基于骨骼数据的人体动作识别时空注意力模型
148 浏览量
更新于2024-08-29
收藏 880KB PDF 举报
本文主要探讨了"一种端到端的时空注意力模型在骨骼数据的人体动作识别中的应用"。随着计算机视觉领域的快速发展,人类动作识别是其中一项关键任务,其目标是从动态的身体姿态数据中提取出区分度高的空间和时间特征,以便准确理解和描述各种动作。传统的深度学习方法,如递归神经网络(Recurrent Neural Networks, RNNs)特别是长短期记忆网络(Long Short-Term Memory, LSTM),在处理序列数据时表现出了显著的优势。
作者们提出了一种新颖的端到端时空注意力模型,该模型构建在LSTM基础之上。这个模型的核心创新在于它能够智能地关注输入序列中每个时间步的关键关节。通过自注意力机制,模型学会了在每一帧中选择最具代表性的关节,并对不同帧的输出给予不同的注意力权重。这种设计有助于捕捉动作的动态变化,因为模型能够专注于动作的重要阶段,而不仅仅是简单地平均或忽视某些部分。
此外,为了提高模型的训练效率和性能,文章还可能讨论了如何优化注意力机制的学习过程,以及如何与骨骼数据的结构和动作的内在规律相结合。可能采用了正则化策略、损失函数调整或者集成其他先验知识来增强模型的泛化能力。在实验部分,作者可能会展示模型在公开的人体动作识别数据集上的表现,如UCF-101、H3.6M等,对比其他前沿方法,证明了所提模型在精度和效率上的优势。
这篇研究论文提供了一种创新的方法来提升基于骨骼数据的人体动作识别的性能,强调了时空注意力机制在指导模型关注动作关键特征和序列信息处理中的重要作用。它不仅展示了技术上的突破,也展示了在实际应用场景中的可行性,对于深化理解动作识别问题以及推动相关技术的发展具有重要意义。
An End-to-End Spatio-Temporal Attention Model for Human Action Recognition
from Skeleton Data
Sijie Song
1
, Cuiling Lan
2
∗
, Junliang Xing
3
, Wenjun Zeng
2
, Jiaying Liu
1
∗
1
Institute of Computer Science and Technology, Peking University, Beijing, China
2
Microsoft Research Asia, Beijing, China
3
Institute of Automation, Chinese Academy of Sciences, Beijing, China
{ssj940920, liujiaying}@pku.edu.cn, {culan,wezeng}@microsoft.com, jlxing@nlpr.ia.ac.cn
Abstract
Human action recognition is an important task in computer
vision. Extracting discriminative spatial and temporal fea-
tures to model the spatial and temporal evolutions of dif-
ferent actions plays a key role in accomplishing this task.
In this work, we propose an end-to-end spatial and tempo-
ral attention model for human action recognition from skele-
ton data. We build our model on top of the Recurrent Neural
Networks (RNNs) with Long Short-Term Memory (LSTM),
which learns to selectively focus on discriminative joints of
skeleton within each frame of the inputs and pays different
levels of attention to the outputs of different frames. Further-
more, to ensure effective training of the network, we propose
a regularized cross-entropy loss to drive the model learning
process and develop a joint training strategy accordingly. Ex-
perimental results demonstrate the effectiveness of the pro-
posed model, both on the small human action recognition
dataset of SBU and the currently largest NTU dataset.
1 Introduction
Recognition of human action is a fundamental yet challeng-
ing task in computer vision. It facilitates many applications
such as intelligent video surveillance, human-computer in-
teraction, video summary and understanding (Poppe 2010;
Weinland, Ronfard, and Boyerc 2011). The key to the suc-
cess of this task is how to extract discriminative spatial tem-
poral features to effectively model the spatial and temporal
evolutions of different actions.
One general approach focuses on the recognition from
RGB videos (Weinland, Ronfard, and Boyerc 2011). Since
each frame is a capture of the highly articulated human in
a two-dimensional space, it loses some information of the
three-dimensional (3D) space and then loses the flexibil-
ity of achieving human location and scale invariance. The
other general approach leverages the high level information
of skeleton data, which represents a person by the 3D co-
ordinate positions of key joints (i.e., head, neck,· · · , foot).
Such representation is robust to variations of locations and
∗
Corresponding author. This work was done at Microsoft Re-
search Asia. This work was supported by National Natural Sci-
ence Foundation of China under contract No. 61472011 and No.
61303178.
Copyright
c
2017, Association for the Advancement of Artificial
Intelligence (www.aaai.org). All rights reserved.
… ……
Preparation Climax End
Time
……
…
… …
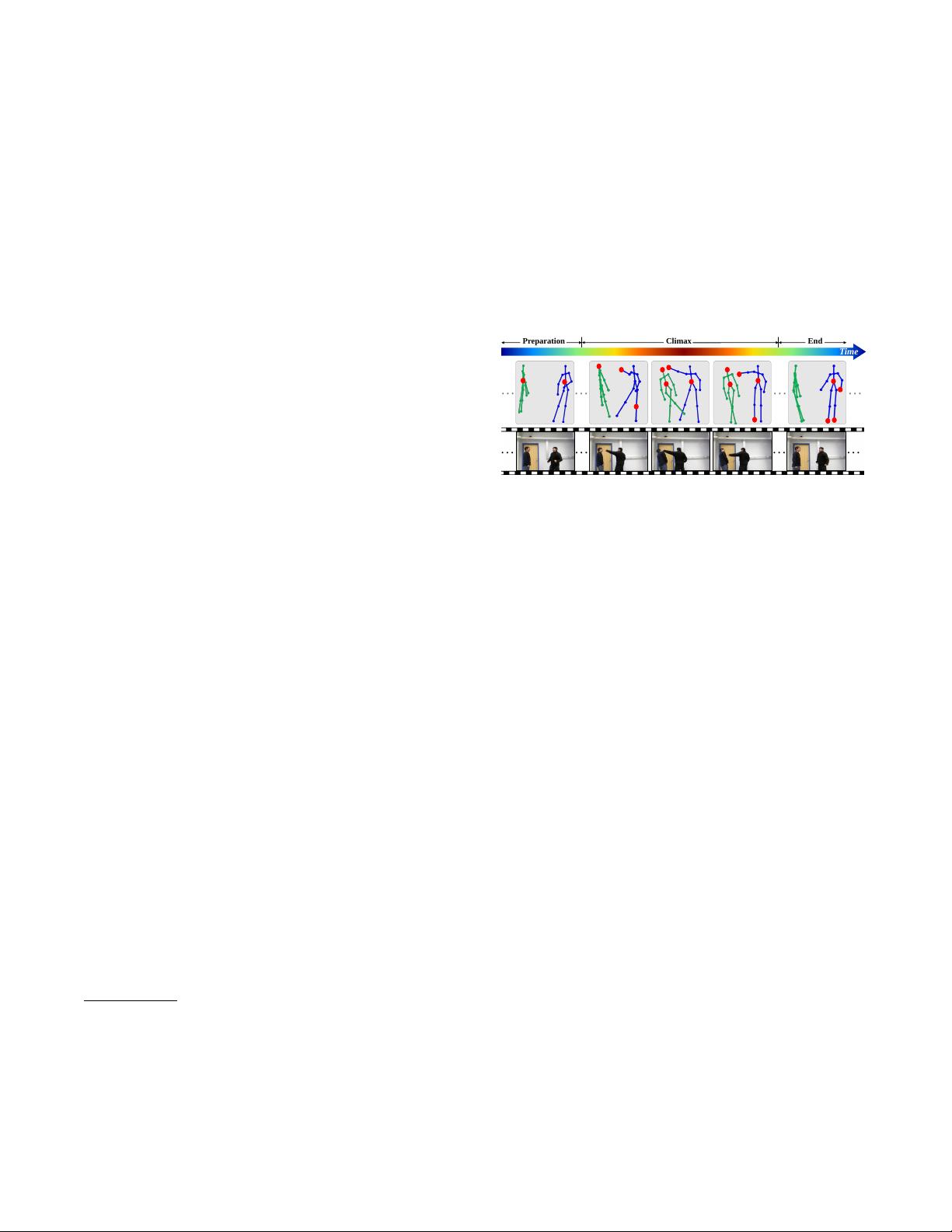
Figure 1: Illustration of the procedure for an action “punch-
ing”. An action may experience different stages, and involve
different discriminative subsets of joints (as the red circles).
viewpoints. Without combining RGB information, there is a
lack of appearance information. Fortunately, biological ob-
servations from the early seminal work of Johansson suggest
that the positions of a small number of joints can effectively
represent human behavior even without appearance informa-
tion (Johansson 1973). Skeleton-based human representa-
tion has attracted increasing attention for recognizing human
actions thanks to its high level representation and robustness
to variations of locations and appearances (Han et al. 2016).
The prevalence of cost-effective depth cameras such as Mi-
crosoft Kinect (Zhang 2012) and the advance of a powerful
human pose estimation technique from depth (Shotton et al.
2011) make 3D skeleton data easily accessible. This boosts
research on skeleton-based human action recognition. In this
work, we focus on recognition from skeleton data.
Fig. 1 shows an example of a series of skeleton frames
(and RGB images) for the action “punching”. Each human
body is represented by key joints in terms of coordinate po-
sitions in the 3D space. The articulated configurations of
joints constitute various postures and a series of postures in
a certain time order identifies an action. With the skeleton
as an explicit high level representation of human pose, many
works design algorithms taking the positions of joints as in-
puts. There are two basic components in these works. One
is the design and mining of discriminative features from the
skeleton, such as histograms of 3D joint locations (HOJ3D)
(Xia, Chen, and Aggarwal 2012), pairwise relative posi-
tion features (Wang, Liu, and Yuan 2012), relative 3D ge-
ometry features (Vemulapalli, Arrate, and Chellappa 2016).
The other is the modeling of temporal dynamics, such as
Hidden Markov Model (Xia, Chen, and Aggarwal 2012),
Conditional Random Fields (Sminchisescu, Kanaujia, and
arXiv:1611.06067v1 [cs.CV] 18 Nov 2016
下载后可阅读完整内容,剩余6页未读,立即下载
2022-02-23 上传
2022-01-24 上传
2023-10-10 上传
2023-07-10 上传
2023-06-10 上传
2023-06-10 上传
2023-06-10 上传
2023-06-10 上传
2023-06-10 上传
2023-06-10 上传

weixin_38593723
- 粉丝: 5
- 资源: 919
 我的内容管理
展开
我的内容管理
展开







最新资源
- OptiX传输试题与SDH基础知识
- C++Builder函数详解与应用
- Linux shell (bash) 文件与字符串比较运算符详解
- Adam Gawne-Cain解读英文版WKT格式与常见投影标准
- dos命令详解:基础操作与网络测试必备
- Windows 蓝屏代码解析与处理指南
- PSoC CY8C24533在电动自行车控制器设计中的应用
- PHP整合FCKeditor网页编辑器教程
- Java Swing计算器源码示例:初学者入门教程
- Eclipse平台上的可视化开发:使用VEP与SWT
- 软件工程CASE工具实践指南
- AIX LVM详解:网络存储架构与管理
- 递归算法解析:文件系统、XML与树图
- 使用Struts2与MySQL构建Web登录验证教程
- PHP5 CLI模式:用PHP编写Shell脚本教程
- MyBatis与Spring完美整合:1.0.0-RC3详解
