"Hive伪分布式部署与配置指南详解"
需积分: 2 14 浏览量
更新于2024-01-12
收藏 1.83MB DOCX 举报
数据仓库Hive是一个基于Hadoop的数据仓库工具,可以方便地进行大数据分析和查询。本文将介绍如何在伪分布式环境下部署和配置Hive,并进行简单的应用。
首先,我们需要下载并解压Hive的源程序。通过以下命令可以完成此步骤:
```bash
tar zxvf apache-hive-1.2.1-bin.tar.gz
mv apache-hive-1.2.1-bin hive
sudo mv hive/ /opt/
```
接着,我们需要配置环境变量,以便系统能够找到Hive的安装路径。通过编辑.bashrc文件并执行source命令,可以完成此步骤:
```bash
vim .bashrc
source .bashrc
```
然后,我们需要对Hive进行配置。首先进入Hive的配置目录,然后编辑hive-site.xml文件并添加相关配置:
```bash
cd /opt/hive/
cd conf/
vim hive-site.xml
```
在hive-site.xml中,我们需要添加以下内容:
```xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<!-- 其他配置 -->
</configuration>
```
以上就是Hive的伪分布式部署和配置过程。一旦配置完成,就可以启动Hive并进行相关的数据仓库操作了。
在使用Hive进行数据仓库操作时,可以通过HiveQL语言来完成,类似于SQL语言。用户可以通过HiveQL来创建数据库、表,加载数据,以及进行各种查询和分析操作。
总的来说,数据仓库Hive的伪分布式部署和应用过程比较简单,只需按照上述步骤进行配置即可。配置完成后,就可以通过HiveQL语言进行各种数据仓库操作,为大数据分析提供了便利的工具和平台。
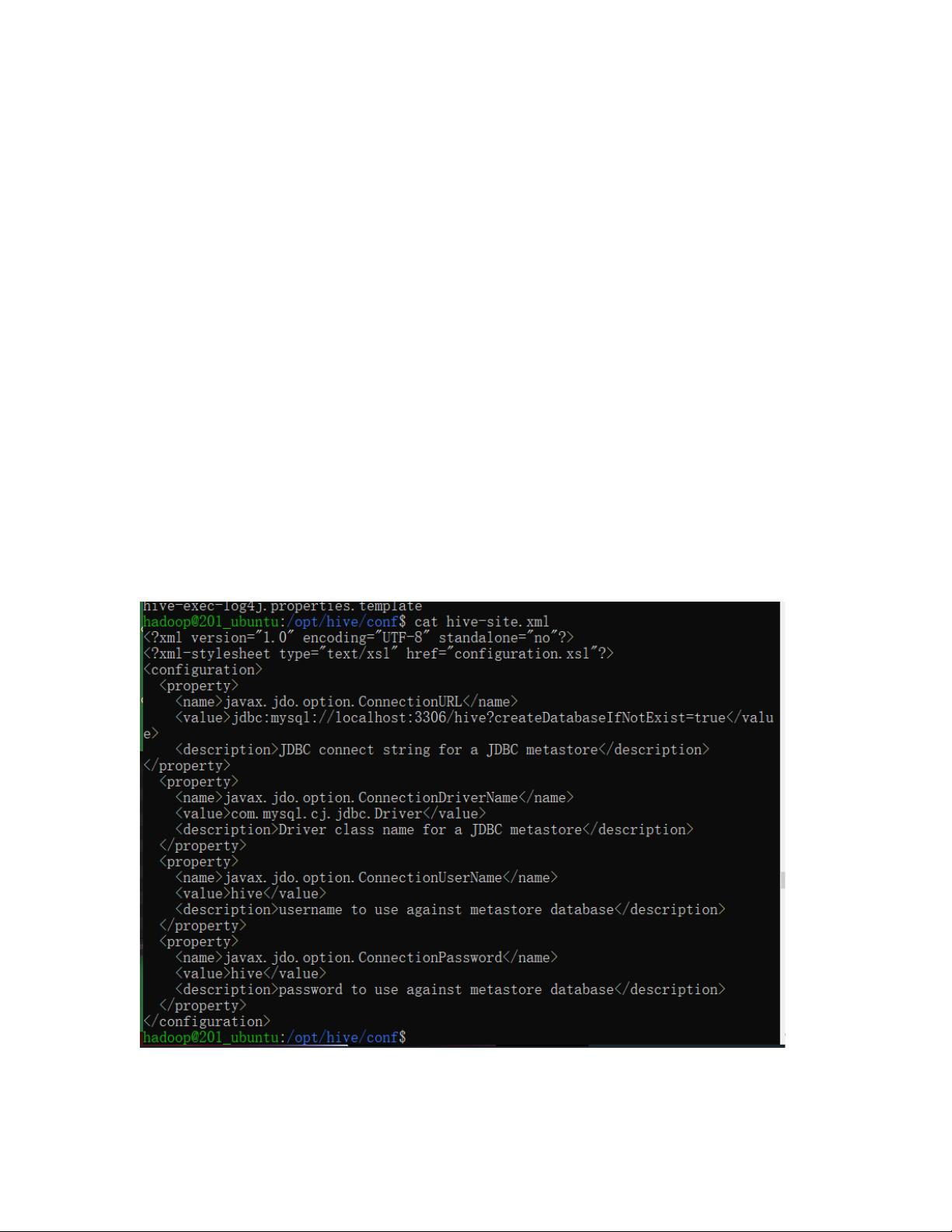
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
</configuration>
8.2.2 安装配置 MySQL,连接 Hive 元数据库
剩余17页未读,继续阅读
2017-11-08 上传
2020-03-23 上传
2021-06-06 上传
2022-12-09 上传
2021-06-12 上传
2023-10-26 上传
2020-03-14 上传
2023-06-27 上传

肉肉肉肉肉肉~丸子
- 粉丝: 286
- 资源: 157
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
