探究ChatGPT生成文本的工作原理:合理延续文本生成机制的解析
 已收录资源合集
已收录资源合集
需积分: 0 142 浏览量
更新于2024-03-11
6
收藏 13.21MB PDF 举报
&mid=2247537023&idx=1&sn=2b3f6e72ab7ac15a6ab501a5c52f5c84&chksm=ebbd9e6edcc01778e84cf4e032ffe59beb715a79b29e2ff0a10d3b07d8307e81a21aee36c6a5&token=2095662760#rd)不是在扫描实际的网页和书籍,而是在扫描已被人们提供的大量数据(即已经被人们看到了、已活在网上或已经在出版物上的文本)。
ChatGPT 的目标看似简单,即使也非常严重。它试图成为一个极其通用的、巨大的、足够关于“人类的语言和知识”的编码,然后在需要时加工这些东西来回答问题,生成代码,讲故事或进行其他事情。
这意味着训练 ChatGPT 的数据应尽可能多地代表全人类的思考和知识结构 —— 这并不仅仅包括英语、西班牙语和汉语用户的观点,还要包括所有那些因为 ChatGPT 需要处理类似这样的文本而不得不面对巨大压力的用户的文本存在。
为了做到这一点,OpenAI 从数十亿甚至万亿以上的文字片段中收集了文本,然后,用这些文本来训练 ChatGPT。
整个过程的基本思路是:建立一个模型,在看到某些文本之后就能够在给定某些句子之后继续这些内容。从戏剧片段到法律文件再到新闻报道,这个模型会简单地跟着第一个句子、段落或者整本书的思路走下去。这是自动语言建模 (LM) 的目标,基本思想是“如果你能很好地预测下一个词,那么你就肯定已经学到了这些数据中有关语言和世界的巨大知识量”,ChatGPT 就是这一过程的结果。
理解了这一基本理念,我们就要来探讨一下这种训练有素的模型是如何被设计出来的,以及为什么它能够表现得如此出色。
首先,ChatGPT 是一个大型神经网络。从技术上讲,它是一个变种的 Transformer 模型,它有很多层,并且能够在训练和使用时自动地处理和组织很多文本。
在技术水平上,理解 ChatGPT 的运作原理需要对神经网络架构有一定的了解。从表面上看,ChatGPT 看起来就像一个黑盒子,你把文本输入进去,然后从中获得一些文本输出,而在整个过程中神经网络到底发生了什么却是不透明的。
在 ChatGPT 的训练过程中,OpenAI 在海量的文本数据上反复迭代,不断调整神经网络中的权重,以使得模型能够更好地预测出下一个词。这样,它就能学到这些文本中的一些规律、结构和知识。这一过程被称为“监督学习”,因为模型是在“监督”下进行训练的 —— 即给定了输入和期望的输出。
然而,ChatGPT 并不只是一个简单的预测模型。随着训练的进行,它逐渐学会了一系列更加复杂的能力,它能够理解语法、推断逻辑、生成合理的文本甚至进行不同领域的知识融合。这些都是因为它被训练成了一个非常大的和非常通用的模型,它能够很好地反映自然语言的表达和人类的常识。
在这一点上,我们需要强调一下:ChatGPT 并不是一个意识体,它不具有真正的理解、思考和意识。它只是一个能够通过大量文本数据来模拟人类知识和语言表达的工具。它产生的文本表面上看起来可能是合理的,但是这并不意味着它确实理解了这些文本的含义。
ChatGPT 能够自动生成一些读起来表面上甚至像人写的文字的东西,这非常了不起,而且出乎意料。但它是如何做到的?为什么它能发挥作用?在这篇文章中,我们从ChatGPT的工作原理出发,探讨了它能很好地生成有意义的文本的原因。我们首先介绍了ChatGPT试图对文本进行“合理的延续”的基本原理,然后讨论了它训练所使用的大量数据和监督学习的过程。最后,我们强调了ChatGPT只是一个模拟人类知识和语言表达的工具,并非真正具有理解和意识。通过这些内容的介绍,我们希望读者能够更好地理解ChatGPT的工作原理,并对它的生成能力有一个清晰的认识。
2023/5/16 17:59
万字长⽂ | ChatGPT的⼯作原理
https://mp.weixin.qq.com/s?__biz=MzI4MTIxNDcxOQ==&tempkey=MTIxN193ZVBEU1Q4ZTVpN0pyOHBQTEczS184TGl1RW1tLXFYbE9aZkRhTm9…
12/72
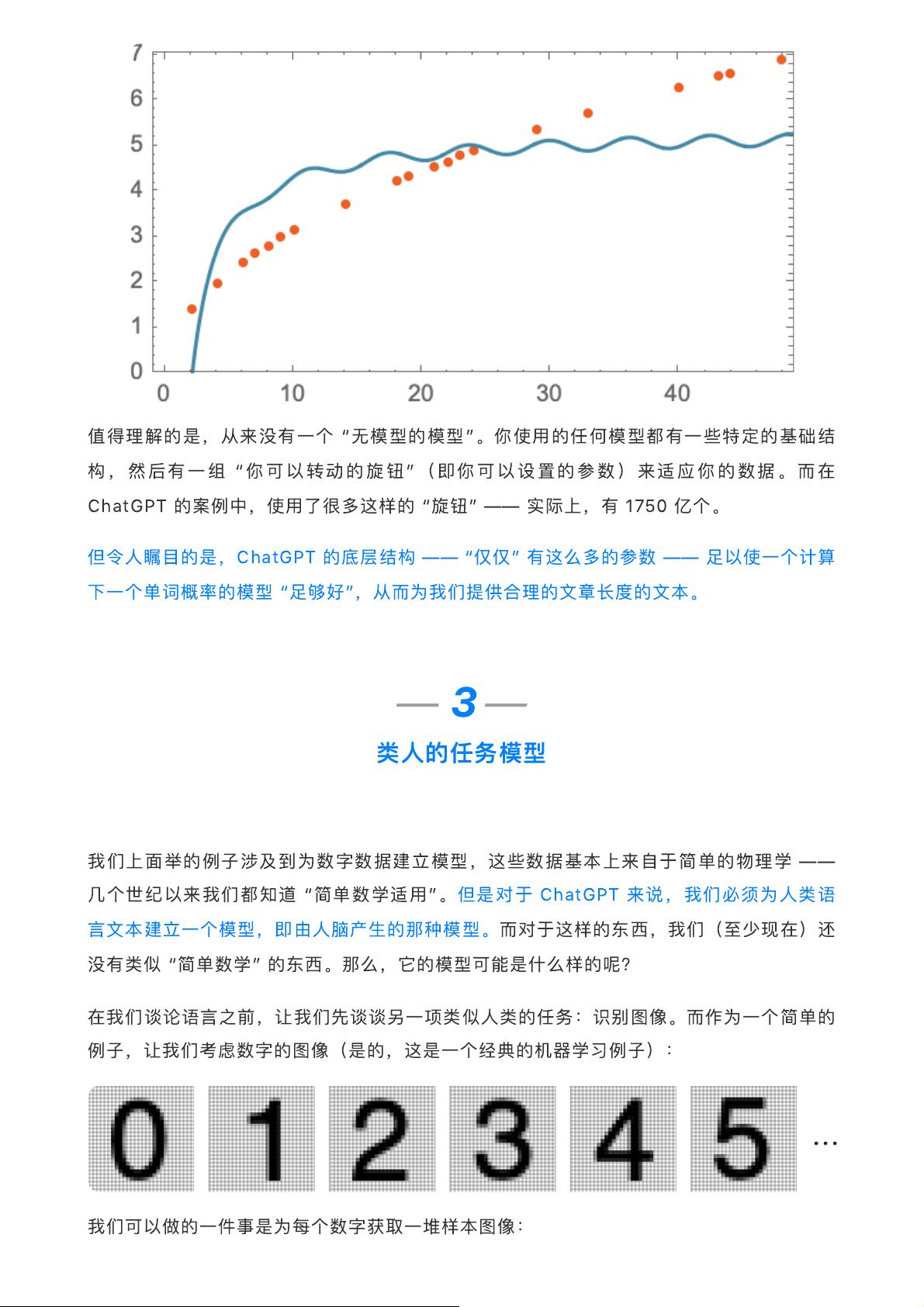
值
得
理
解
的
是
,
从
来
没
有
⼀个
“
⽆
模
型
的
模
型
”
。
你使
⽤
的
任何
模
型
都
有
⼀
些
特
定
的
基
础
结
构
,
然
后
有
⼀
组
“
你
可
以
转
动
的
旋
钮
”
(
即
你
可
以
设
置
的
参
数
)
来
适
应
你
的
数据
。
⽽
在
C
ha
t
GP
T
的
案
例中
,
使
⽤
了
很
多
这
样
的
“
旋
钮
”
——
实
际
上,
有
1750
亿
个
。
但令⼈
瞩⽬的
是
,
C
ha
t
GP
T
的
底
层
结
构
——
“
仅仅
”
有
这
么
多
的
参
数
——
⾜
以使
⼀个
计
算
下⼀个
单
词
概
率
的
模
型
“
⾜
够好
”
,
从
⽽
为
我
们
提
供
合
理
的
⽂
章
⻓
度
的
⽂
本
。
—
3
—
类
⼈
的
任
务
模
型
我
们
上
⾯
举
的
例
⼦
涉
及
到
为
数
字
数据
建
⽴
模
型
,
这
些
数据
基
本
上
来
⾃
于
简
单
的
物
理
学
——
⼏
个世
纪
以
来
我
们
都
知
道
“
简
单
数
学
适
⽤
”
。
但
是
对
于
C
ha
t
GP
T
来
说
,
我
们
必
须
为⼈
类
语
⾔
⽂
本
建
⽴
⼀个
模
型
,
即
由
⼈
脑
产
⽣
的
那
种
模
型
。
⽽
对
于
这
样
的
东
⻄
,
我
们
(
⾄
少
现
在
)
还
没
有
类
似
“
简
单
数
学
”
的
东
⻄
。
那
么
,
它
的
模
型
可
能
是
什么
样
的
呢
?
在
我
们
谈
论语⾔
之
前
,
让
我
们
先
谈谈
另
⼀
项
类
似⼈
类
的
任
务
:
识
别
图
像
。
⽽
作为
⼀个
简
单
的
例
⼦
,
让
我
们
考
虑
数
字
的
图
像
(
是
的
,
这
是
⼀个
经
典
的
机
器
学
习例
⼦
):
我
们
可
以
做
的
⼀
件事
是
为
每
个
数
字
获
取
⼀
堆
样本
图
像
:



剩余71页未读,继续阅读
2023-07-03 上传
2023-04-20 上传
2023-04-23 上传
2023-05-19 上传
2022-07-09 上传
2021-06-27 上传

程序员白城
- 粉丝: 173
- 资源: 88
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
