TVP5150/5151数字视频解码器手册:设计与应用指南
TVP5150和TVP5151是来自德州仪器半导体技术(上海)有限公司的数字视频解码器,它们的特点在于其低功耗、小型化设计和易用性。TVP5150支持PAL、NTSC和SECAM等多种视频制式,能解码并输出8-bit ITU-R BT.656数据,同时内置VBI处理器,能够解析垂直空白间隔中的teletext和closed caption信息。该器件可以通过标准I2C接口进行微控制器(MCU)控制,调整如色调、对比度、亮度、饱和度和锐度等参数。
TVP5151作为TVP5150AM1的升级版,主要改进在于将最新的补丁集成到内部program ROM,以及扩展了内部RAM空间。硬件上的区别在于TVP5151采用单个27MHz的时钟,与TVP5150AM1完全兼容,但在设计上更倾向于使用TVP5151。
在硬件设计方面,提供了详细的参考原理图和gerber文件,以供设计者参考。重要的是确保时钟电路的准确性,推荐使用频率为14.31818MHz,误差保持在50ppm以内,并根据晶体的负载电容选择合适的C1和C2,通常Cstray在3-8pF范围内。此外,上电时序也需注意,应先上1.8v电压,随后上3.3v电压,且需间隔100ms后再进行系统复位。视频输入管脚的增益设置应在75欧姆匹配电阻下,信号的最大峰峰值不超过1.24v。
TVP5150和TVP5151的设计目标是简化工程师的工作流程,提供稳定且高性能的视频解码解决方案,适用于对功耗敏感的应用场合,如便携设备或嵌入式系统。在实际使用过程中,遵循手册提供的设计指南和注意事项至关重要,以确保产品的稳定性和性能。
ZHCA121
TVP5150xxx /TVP5151
使用手册
5
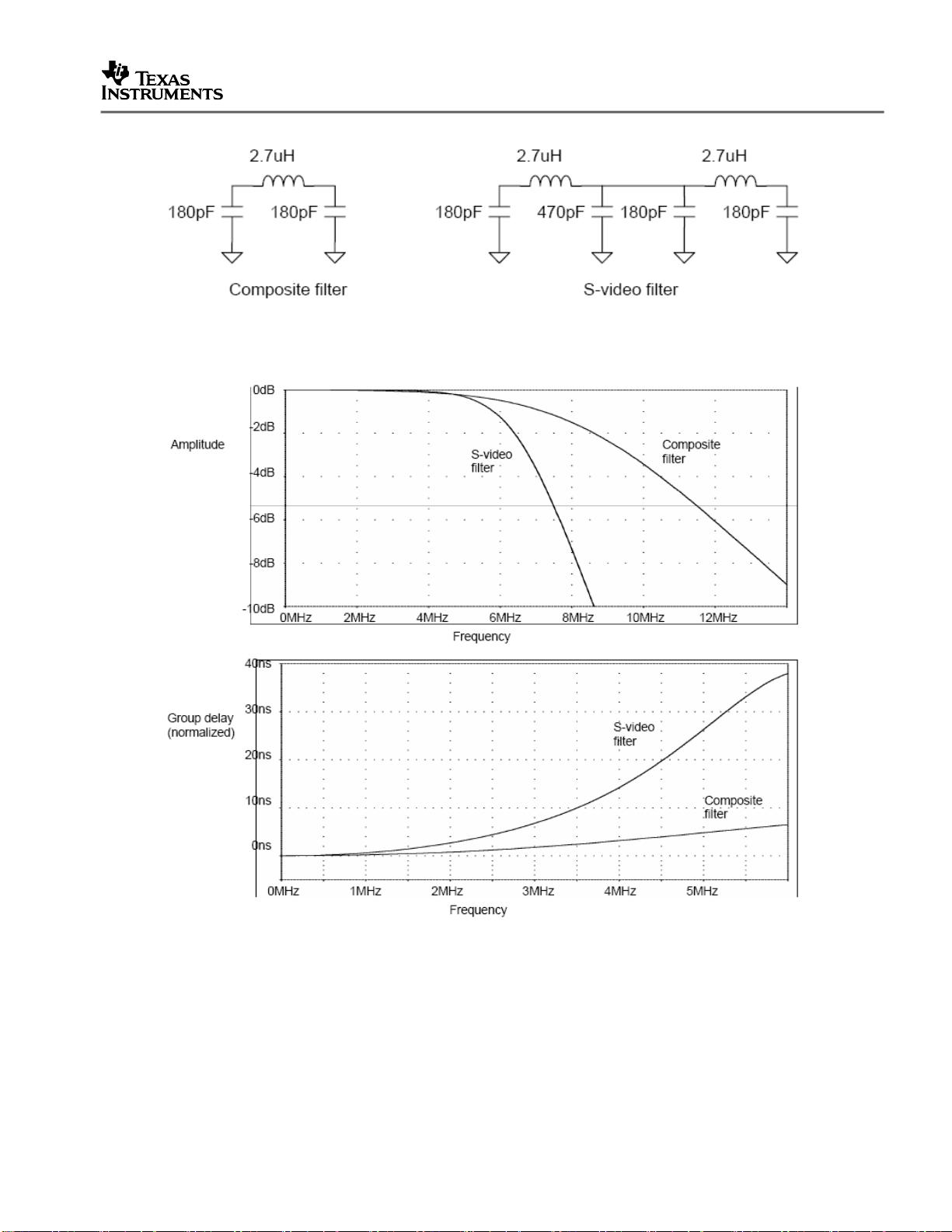
Figure 4.
Figure 5. 幅频特性,频响特性
4. TVP5150IBIS 模型
请看链接。
剩余24页未读,继续阅读
相关推荐




dychenaaaa
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 盖茨比入门项目教程:搭建静态网站的新体验
- 全面技术领域源码整合:一站式学习与开发工具包
- C++图形编程系列教程:图像处理与显示
- 使用百度地图实现Android定时定位功能
- Node.js基础教程:实现音乐播放与上传功能
- 掌握Swift动画库:TMgradientLayer实现渐变色动画
- 解决无法进入安全模式的简易方法
- XR空间应用程序列表追踪器:追踪增强与虚拟现实应用
- Ember Inflector库:实现单词变形与Rails兼容性
- EasyUI Java实现CRUD操作与数据库交互教程
- Ruby gem_home:高效管理RubyGems环境的工具
- MyBatis数据库表自动生成工具使用示例
- K2VR Installer GUI:独特的虚拟现实安装程序设计
- 深蓝色商务UI设计项目资源全集成技术源码包
- 掌握嵌入式开发必备:深入研究readline-5.2
- lib.reviews: 打造免费开源的内容审核平台
