SQL Server分页优化:ROW_NUMBER() vs UNBOUNDED PRECEDING
154 浏览量
更新于2024-08-28
收藏 97KB PDF 举报
"本文探讨了在SQL Server中两种不同的分页编号方法——ROW_NUMBER()与使用SUM(1) OVER(ORDER BY ... ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)——并对比了它们的性能。作者通过实验发现,在大数据量时,ROW_NUMBER()在分页查询上的表现更优,可能是因为微软对ROW_NUMBER()进行了优化,存在缓存机制,从而提高了读取效率。"
在SQL Server中,处理大量数据时,分页查询是非常常见的操作,有效地实现分页可以提高查询性能并减少不必要的资源消耗。本文介绍了两种不同的分页方法,并通过实验分析了它们的性能差异。
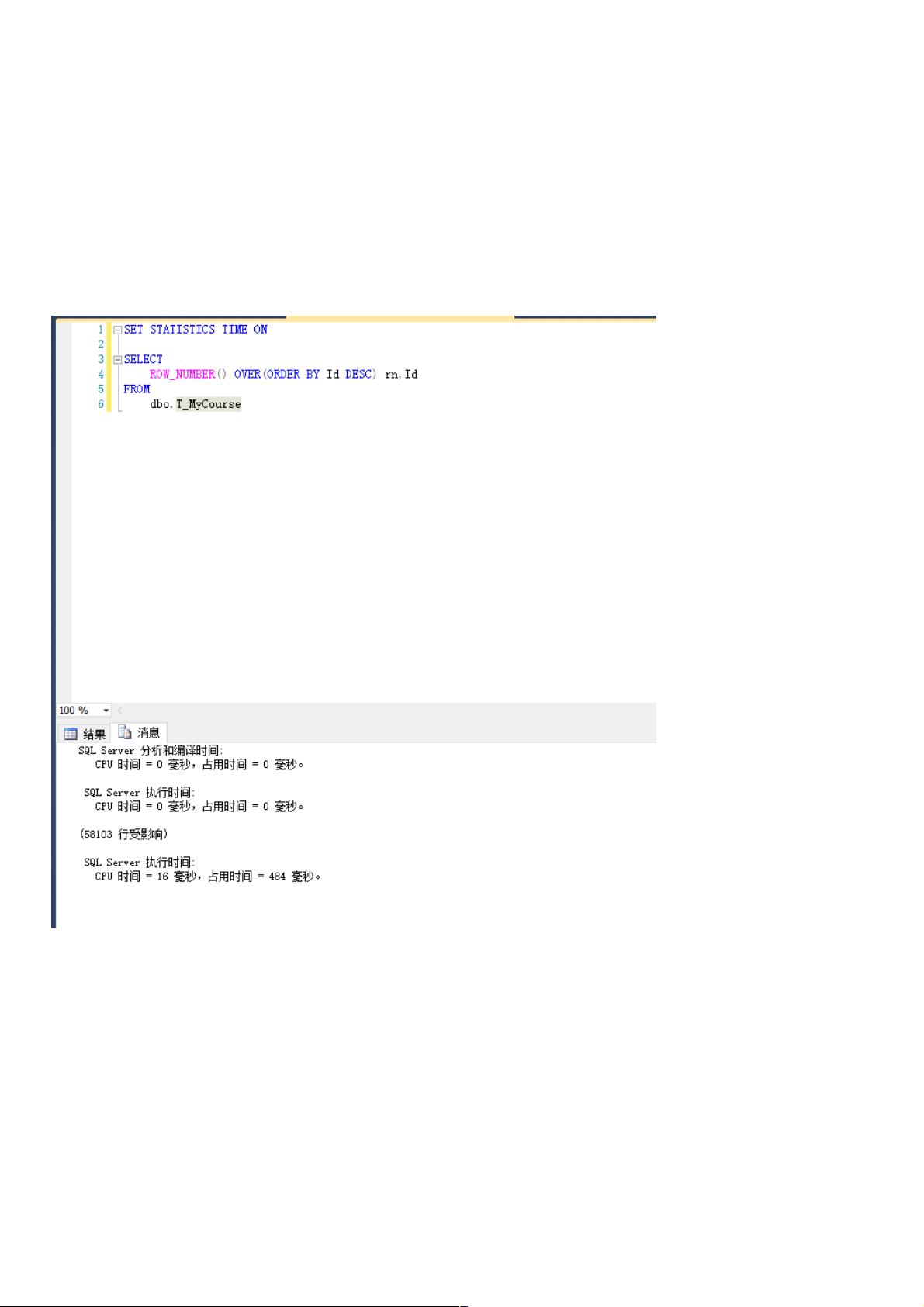
首先,ROW_NUMBER()函数是SQL Server中用于生成行号的标准方法。它会根据指定的排序规则为每一行赋予一个唯一的数字,常用于分页查询。例如:
```sql
SET STATISTICS TIME ON;
SELECT ROW_NUMBER() OVER (ORDER BY Id DESC) AS rn, Id
FROM dbo.T_MyCourse;
```
在这个例子中,`ROW_NUMBER()`函数按照`Id`字段降序排列,并为每一行生成行号。为了测试性能,作者清除了数据库缓存(使用`DBCC DROP CLEANBUFFERS`命令),然后执行了查询,记录了执行时间。
其次,文章提到了另一种分页编号的方法,即使用SUM(1) OVER(ORDER BY ... ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)。这种方法同样能生成行号,但它的计算方式略有不同:
```sql
SET STATISTICS TIME ON;
SELECT SUM(1) OVER (ORDER BY Id DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS rn, Id
FROM dbo.T_MyCourse;
```
尽管这两种方法都能实现分页,但在实际测试中,ROW_NUMBER()的分页查询性能优于使用SUM(1)的方案。当执行分页查询时(例如获取第55到444行),ROW_NUMBER()方法的执行时间明显更短。这可能是由于SQL Server对ROW_NUMBER()函数进行了优化,使其能够利用缓存来加速分页操作。
作者推测,ROW_NUMBER()在处理分页查询时可能有更高效的缓存策略,这使得在多次执行相同查询时,能够快速地从缓存中获取结果,而不是每次都重新计算。相比之下,SUM(1)方法在分页时可能不具有相同的优化,因此执行时间没有显著改善。
对于大型数据集的分页查询,ROW_NUMBER()是更为推荐的选择,尤其是在需要频繁进行分页操作的场景下。然而,具体选择哪种方法还应考虑实际的业务需求、数据规模以及服务器配置等因素。在进行性能调优时,理解这些细节可以帮助我们做出更明智的决策。
SQL Server 分页编号的另一种方式【推荐】分页编号的另一种方式【推荐】
今天看书讲T-SQL,看到了UNBOUNDED PRECEDING,就想比对下ROW_NUMBER()的运行速度。
sql及相关的结果如下,数据库中的数据有5W+。
ROW_NUMBER():
SET STATISTICS TIME ON
SELECT
ROW_NUMBER() OVER(ORDER BY Id DESC) rn,Id
FROM
dbo.T_MyCourse
运行结果
UNBOUNDED PRECEDING
SET STATISTICS TIME ON
SELECT
SUM(1) OVER(ORDER BY Id DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) rn,Id
FROM
dbo.T_MyCourse
运行结果
下载后可阅读完整内容,剩余4页未读,立即下载
107 浏览量
2009-07-12 上传
211 浏览量
点击了解资源详情
点击了解资源详情
102 浏览量
389 浏览量
2011-09-28 上传
117 浏览量

weixin_38693720
- 粉丝: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入解析ARM嵌入式Linux系统开发教程
- 精通JavaScript实例应用
- sndspec: 将声音文件转换为频谱图的工具
- 全技术栈蓝黄企业站模板(HTML源码+使用指南)
- OCaml实现蒙特卡罗模拟投资组合运行于网络工作者
- 实现TMS320F28069 LCD显示与可调PWM频率输出
- 《自动控制原理第三版》孙炳达课后答案解析
- 深入学习RHEL6下KVM虚拟化技术
- 基于混沌序列的Matlab数字图像加密技术详解
- NumMath开源软件:图形化数值计算与结果可视化
- 绿色大气个人摄影相册网站模板源码下载
- OpenOffice集成jar包:实现Word与PDF转换功能
- 雷达数字下变频MATLAB仿真技术研究
- PHP面向对象开发核心关键字深入解析
- Node.js中PostgreSQL咨询锁的实践与应用场景
- AIHelp WEB SDK代码示例及集成指南
