苹果发布30B参数多模态大模型MM1:架构与预训练洞察
124 浏览量
更新于2024-06-15
收藏 17.93MB PDF 举报
本文档探讨了苹果公司在多模态大型语言模型(Multimodal Large Language Models, MLLMs)领域的最新进展,以论文《MM1:Methods, Analysis & Insights from Multimodal LLM Pre-training》的形式公开。随着多模态生成技术在人工智能(AI)市场中的火热发展,尤其是OpenAI的Sora项目,苹果公司决定加入这一竞争,推出了一个拥有30亿参数的高性能多模态大模型系列。
研究的核心关注点在于构建高效且表现优秀的多模态模型,这涉及到模型架构的关键组成部分和数据选择的重要性。论文作者团队,包括多位核心和资深作者,对图像编码器、视觉语言连接器以及不同类型的预训练数据进行了细致而全面的分析和比较。他们发现,对于大规模多模态预训练,混合使用图像描述数据、交错的图像-文本数据和纯文本数据是至关重要的,这对于达到当前最佳性能状态至关重要。
具体来说,他们强调了以下设计要点:
1. **图像编码器**:通过深入研究,团队发现优化的图像编码器对于模型理解和整合不同模态信息至关重要,它影响了模型对视觉信息的理解和处理能力。
2. **视觉语言连接器**:连接器的设计决定了模型如何在文本和视觉元素之间建立联系,一个高效的连接器能够促进跨模态知识的融合。
3. **数据多样性**:混合数据策略有助于模型学习更全面的语言模式和上下文理解,避免了单一数据类型可能导致的偏见或局限性。
4. **文本与图像的交互**:交替的图像-文本和文本-图像数据增强,使得模型能够在处理单独模态时也能理解它们之间的关系,从而提升整体性能。
5. **预训练数据的质量和量**:高质量的图像-文本配对和多样化的数据源对于模型的泛化能力和迁移学习效果有着显著影响。
6. **模型规模**:30亿参数的大规模模型在多模态任务上展现出强大的潜能,但也带来了更大的计算挑战和对数据的要求。
通过这些分析和实证研究,苹果展示了其在多模态大模型开发上的方法论和技术洞察,这不仅揭示了构建高效多模态模型的策略,也为其他研究者和开发者提供了有价值的参考。未来,我们可以期待苹果在这一领域继续探索,推动多模态技术的创新和发展。

8 B. McKinzie et al.
models. After instruction tuning, all three architectures achieve very similar re-
sults at the 336px and 114 token setting. (See Appendix Figure 10 for fine-tuning
results.)
3.3 Pre-training Data Ablation
Large-scale and task-appropriate data is of paramount importance in training
performant models. Typically, models are trained in two stages, pre-training and
instruction tuning. In the former stage web-scale data is used while in the latter
stage task-specific curated data is utilized. In the following, we focus on the
pre-training stage and elaborate our data choices (see Figure 3, right).
Data Type Sources Size
Captioned Images
CC3M [101], CC12M [13], HQIPT-204M [94],
2B image-text pairs
COYO [11], Web Image-Text-1B (Internal)
Captioned Images (Synthetic) VeCap [56] 300M image-text pairs
Interleaved Image-Text OBELICS [58], Web Interleaved (Internal) 600M documents
Text-only
Webpages, Code, Social media,
2T tokens
Books, Encyclopedic, Math
Table 2: List of datasets for pre-training multimodal large language models.
Two types of data are commonly used to train MLLMs: captioning data
consisting of images with paired text descriptions; and interleaved image-text
documents from the web (see Appendix A.1 for details). Note that captioning
data tends to contain relatively short text with high relevance to the image.
On the contrary, interleaved data has substantially longer and more diverse text
with less relevance, on average, to the surrounding images. Finally, we include
text-only data to help preserve the language understanding capabilities of the
underlying LLM. The full list of datasets is summarized in Table 2.
We use the same model setup for ablations described in Section 3.1, with the
only exception that we train 200k steps here to fully leverage the large-scale data
training. We also incorporate a set of commonly employed text tasks, referred
to as TextCore
1
, as part of the evaluation to better assess the effects of data
mixture. These lead to the following lessons:
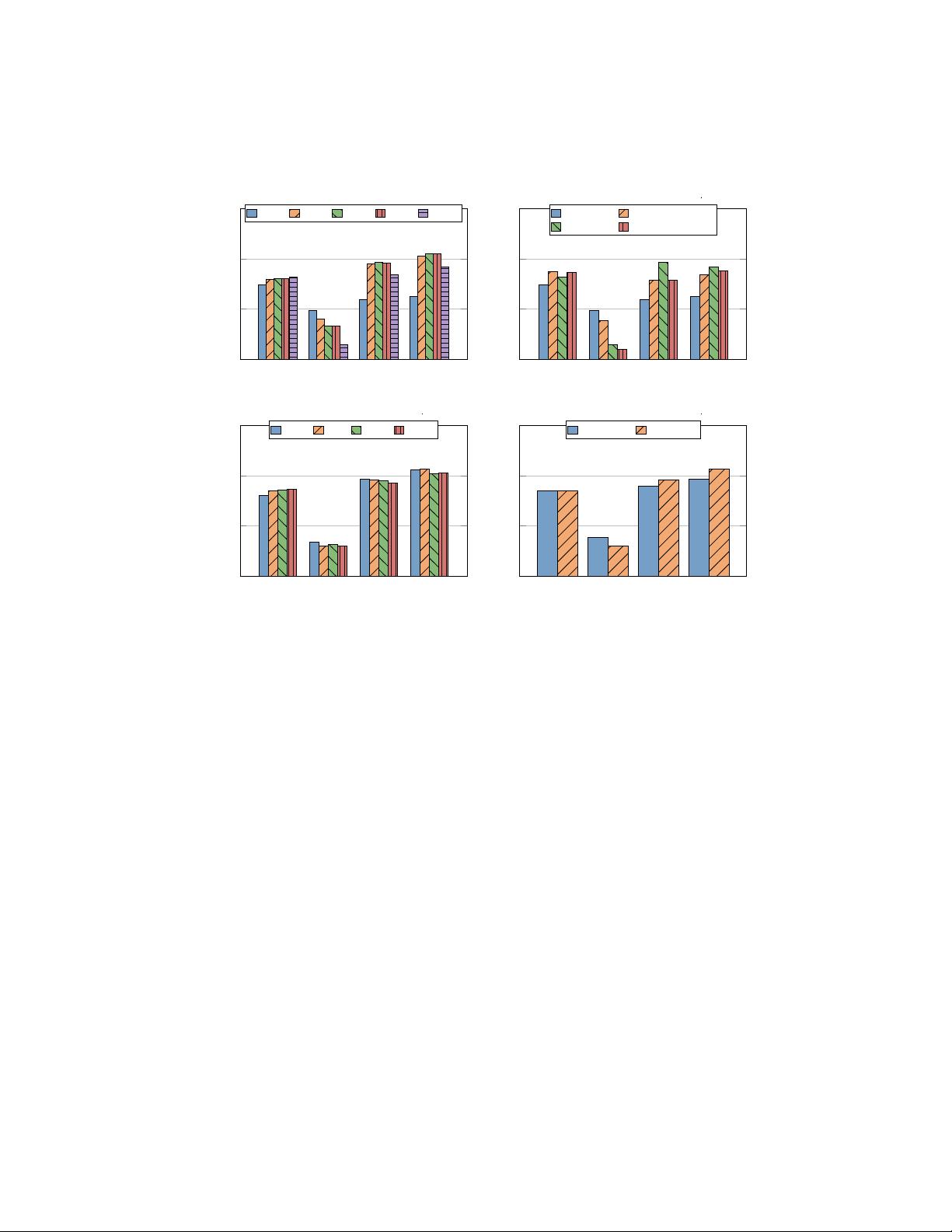
Data lesson 1: interleaved data is instrumental for few-shot and text-
only performance, while captioning data lifts zero-shot performance.
In Figure 5a, we present results across different mixes of interleaved and cap-
tioned data. Zero-shot performance increases consistently, from 25.8% to 39.3%,
as we increase the amount of captioned data. At the same time, however, for
4- and 8-shot performance, having at least 50% of the data being interleaved is
crucial to maintain over 61% for 8-shot or 58% for 4-shot. Without it, perfor-
mance drops drastically to 45% and 43.7%, respectively. Since interleaved data
naturally contains multiple images and accompanying text which are often inter-
related, such data is inherently similar to few-shot test inputs, which aligns well
1
TextCore tasks include ARC [22], PIQA [7], LAMBADA [89], WinoGrande [97],
HellaSWAG [128], SciQ [118], TriviaQA [50], and WebQS [6].
剩余40页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-03-16 上传
2021-02-16 上传
2021-03-25 上传
2021-06-26 上传
2022-09-24 上传
2021-05-30 上传

灿烂李
- 粉丝: 392
- 资源: 115
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
