设计与实现:基于KNN算法的鸢尾花模式识别系统
需积分: 8 89 浏览量
更新于2024-08-04
收藏 505KB PDF 举报
"看我如何做基于最近邻算法模式识别系统的设计与实现"
本文档主要探讨了如何设计和实现一个基于K最近邻(K-Nearest Neighbor, KNN)算法的模式识别系统。KNN是一种非参数监督学习方法,常用于分类任务。它通过计算新样本与已知样本之间的距离来预测新样本的类别,遵循“物以类聚”的原则。
1.1 题目的主要研究内容
(1)工作描述
该系统设计的核心是运用KNN算法进行模式识别。KNN算法基于未知样本与已知样本集中的样本的相似度(通常用距离衡量)来预测新样本的类别。在这个项目中,首先进行了相关文献调研,通过知网、谷歌学术和知乎等平台深入学习KNN算法的基本原理和实现方法。然后,根据算法的逻辑,制定了程序的工作流程图,这将作为编程时的指南。最后,使用鸢尾花数据集进行训练和测试,数据集按7:3的比例划分为训练集和测试集,并使用Python语言在Pycharm环境中实现。
(2)系统流程
KNN算法的工作流程包括:加载鸢尾花数据集,拆分数据集,计算待分类样本与训练集中样本的欧氏距离,选择K个最近邻样本,确定合适的K值(通常通过交叉验证),并依据多数类别投票规则来预测新样本的类别。
1.2 工作基础或实验条件
硬件环境为Windows 10操作系统,软件环境为Pycharm编译器和Python编程语言,提供了实现KNN算法的必要工具和平台。
1.3 数据集描述
鸢尾花数据集是一个经典的数据集,常用于模式识别和机器学习的教学与实验。它包含三种不同类型的鸢尾花,每种花有四个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。这个数据集由Edgar Anderson测量,并在R.A. Fisher的文章中被引用,用于多变量分析的问题。
在实际操作中,KNN算法的性能受到数据预处理、特征选择、距离度量以及K值的影响。对于K值的选择,通常需要进行交叉验证以找到最佳值,以平衡模型的复杂性和泛化能力。此外,距离度量(如欧氏距离)的选择也会影响分类效果。在本项目中,欧氏距离被用作计算样本间相似性的标准。
通过理解KNN算法的基本原理,结合Python编程和鸢尾花数据集,可以构建一个有效的模式识别系统,实现对新样本的准确分类。这种系统不仅可以应用于鸢尾花分类,还可以扩展到其他领域,例如图像识别、文本分类等,只要数据可以量化为特征向量,KNN就能发挥其作用。
鸢尾花数据集最初由 Edgar Anderson 测量得到,而后在著名的统计学家和
生物学家 R.A Fisher 于 1936 年发表的文章「The use of multiple measurements in
taxonomic problems」中被使用,用其作为线性判别分析(Linear Discriminant
Analysis)的一个例子,证明分类的统计方法,从此而被众人所知,尤其是在机
器学习这个领域。
数据中的两类鸢尾花记录结果是在加拿大加斯帕半岛上,于同一天的同一
个时间段,使用相同的测量仪器,在相同的牧场上由同一个人测量出来的。这是
一份有着 70 年历史的数据,虽然老,但是却很经典,详细数据集可以在 UCI 数
据库中找到。
1.3.2 数据集详情
鸢尾花数据集包含 150 个数据样本,分为 3 类,即 Setosa 鸢尾花、Versicolour
鸢尾花和 Virginica 鸢尾花,每类 50 个数据,每个数据包含 4 个属性。可通过花
萼长度,花萼宽度,花瓣长度,花瓣宽度 4 个属性预测鸢尾花卉属于(Setosa,
Versicolour,Virginica)三个种类中的哪一类。四个属性的单位都是 cm,属于数
值变量,以下是鸢尾花数据集的部分数据。
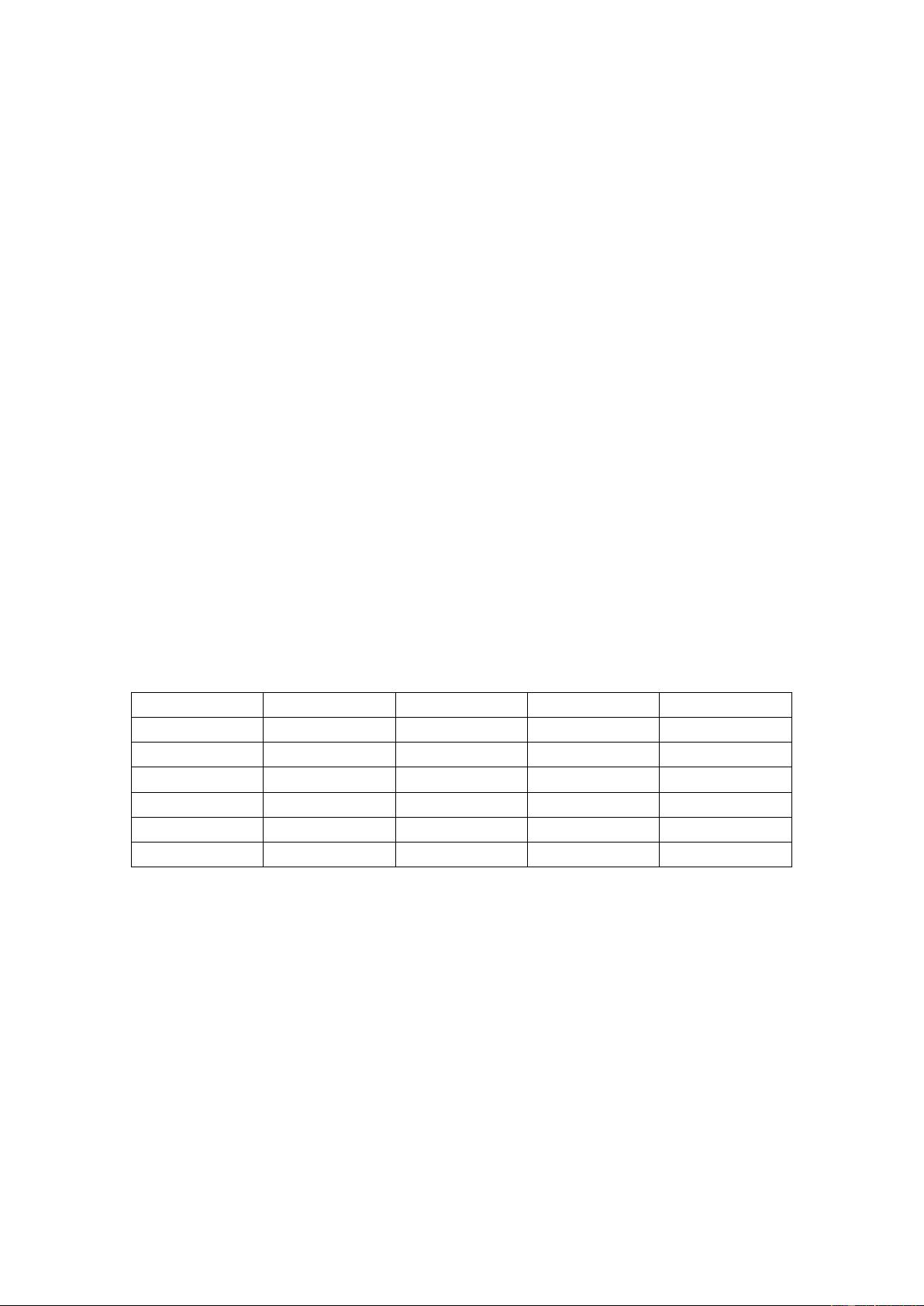
表 1 鸢尾花各属性统计值
类别
花萼长度
花萼宽度
花瓣长度
花瓣宽度
Iris-setosa
5.1
3.5
1.4
0.2
Iris-setosa
4.9
3.0
1.4
0.2
Iris-versicolor
7.0
3.2
4.7
1.4
Iris-versicolor
6.9
3.1
4.9
1.5
Iris-virginica
5.6
2.8
4.9
2.0
Iris-virginica
6.3
2.7
4.9
1.8
其中 Iris-setosa 即山鸢尾花,Iris-versicolor 为变色鸢尾花,Iris-virginica 为维
吉尼亚鸢尾花。每种不同类别的鸢尾花其对应的花萼长宽与花瓣长宽都会有差
异,可以通过四种属性的不同判断鸢尾花的种类。
1.4 特征提取过程描述
KNN 模式识别系统的特征提取主要分为计算距离和选取与未知样本距离最
近的 K 个已知样本。
(1)算距离:给定待分类样本,计算它与已分类样本中的每个样本的距离。
通常使用的距离函数有:欧氏距离、余弦距离、汉明距离、曼哈顿距离等,
剩余11页未读,继续阅读
2022-10-19 上传
2024-03-24 上传
2021-07-10 上传
2020-05-19 上传
2022-05-06 上传
2022-10-19 上传
2021-09-23 上传
2021-09-23 上传
2021-09-23 上传

李逍遥敲代码
- 粉丝: 2995
- 资源: 277
 我的内容管理
展开
我的内容管理
展开







最新资源
- A Tool For Automating Interactive Programs
- [时空译码-无线通讯技术]Space-Time Coding
- Drools4[1].0使用手册中文
- jstl标签使用详解
- study arm step by step.pdf
- Android.A.Programmers.Guide
- Thinking In Java 3rd Edition中文版
- Pro Ajax and Java 英文版 (pdf)
- ejb3.0实例教程
- 硬盘安装linux操作系统
- Oracle 9i10g编程艺术中文版
- JRuby on Rails 英文版 (pdf)
- AT89S52-CN
- Beginning Spring 2 From Novice to Professional 英文版 (pdf)
- java面试100题目
- vtk教程 很好的教程
