析
需积分: 49 170 浏览量
更新于2024-07-18
1
收藏 937KB PDF 举报
Druid入门指南深入探讨了一种先进的分布式实时数据分析系统,由美国广告技术公司MetaMarkets在2011年创建并开源。Druid以其出色的性能,尤其是在大规模数据处理和实时性方面的优势,区别于传统的OLAP系统,如关系型数据库。它的设计初衷是专为高效分析而生,适应了大数据时代对实时数据处理的需求。
Druid的名字源于古老的西方神话,象征着知识、智慧和力量。与阿里巴巴的Druid数据库连接池项目不同,此处讨论的是专门用于实时分析的数据存储系统。在大数据分析领域,Druid被广泛应用于处理海量数据,尤其是当企业从基于关系型数据库的传统平台转向开源大数据平台,如Hadoop或Spark,以降低成本并应对实时分析需求时。
在大数据分析的实践过程中,为了提升数据处理的实时性,许多公司采用实时分析工具,这可能包括引入新的软件架构和优化数据流。Druid通过其高级API Tranquility,提供了高效的写入功能,能够实现实时的数据加载和处理,这对于满足秒级查询响应时间至关重要。
整个数据分析的基础架构可以归纳为几个主要类别:
1. Hadoop/Spark的MapReduce分析:这是传统的大规模批处理方法,虽然强大,但在实时性上有所欠缺。
2. 实时数据流处理:通过实时计算框架,如Apache Flink或Apache Kafka,能够提供更快的响应速度。
3. 交互式查询和可视化:Druid作为实时查询引擎,配合BI工具,支持用户进行交互式数据探索和分析。
学习Druid的原生安装和配置,开发者需要掌握如何下载、部署和配置Druid集群,以及如何利用其 Tranquility API进行数据写入。此外,理解Druid的数据模型和查询语法,以及如何优化性能,都是入门阶段的重要内容。对于想要深入理解Druid的人来说,理解其背后的索引机制、分区策略和内存管理机制是关键。
Druid作为一款强大的实时数据分析系统,其价值在于其在大数据环境中的高效性和灵活性,对于企业转型和数据驱动决策具有重要意义。无论是开发人员还是数据分析师,掌握Druid都将有助于提升业务分析能力,推动数据驱动的创新。
多易大数据教育 杨哥答疑 Q:64341393
- 4 -
- 4 -
据的高效摄入与快速查询往往是一对难以两全的指标,因此常常需要在其中做一些取舍与权衡。比如,传统的关系
型数据库如果想在查询时有更快的响应速度,就需要牺牲一些数据写入的性能以完成索引的创建;反之,如果想获
得更快的写入速度,往往要放弃一些索引的创建,就势必在查询的时候付出更高的性能代价。相比之下,Druid 却
能够同时提供性能卓越的数据实时摄入与复杂的查询性能。它是怎么做到的呢?答案是通过其独到的架构设计、基
于 DataSource 与 Segment 的数据结构,以及在许多系统细节上的优秀设计与实现。
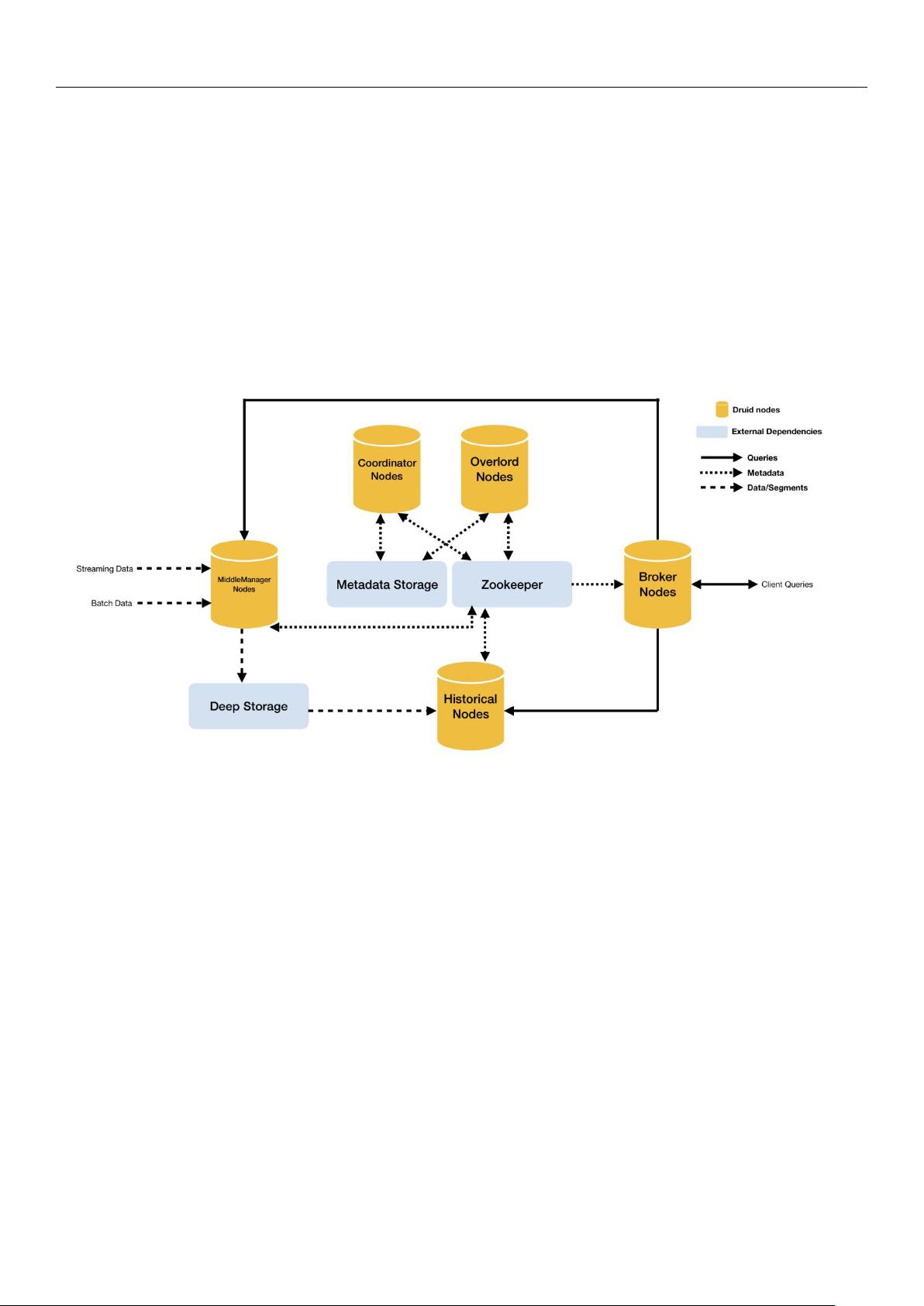
2.1. Druid 架构概览
关于
Druid
架构,我们先通过其总体架构图来做一个概要了解,如下图:
Druid
总体架构图显示出
Druid
自身包含以下
4
类节点。
历史节点(Historical Node):加载已生成好的数据文件,以供数据查询。
实时节点(
Middle Manager Node
):即时摄入实时数据,以及生成
Segment
数据文件。
查询节点(Broker Node):对外提供数据查询服务,并同时从实时节点与历史节点查询数据,合并后返回给调
用方。
协调节点(Coordinator Node):负责历史节点的数据负载均衡,以及通过规则管理数据的生命周期。
统治者(
Overlord Node
)
:
监视
MiddleManager
进程,并且是数据摄入德鲁伊的控制器。他们负责将提取任务
分配给 MiddleManagers 并协调段发布。
同时,集群还包含以下三类外部依赖。
元数据库(
Metastore
):存储
Druid
集群的原数据信息,比如
Segment
的相关信息,一般用
MySQL
或
PostgreSQL
。
分布式协调服务(Coordination):为 Druid 集群提供一致性协调服务的组件,通常为 Zookeeper。
数据文件存储库(
DeepStorage
):存放生成的
Segment
数据文件,并供历史节点下载。对于单节点集群可以
剩余18页未读,继续阅读
2019-02-27 上传
2017-09-19 上传
点击了解资源详情
点击了解资源详情
2023-05-24 上传
2020-08-27 上传
2019-04-14 上传

码动乾坤
- 粉丝: 58
- 资源: 31
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
