吴怀玉2017年SimpleDB批量存储系统述职报告
需积分: 7 128 浏览量
更新于2024-07-20
收藏 1.05MB PPT 举报
"吴怀玉在2017年的答辩PPT,主要涉及他在百度SimpleDB项目中的工作,包括批量存储部分的设计与优化,以及在UPS项目中的经验。"
在此次答辩中,吴怀玉首先介绍了他的个人经历,他曾在2013年4月至2016年3月参与UPS项目,之后转而负责SimpleDB项目,重点是批量存储部分,自2016年3月至今。
SimpleDB是一个为公司提供用户相关数据在线存储和检索服务的系统,具有广泛的应用场景。它分布在6个机房,拥有超过3000台服务器,存储了单副本150+TB的数据,每天处理的查询量(QPS)高达700多亿次,平均时延小于10毫秒,对公司的日均收入有显著影响,尤其是对凤巢系统贡献10%,对网盟贡献50%。
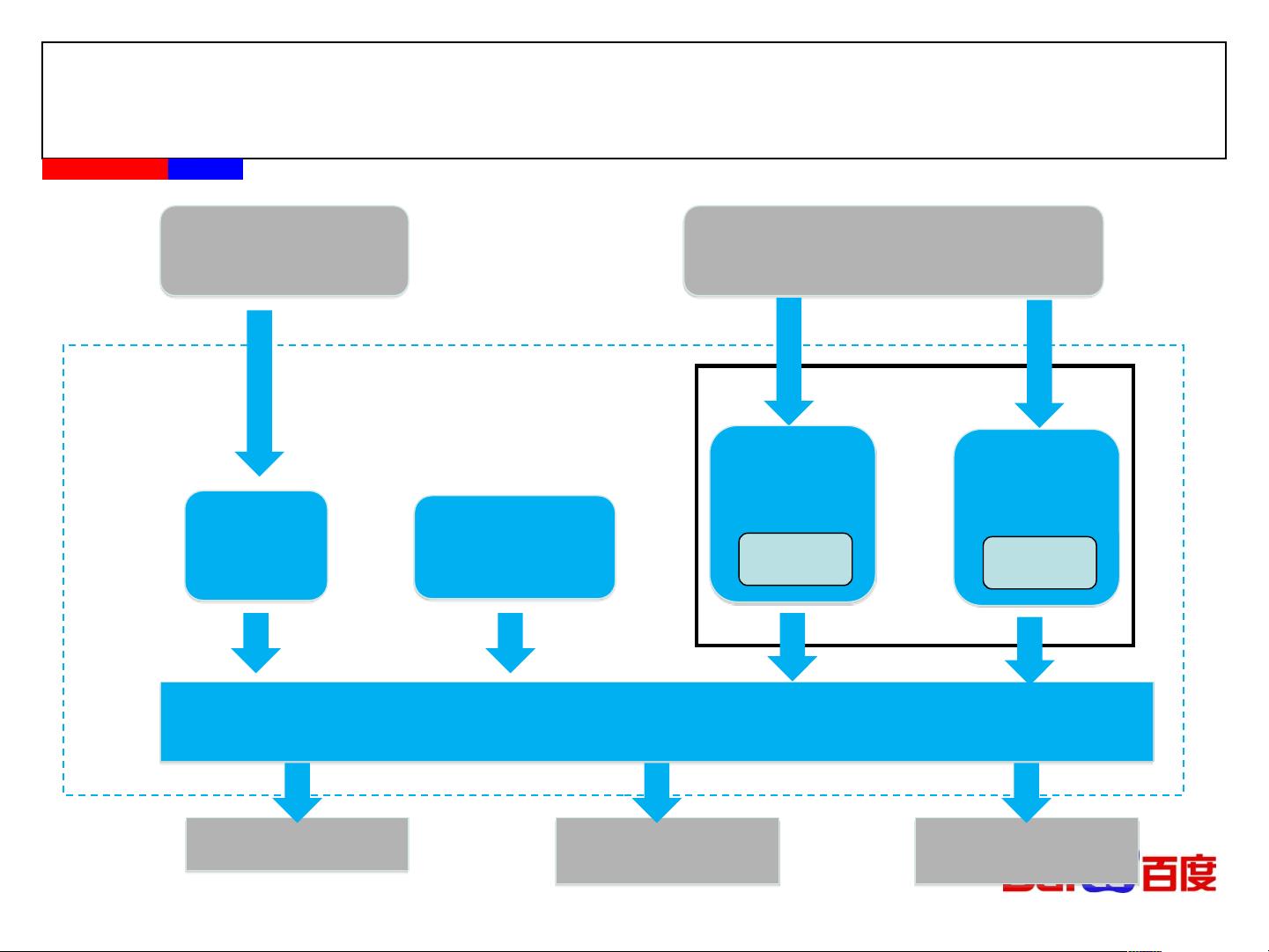
在UPS项目中,吴怀玉提到了实时集群和批量集群的架构。实时集群由Search、导入层、CacheBuffer层、accelerator等组成;批量集群则包含importer、Dstream、Hadoopfile、Zookeeper、Webservice、Mysql、scheduler等多个组件。然而,UPS项目面临的问题主要包括单条数据导入速度慢、Rewrite操作导致的高磁盘IO、Comdb的哈希索引造成的内存瓶颈以及建表不便引发的运维成本高等。
为了解决这些问题,吴怀玉在SimpleDB的批量部分进行了设计优化。新系统的目标是保证时延稳定,同时支持磁盘和内存存储,解决内存瓶颈,提高导入效率,构建高可用且易于运维的集群,并确保安全性。具体设计包括:
1. 单机引擎:可能采用了更高效的导入策略,以提高数据导入速度并降低Rewrite操作对磁盘IO的影响。
2. 集群管理:通过优化集群架构,例如引入Zookeeper进行协调,提升整个系统的高可用性。
3. 迁移工作:可能涉及数据迁移策略的改进,以减小对业务的影响。
在实际效果方面,吴怀玉可能详细阐述了优化后系统的性能提升,包括导入速率、内存利用率、磁盘IO和整体查询响应时间的改善。此外,他还可能讨论了后续的工作计划,如进一步的性能调优、新的功能添加或系统扩展等。
这篇PPT展示了吴怀玉在大规模分布式数据库系统中的工作经验,特别是针对SimpleDB批量存储部分的优化设计,以及如何解决在UPS项目中遇到的挑战。这些内容对于理解大型互联网公司的数据存储和处理机制具有重要价值。

1. Simpledb 背景 -UPS- 问题
1. 单条数据导入,导致:
a. 导入速度慢
b. Rewrite 导致磁盘 IO 高,单机 qps 低
2. Comdb hash 索引方式,导致:
a. 内存瓶颈,磁盘利用率不高
3. 建表不便,导致:
a. 业务间互相影响,运维成本高
剩余32页未读,继续阅读
186 浏览量
2022-07-01 上传
570 浏览量
2020-02-19 上传
2020-02-19 上传
2022-05-27 上传

wuhuaiyu
- 粉丝: 13
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
